 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieving Any Relevant Moments: Benchmark and Models for Generalized Moment Retrieval
May 04, 2026Video Moment Retrieval (VMR) aims to localize temporal segments in videos that correspond to a natural language query, but typically assumes only a single matching moment for each query. This assumption does not always hold in real-world scenarios, where queries may correspond to multiple or no moments. Thus, we formulate Generalized Moment Retrieval (GMR), a unified setting that requires retrieving the complete set of relevant moments or predicting an empty set. To enable systematic study of GMR, we introduce Soccer-GMR, a large-scale benchmark built on challenging soccer videos that reflect general GMR scenarios, with realistic negative and positive queries. The benchmark is constructed via a duration-flexible semi-automated pipeline with human verification, enabling scalable data generation while maintaining high annotation quality. We further design a unified evaluation protocol with complementary metrics tailored for null-set rejection, positive-query localization, and end-to-end GMR performance. Finally, we establish strong baselines across two modeling paradigms: a lightweight plug-and-play GMR adapter for discriminative VMR models, and a GMR-tailored GRPO reward for fine-tuning multimodal large language models (MLLMs). Extensive experiments show consistent gains across all metrics and expose key limitations of current methods, positioning GMR as a more realistic and challenging benchmark for video-language understanding.
ShotFinder: Imagination-Driven Open-Domain Video Shot Retrieval via Web Search
Jan 30, 2026In recent years, large language models (LLMs) have made rapid progress in information retrieval, yet existing research has mainly focused on text or static multimodal settings. Open-domain video shot retrieval, which involves richer temporal structure and more complex semantics, still lacks systematic benchmarks and analysis. To fill this gap, we introduce ShotFinder, a benchmark that formalizes editing requirements as keyframe-oriented shot descriptions and introduces five types of controllable single-factor constraints: Temporal order, Color, Visual style, Audio, and Resolution. We curate 1,210 high-quality samples from YouTube across 20 thematic categories, using large models for generation with human verification. Based on the benchmark, we propose ShotFinder, a text-driven three-stage retrieval and localization pipeline: (1) query expansion via video imagination, (2) candidate video retrieval with a search engine, and (3) description-guided temporal localization. Experiments on multiple closed-source and open-source models reveal a significant gap to human performance, with clear imbalance across constraints: temporal localization is relatively tractable, while color and visual style remain major challenges. These results reveal that open-domain video shot retrieval is still a critical capability that multimodal large models have yet to overcome.
HPL-ESS: Hybrid Pseudo-Labeling for Unsupervised Event-based Semantic Segmentation
Mar 25, 2024



Event-based semantic segmentation has gained popularity due to its capability to deal with scenarios under high-speed motion and extreme lighting conditions, which cannot be addressed by conventional RGB cameras. Since it is hard to annotate event data, previous approaches rely on event-to-image reconstruction to obtain pseudo labels for training. However, this will inevitably introduce noise, and learning from noisy pseudo labels, especially when generated from a single source, may reinforce the errors. This drawback is also called confirmation bias in pseudo-labeling. In this paper, we propose a novel hybrid pseudo-labeling framework for unsupervised event-based semantic segmentation, HPL-ESS, to alleviate the influence of noisy pseudo labels. In particular, we first employ a plain unsupervised domain adaptation framework as our baseline, which can generate a set of pseudo labels through self-training. Then, we incorporate offline event-to-image reconstruction into the framework, and obtain another set of pseudo labels by predicting segmentation maps on the reconstructed images. A noisy label learning strategy is designed to mix the two sets of pseudo labels and enhance the quality. Moreover, we propose a soft prototypical alignment module to further improve the consistency of target domain features. Extensive experiments show that our proposed method outperforms existing state-of-the-art methods by a large margin on the DSEC-Semantic dataset (+5.88% accuracy, +10.32% mIoU), which even surpasses several supervised methods.
