 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Mutual-Information Representation Learning Objectives are Sufficient for Control?
Jun 14, 2021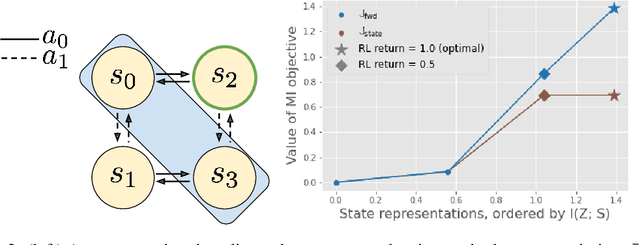
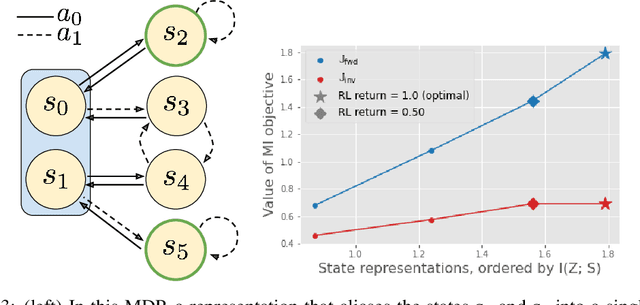
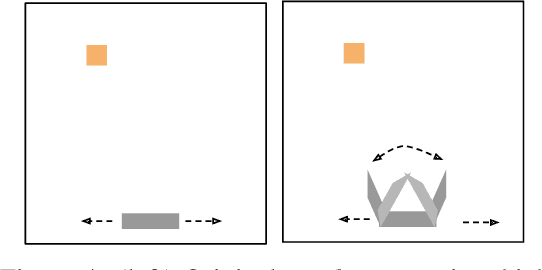
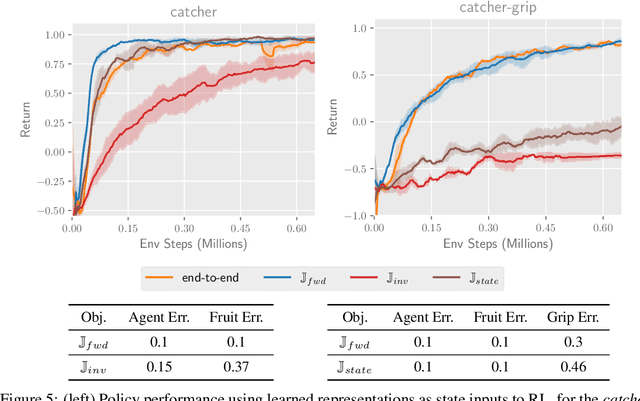
Mutual information maximization provides an appealing formalism for learning representations of data. In the context of reinforcement learning (RL), such representations can accelerate learning by discarding irrelevant and redundant information, while retaining the information necessary for control. Much of the prior work on these methods has addressed the practical difficulties of estimating mutual information from samples of high-dimensional observations, while comparatively less is understood about which mutual information objectives yield representations that are sufficient for RL from a theoretical perspective. In this paper, we formalize the sufficiency of a state representation for learning and representing the optimal policy, and study several popular mutual-information based objectives through this lens. Surprisingly, we find that two of these objectives can yield insufficient representations given mild and common assumptions on the structure of the MDP. We corroborate our theoretical results with empirical experiments on a simulated game environment with visual observations.
