 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiBench: Multiscale Benchmarks for Multimodal Representation Learning
Jul 15, 2021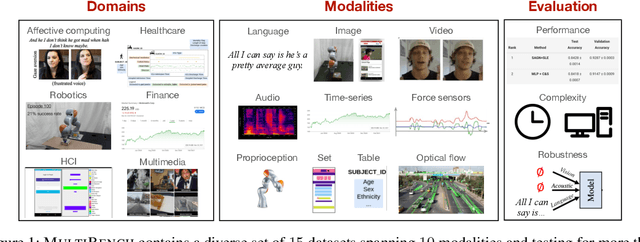
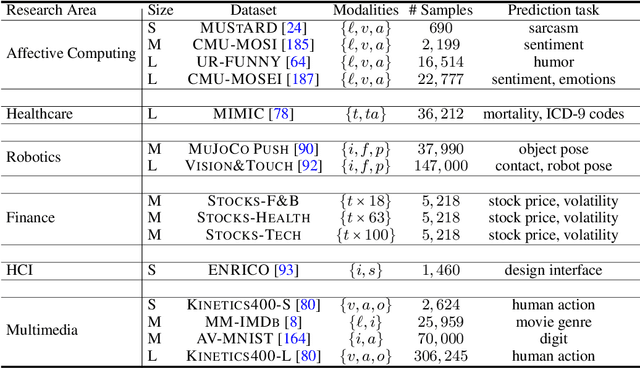
Learning multimodal representations involves integrating information from multiple heterogeneous sources of data. It is a challenging yet crucial area with numerous real-world applications in multimedia, affective computing, robotics, finance, human-computer interaction, and healthcare. Unfortunately, multimodal research has seen limited resources to study (1) generalization across domains and modalities, (2) complexity during training and inference, and (3) robustness to noisy and missing modalities. In order to accelerate progress towards understudied modalities and tasks while ensuring real-world robustness, we release MultiBench, a systematic and unified large-scale benchmark spanning 15 datasets, 10 modalities, 20 prediction tasks, and 6 research areas. MultiBench provides an automated end-to-end machine learning pipeline that simplifies and standardizes data loading, experimental setup, and model evaluation. To enable holistic evaluation, MultiBench offers a comprehensive methodology to assess (1) generalization, (2) time and space complexity, and (3) modality robustness. MultiBench introduces impactful challenges for future research, including scalability to large-scale multimodal datasets and robustness to realistic imperfections. To accompany this benchmark, we also provide a standardized implementation of 20 core approaches in multimodal learning. Simply applying methods proposed in different research areas can improve the state-of-the-art performance on 9/15 datasets. Therefore, MultiBench presents a milestone in unifying disjoint efforts in multimodal research and paves the way towards a better understanding of the capabilities and limitations of multimodal models, all the while ensuring ease of use, accessibility, and reproducibility. MultiBench, our standardized code, and leaderboards are publicly available, will be regularly updated, and welcomes inputs from the community.