FairSync: Ensuring Amortized Group Exposure in Distributed Recommendation Retrieval
Feb 16, 2024In pursuit of fairness and balanced development, recommender systems (RS) often prioritize group fairness, ensuring that specific groups maintain a minimum level of exposure over a given period. For example, RS platforms aim to ensure adequate exposure for new providers or specific categories of items according to their needs. Modern industry RS usually adopts a two-stage pipeline: stage-1 (retrieval stage) retrieves hundreds of candidates from millions of items distributed across various servers, and stage-2 (ranking stage) focuses on presenting a small-size but accurate selection from items chosen in stage-1. Existing efforts for ensuring amortized group exposures focus on stage-2, however, stage-1 is also critical for the task. Without a high-quality set of candidates, the stage-2 ranker cannot ensure the required exposure of groups. Previous fairness-aware works designed for stage-2 typically require accessing and traversing all items. In stage-1, however, millions of items are distributively stored in servers, making it infeasible to traverse all of them. How to ensure group exposures in the distributed retrieval process is a challenging question. To address this issue, we introduce a model named FairSync, which transforms the problem into a constrained distributed optimization problem. Specifically, FairSync resolves the issue by moving it to the dual space, where a central node aggregates historical fairness data into a vector and distributes it to all servers. To trade off the efficiency and accuracy, the gradient descent technique is used to periodically update the parameter of the dual vector. The experiment results on two public recommender retrieval datasets showcased that FairSync outperformed all the baselines, achieving the desired minimum level of exposures while maintaining a high level of retrieval accuracy.
Mutual Information Maximization for Robust Plannable Representations
May 16, 2020
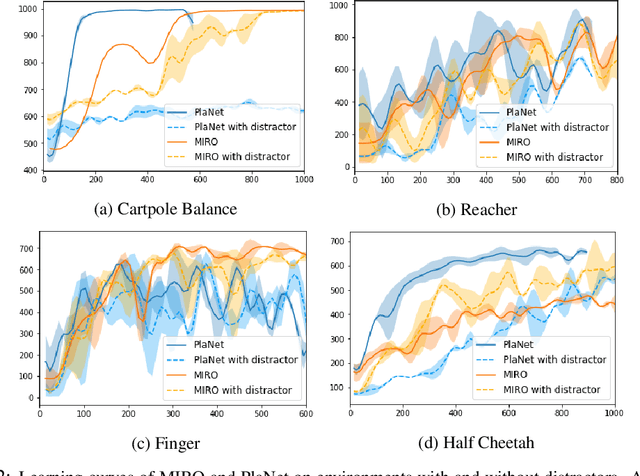
Extending the capabilities of robotics to real-world complex, unstructured environments requires the need of developing better perception systems while maintaining low sample complexity. When dealing with high-dimensional state spaces, current methods are either model-free or model-based based on reconstruction objectives. The sample inefficiency of the former constitutes a major barrier for applying them to the real-world. The later, while they present low sample complexity, they learn latent spaces that need to reconstruct every single detail of the scene. In real environments, the task typically just represents