Guided Uncertainty-Aware Policy Optimization: Combining Learning and Model-Based Strategies for Sample-Efficient Policy Learning
May 26, 2020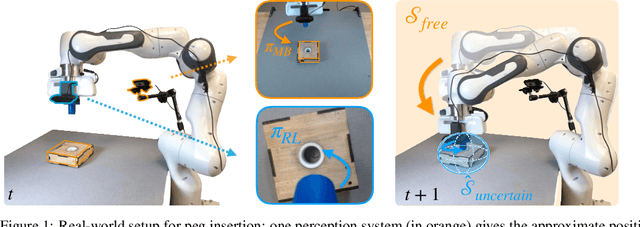
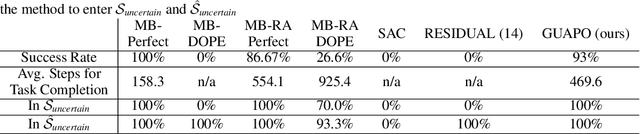
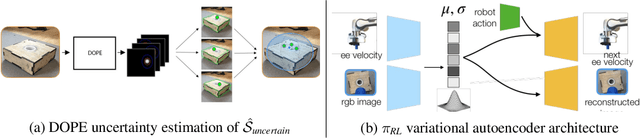
Traditional robotic approaches rely on an accurate model of the environment, a detailed description of how to perform the task, and a robust perception system to keep track of the current state. On the other hand, reinforcement learning approaches can operate directly from raw sensory inputs with only a reward signal to describe the task, but are extremely sample-inefficient and brittle. In this work, we combine the strengths of model-based methods with the flexibility of learning-based methods to obtain a general method that is able to overcome inaccuracies in the robotics perception/actuation pipeline, while requiring minimal interactions with the environment. This is achieved by leveraging uncertainty estimates to divide the space in regions where the given model-based policy is reliable, and regions where it may have flaws or not be well defined. In these uncertain regions, we show that a locally learned-policy can be used directly with raw sensory inputs. We test our algorithm, Guided Uncertainty-Aware Policy Optimization (GUAPO), on a real-world robot performing peg insertion. Videos are available at https://sites.google.com/view/guapo-rl
Goal-conditioned Imitation Learning
Jun 13, 2019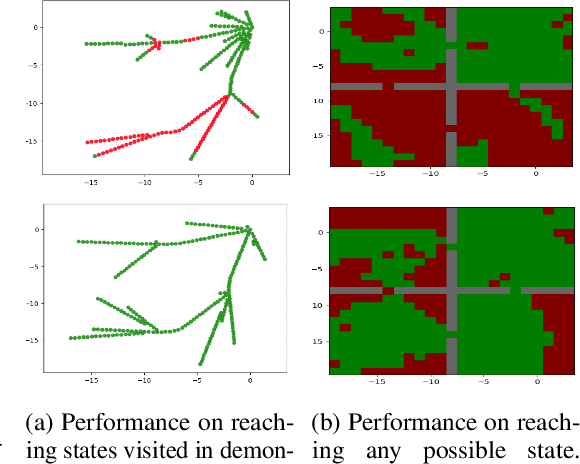

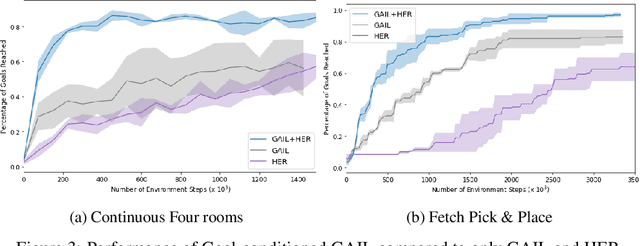
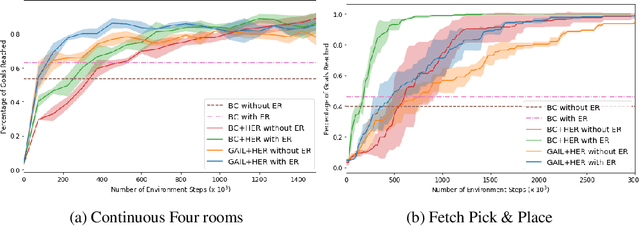
Designing rewards for Reinforcement Learning (RL) is challenging because it needs to convey the desired task, be efficient to optimize, and be easy to compute. The latter is particularly problematic when applying RL to robotics, where detecting whether the desired configuration is reached might require considerable supervision and instrumentation. Furthermore, we are often interested in being able to reach a wide range of configurations, hence setting up a different reward every time might be unpractical. Methods like Hindsight Experience Replay (HER) have recently shown promise to learn policies able to reach many goals, without the need of a reward. Unfortunately, without tricks like resetting to points along the trajectory, HER might take a very long time to discover how to reach certain areas of the state-space. In this work we investigate different approaches to incorporate demonstrations to drastically speed up the convergence to a policy able to reach any goal, also surpassing the performance of an agent trained with other Imitation Learning algorithms. Furthermore, our method can be used when only trajectories without expert actions are available, which can leverage kinestetic or third person demonstration. The code is available at https://sites.google.com/view/goalconditioned-il/ .
