 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Learning of Image Embedding for Continuous Control
Paper and Code
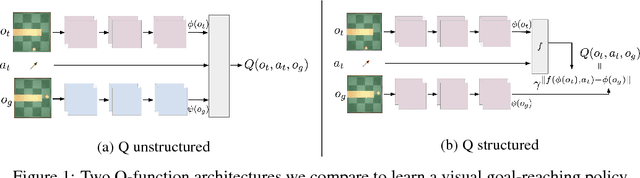
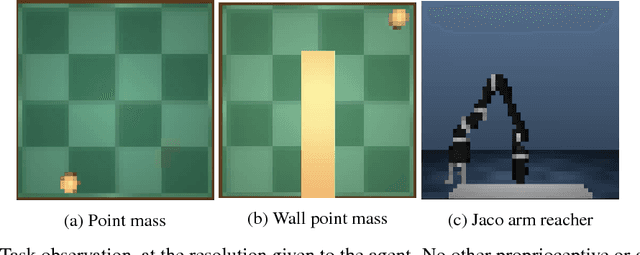
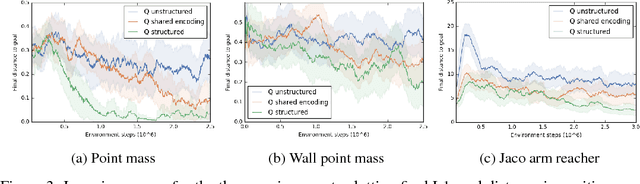
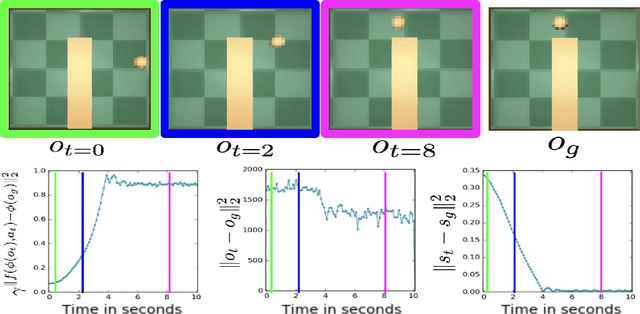
Operating directly from raw high dimensional sensory inputs like images is still a challenge for robotic control. Recently, Reinforcement Learning methods have been proposed to solve specific tasks end-to-end, from pixels to torques. However, these approaches assume the access to a specified reward which may require specialized instrumentation of the environment. Furthermore, the obtained policy and representations tend to be task specific and may not transfer well. In this work we investigate completely self-supervised learning of a general image embedding and control primitives, based on finding the shortest time to reach any state. We also introduce a new structure for the state-action value function that builds a connection between model-free and model-based methods, and improves the performance of the learning algorithm. We experimentally demonstrate these findings in three simulated robotic tasks.