a small fraction of the scene. Reconstruction objectives suffer in such scenarios as they capture all the unnecessary components. In this work, we present MIRO, an information theoretic representational learning algorithm for model-based reinforcement learning. We design a latent space that maximizes the mutual information with the future information while being able to capture all the information needed for planning. We show that our approach is more robust than reconstruction objectives in the presence of distractors and cluttered scenes
REFIT: a Unified Watermark Removal Framework for Deep Learning Systems with Limited Data
Nov 17, 2019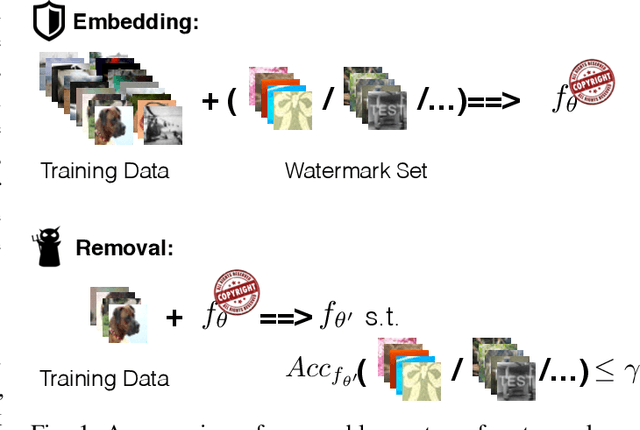
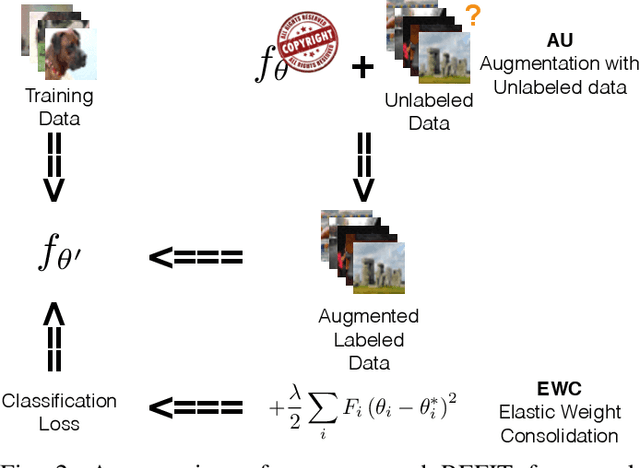
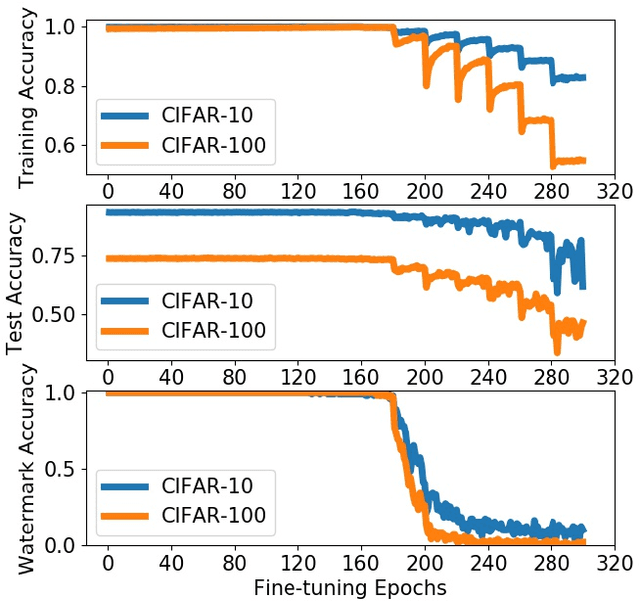

Deep neural networks (DNNs) have achieved tremendous success in various fields; however, training these models from scratch could be computationally expensive and requires a lot of training data. Recent work has explored different watermarking techniques to protect the pre-trained deep neural networks from potential copyright infringements; however, they could be vulnerable to adversaries who aim at removing the watermarks. In this work, we propose REFIT, a unified watermark removal framework based on fine-tuning, which does not rely on the knowledge of the watermarks and even the watermarking schemes. Firstly, we demonstrate that by properly designing the learning rate schedule for fine-tuning, an adversary is always able to remove the watermarks. Furthermore, we conduct a comprehensive study of a realistic attack scenario where the adversary has limited training data. To effectively remove the watermarks without compromising the model functionality under this weak threat model, we propose to incorporate two techniques: (1) an adaption of the elastic weight consolidation (EWC) algorithm, which is originally proposed for mitigating the catastrophic forgetting phenomenon; and (2) unlabeled data augmentation (AU), where we leverage auxiliary unlabeled data from other sources. Our extensive evaluation shows the effectiveness of REFIT against diverse watermark embedding schemes. In particular, both EWC and AU significantly decrease the amount of labeled training data needed for effective watermark removal, and the unlabeled data samples used for AU do not necessarily need to be drawn from the same distribution as the benign data for model evaluation. The experimental results demonstrate that our fine-tuning based watermark removal attacks could pose real threats to the copyright of pre-trained models, and thus highlights the importance of further investigation of the watermarking problem.