Sub-policy Adaptation for Hierarchical Reinforcement Learning
Jun 13, 2019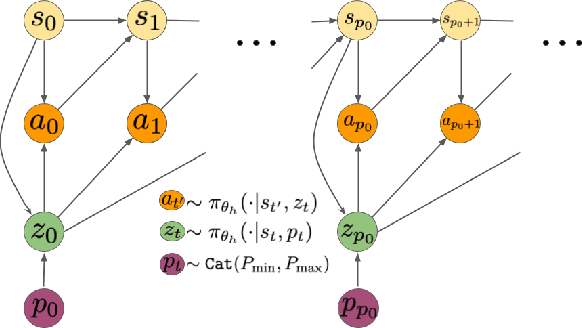
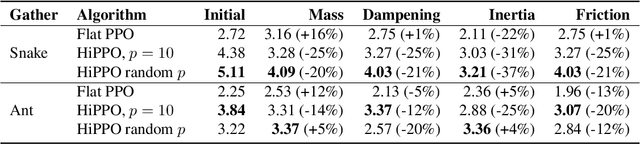
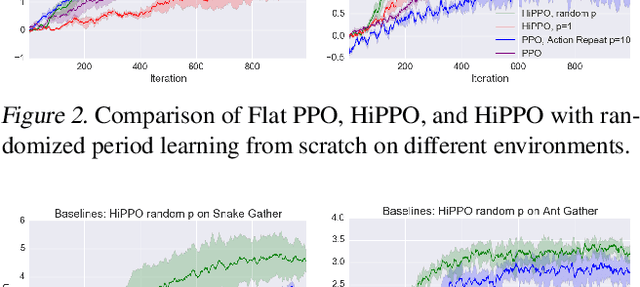
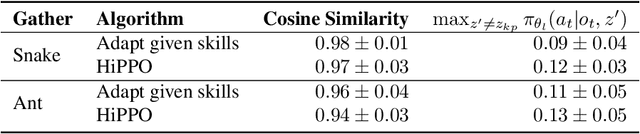
Hierarchical Reinforcement Learning is a promising approach to long-horizon decision-making problems with sparse rewards. Unfortunately, most methods still decouple the lower-level skill acquisition process and the training of a higher level that controls the skills in a new task. Treating the skills as fixed can lead to significant sub-optimality in the transfer setting. In this work, we propose a novel algorithm to discover a set of skills, and continuously adapt them along with the higher level even when training on a new task. Our main contributions are two-fold. First, we derive a new hierarchical policy gradient, as well as an unbiased latent-dependent baseline. We introduce Hierarchical Proximal Policy Optimization (HiPPO), an on-policy method to efficiently train all levels of the hierarchy simultaneously. Second, we propose a method of training time-abstractions that improves the robustness of the obtained skills to environment changes. Code and results are available at sites.google.com/view/hippo-rl .
Adaptive Variance for Changing Sparse-Reward Environments
Mar 15, 2019
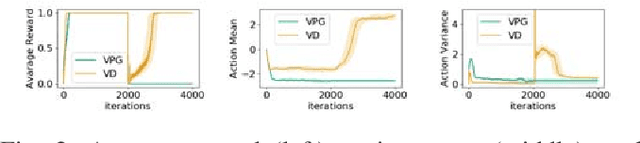
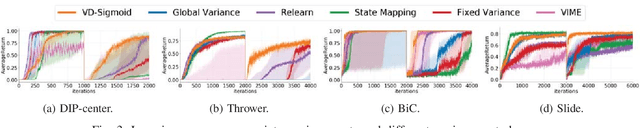

Robots that are trained to perform a task in a fixed environment often fail when facing unexpected changes to the environment due to a lack of exploration. We propose a principled way to adapt the policy for better exploration in changing sparse-reward environments. Unlike previous works which explicitly model environmental changes, we analyze the relationship between the value function and the optimal exploration for a Gaussian-parameterized policy and show that our theory leads to an effective strategy for adjusting the variance of the policy, enabling fast adapt to changes in a variety of sparse-reward environments.
Self-supervised Learning of Image Embedding for Continuous Control
Jan 03, 2019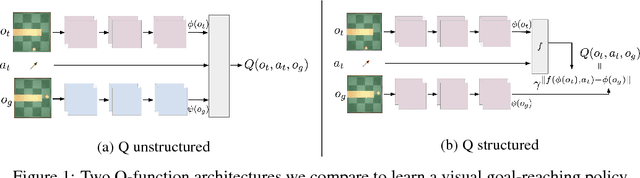
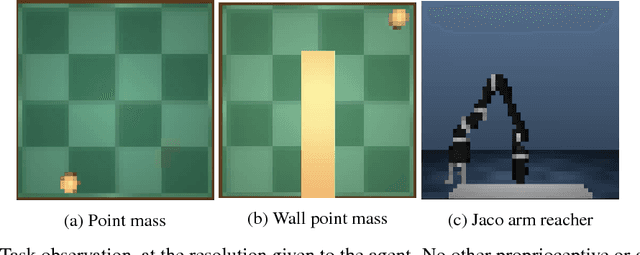
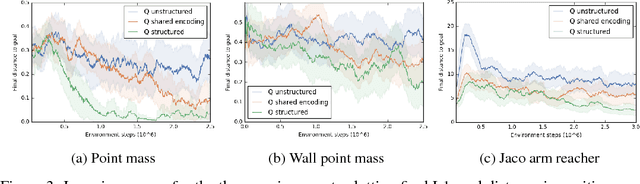
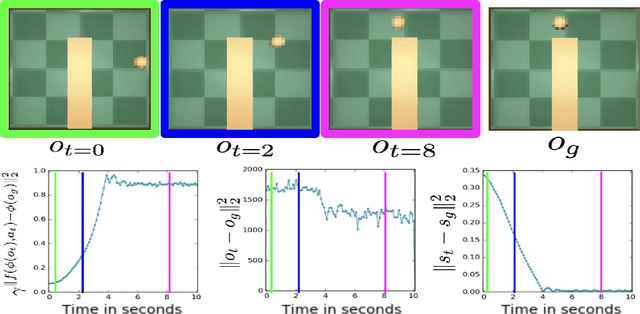
Operating directly from raw high dimensional sensory inputs like images is still a challenge for robotic control. Recently, Reinforcement Learning methods have been proposed to solve specific tasks end-to-end, from pixels to torques. However, these approaches assume the access to a specified reward which may require specialized instrumentation of the environment. Furthermore, the obtained policy and representations tend to be task specific and may not transfer well. In this work we investigate completely self-supervised learning of a general image embedding and control primitives, based on finding the shortest time to reach any state. We also introduce a new structure for the state-action value function that builds a connection between model-free and model-based methods, and improves the performance of the learning algorithm. We experimentally demonstrate these findings in three simulated robotic tasks.