Goal-conditioned Imitation Learning
Jun 13, 2019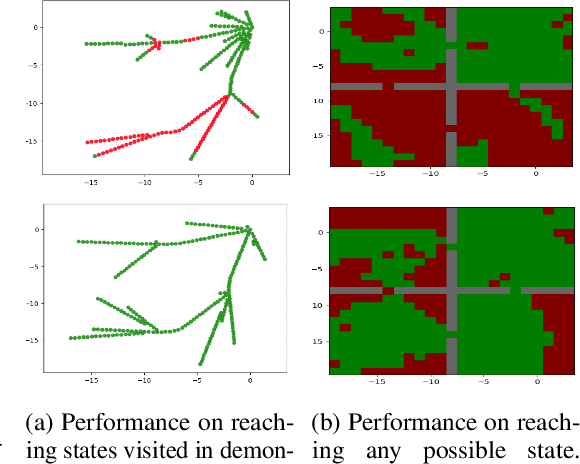

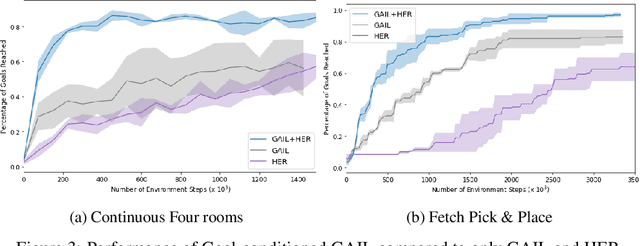
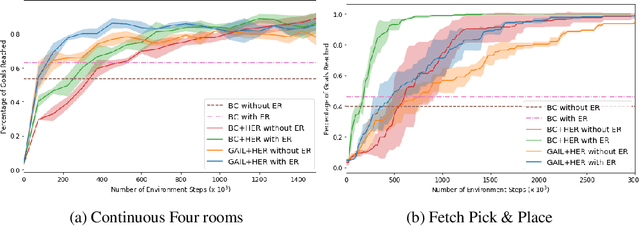
Designing rewards for Reinforcement Learning (RL) is challenging because it needs to convey the desired task, be efficient to optimize, and be easy to compute. The latter is particularly problematic when applying RL to robotics, where detecting whether the desired configuration is reached might require considerable supervision and instrumentation. Furthermore, we are often interested in being able to reach a wide range of configurations, hence setting up a different reward every time might be unpractical. Methods like Hindsight Experience Replay (HER) have recently shown promise to learn policies able to reach many goals, without the need of a reward. Unfortunately, without tricks like resetting to points along the trajectory, HER might take a very long time to discover how to reach certain areas of the state-space. In this work we investigate different approaches to incorporate demonstrations to drastically speed up the convergence to a policy able to reach any goal, also surpassing the performance of an agent trained with other