Reverse Curriculum Generation for Reinforcement Learning
Jul 23, 2018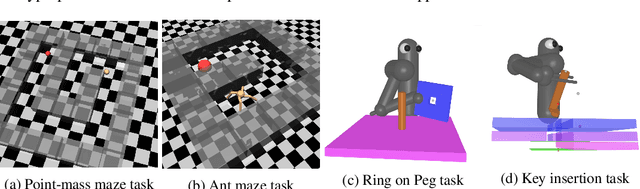
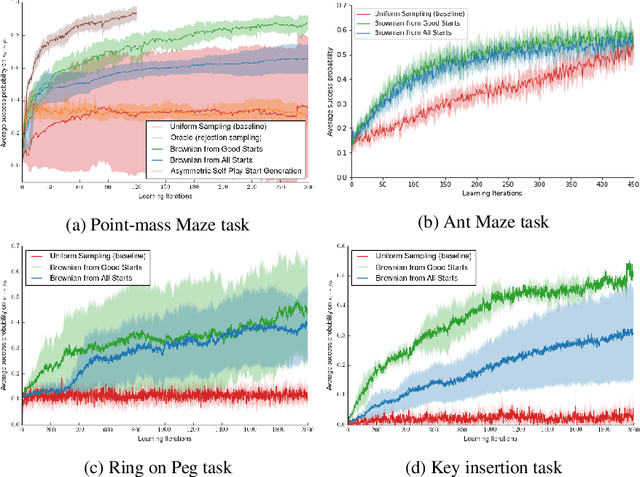
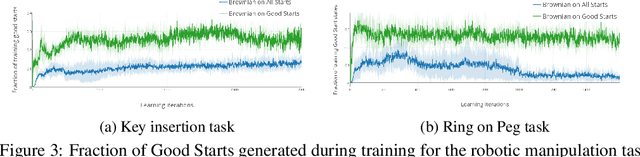
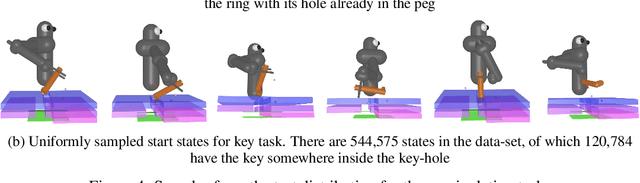
Many relevant tasks require an agent to reach a certain state, or to manipulate objects into a desired configuration. For example, we might want a robot to align and assemble a gear onto an axle or insert and turn a key in a lock. These goal-oriented tasks present a considerable challenge for reinforcement learning, since their natural reward function is sparse and prohibitive amounts of exploration are required to reach the goal and receive some learning signal. Past approaches tackle these problems by exploiting expert demonstrations or by manually designing a task-specific reward shaping function to guide the learning agent. Instead, we propose a method to learn these tasks without requiring any prior knowledge other than obtaining a single state in which the task is achieved. The robot is trained in reverse, gradually learning to reach the goal from a set of start states increasingly far from the goal. Our method automatically generates a curriculum of start states that adapts to the agent's performance, leading to efficient training on goal-oriented tasks. We demonstrate our approach on difficult simulated navigation and fine-grained manipulation problems, not solvable by state-of-the-art reinforcement learning methods.
Automatic Goal Generation for Reinforcement Learning Agents
Jul 23, 2018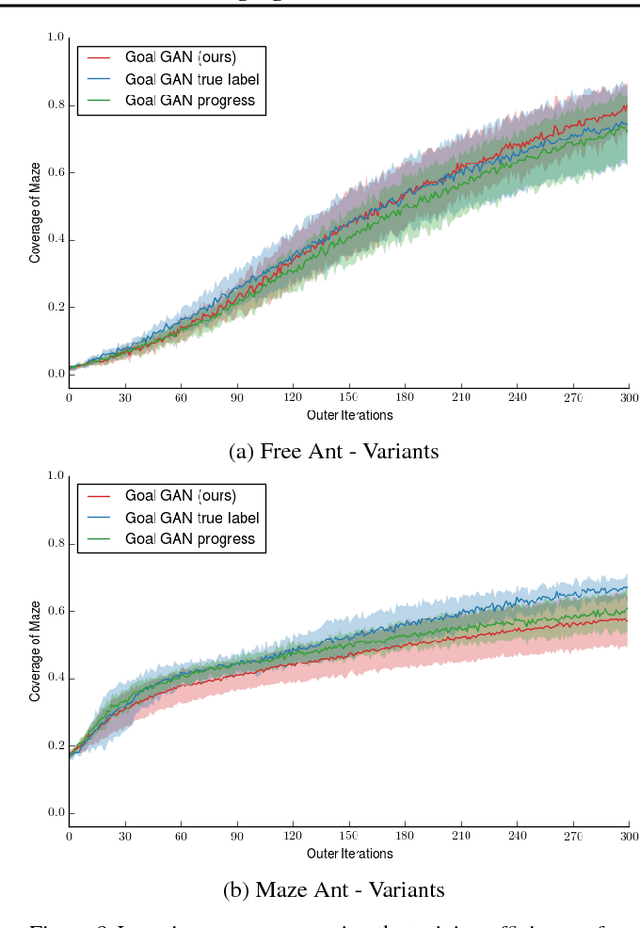
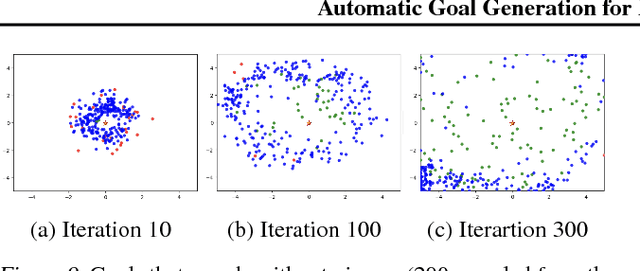
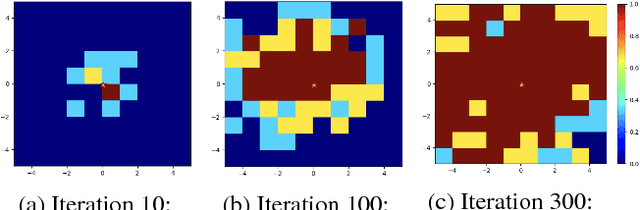
Reinforcement learning is a powerful technique to train an agent to perform a task. However, an agent that is trained using reinforcement learning is only capable of achieving the single task that is specified via its reward function. Such an approach does not scale well to settings in which an agent needs to perform a diverse set of tasks, such as navigating to varying positions in a room or moving objects to varying locations. Instead, we propose a method that allows an agent to automatically discover the range of tasks that it is capable of performing. We use a generator network to propose tasks for the agent to try to achieve, specified as goal states. The generator network is optimized using adversarial training to produce tasks that are always at the appropriate level of difficulty for the agent. Our method thus automatically produces a curriculum of tasks for the agent to learn. We show that, by using this framework, an agent can efficiently and automatically learn to perform a wide set of tasks without requiring any prior knowledge of its environment. Our method can also learn to achieve tasks with sparse rewards, which traditionally pose significant challenges.
Stochastic Neural Networks for Hierarchical Reinforcement Learning
Apr 10, 2017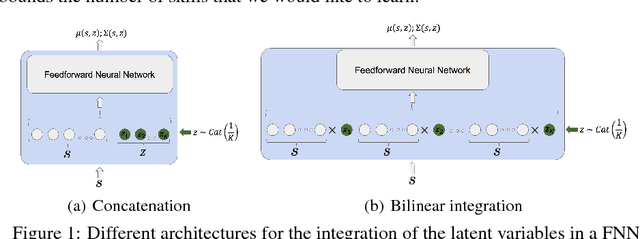
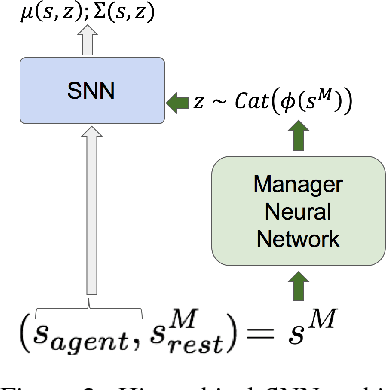

Deep reinforcement learning has achieved many impressive results in recent years. However, tasks with sparse rewards or long horizons continue to pose significant challenges. To tackle these important problems, we propose a general framework that first learns useful skills in a pre-training environment, and then leverages the acquired skills for learning faster in downstream tasks. Our approach brings together some of the strengths of intrinsic motivation and hierarchical methods: the learning of useful skill is guided by a single proxy reward, the design of which requires very minimal domain knowledge about the downstream tasks. Then a high-level policy is trained on top of these skills, providing a significant improvement of the exploration and allowing to tackle sparse rewards in the downstream tasks. To efficiently pre-train a large span of skills, we use Stochastic Neural Networks combined with an information-theoretic regularizer. Our experiments show that this combination is effective in learning a wide span of interpretable skills in a sample-efficient way, and can significantly boost the learning performance uniformly across a wide range of downstream tasks.
* Published as a conference paper at ICLR 2017