Imitation Learning algorithms. Furthermore, our method can be used when only trajectories without expert actions are available, which can leverage kinestetic or third person demonstration. The code is available at https://sites.google.com/view/goalconditioned-il/ .
Equitability of Dependence Measure
Jul 11, 2018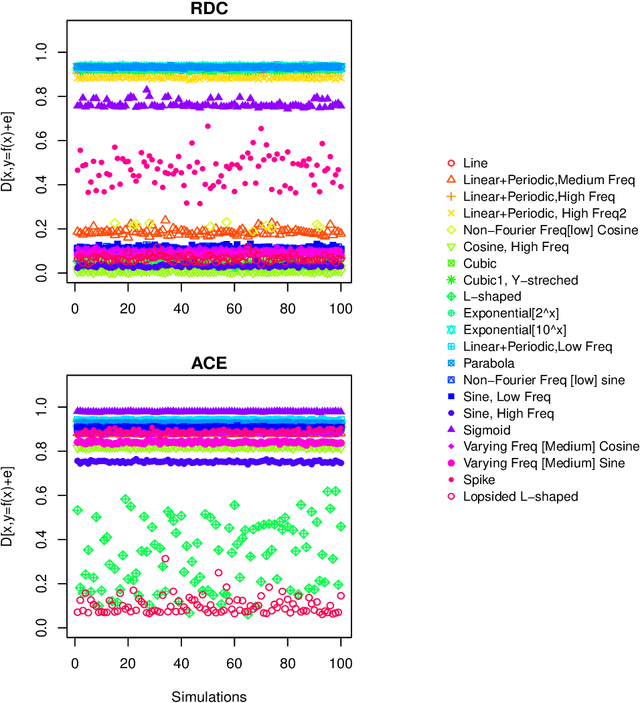
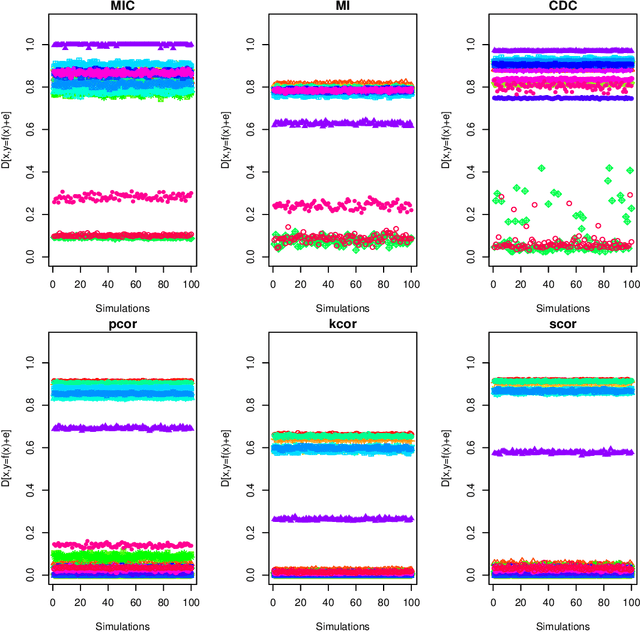
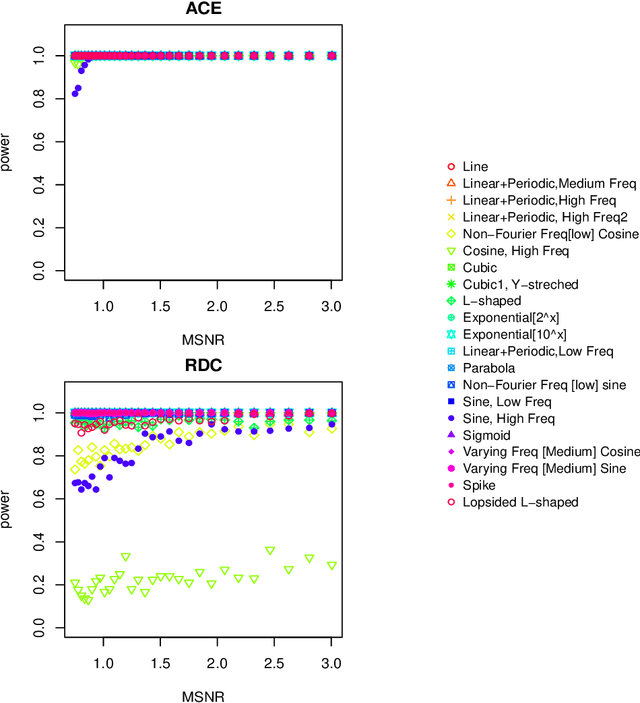
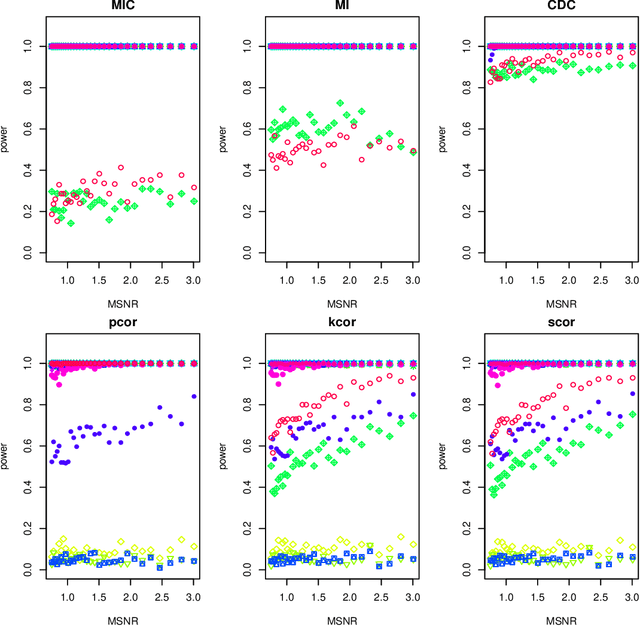
Measuring dependence between two random variables is very important, and critical in many applied areas such as variable selection, brain network analysis. However, we do not know what kind of functional relationship is between two covariates, which requires the dependence measure to be equitable. That is, it gives similar scores to equally noisy relationship of different types. In fact, the dependence score is a continuous random variable taking values in $[0,1]$, thus it is theoretically impossible to give similar scores. In this paper, we introduce a new definition of equitability of a dependence measure, i.e, power-equitable (weak-equitable) and show by simulation that HHG and Copula Dependence Coefficient (CDC) are weak-equitable.
Dependence Measure for non-additive model
Mar 25, 2018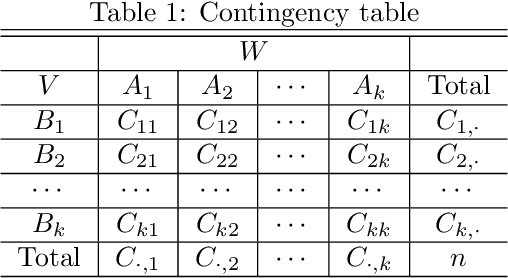

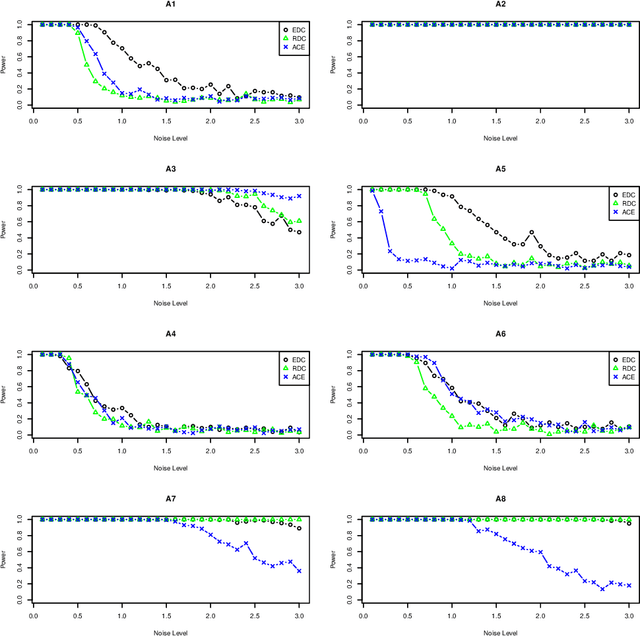
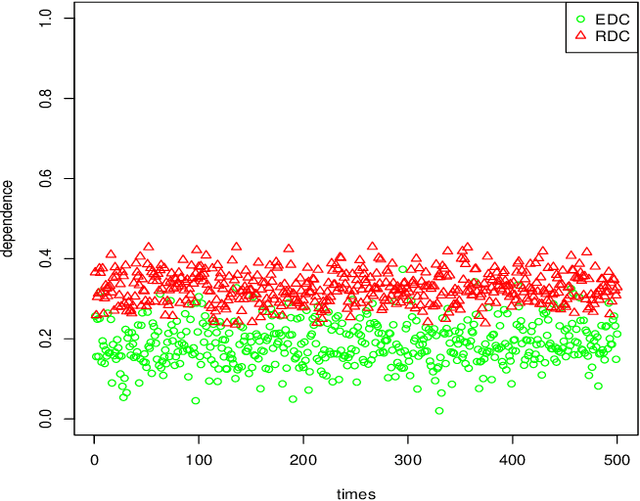
We proposed a new statistical dependency measure called Copula Dependency Coefficient(CDC) for two sets of variables based on copula. It is robust to outliers, easy to implement, powerful and appropriate to high-dimensional variables. These properties are important in many applications. Experimental results show that CDC can detect the dependence between variables in both additive and non-additive models.