Differentiable Factor Graph Optimization for Learning Smoothers
May 20, 2021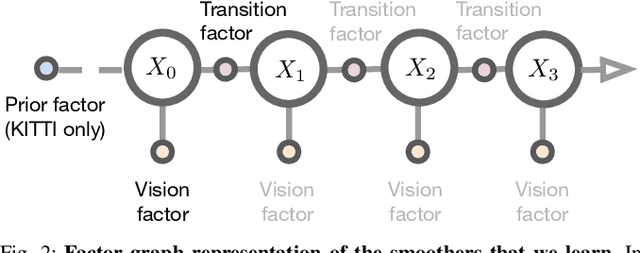
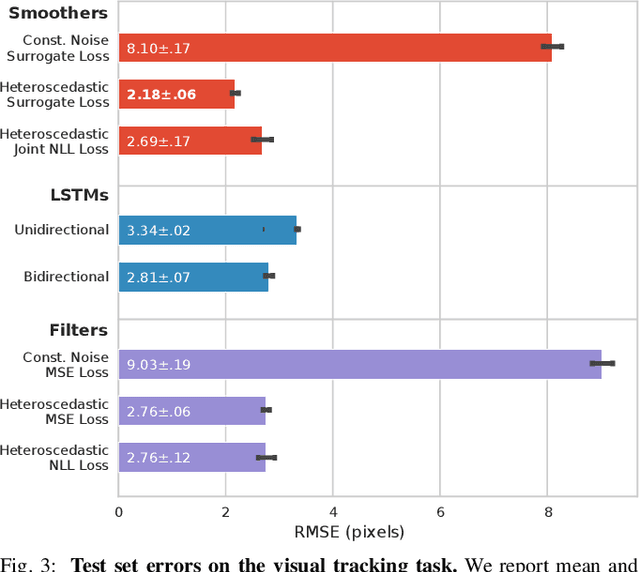
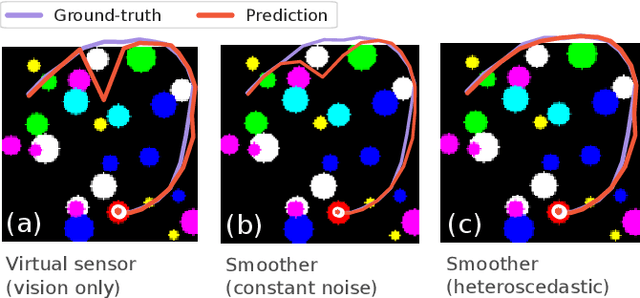
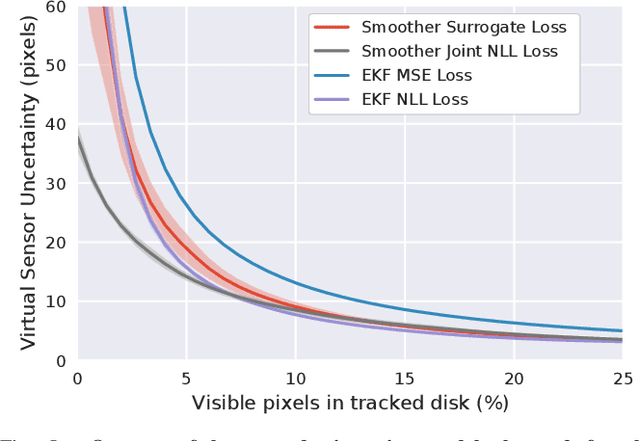
A recent line of work has shown that end-to-end optimization of Bayesian filters can be used to learn state estimators for systems whose underlying models are difficult to hand-design or tune, while retaining the core advantages of probabilistic state estimation. As an alternative approach for state estimation in these settings, we present an end-to-end approach for learning state estimators modeled as factor graph-based smoothers. By unrolling the optimizer we use for maximum a posteriori inference in these probabilistic graphical models, this method is able to learn probabilistic system models in the full context of an overall state estimator, while also taking advantage of the distinct accuracy and runtime advantages that smoothers offer over recursive filters. We study our approach using two fundamental state estimation problems, object tracking and visual odometry, where we demonstrate a significant improvement over existing baselines. Our work comes with an extensive code release, which includes the evaluated models and libraries for differentiable Lie theory and factor graph optimization: https://sites.google.com/view/diffsmoothing/
Interpreting Contact Interactions to Overcome Failure in Robot Assembly Tasks
Jan 07, 2021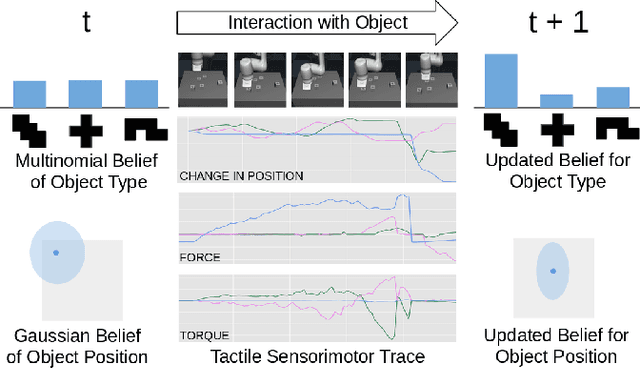
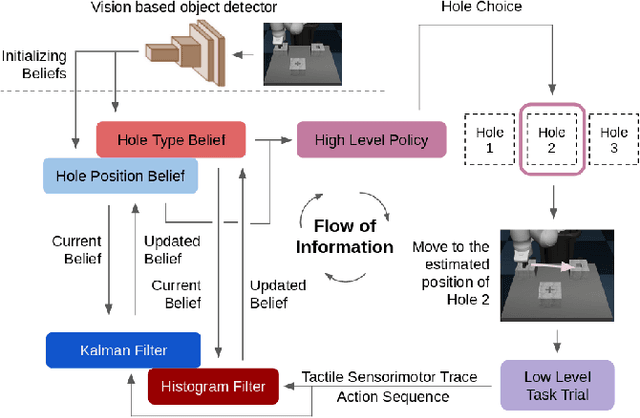
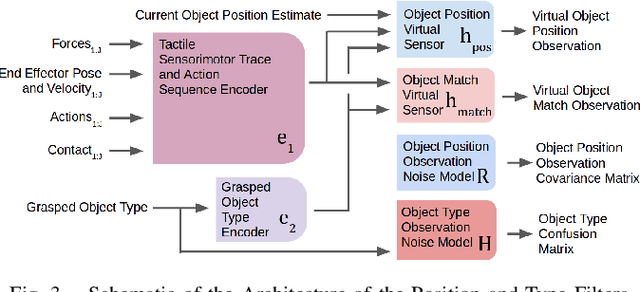
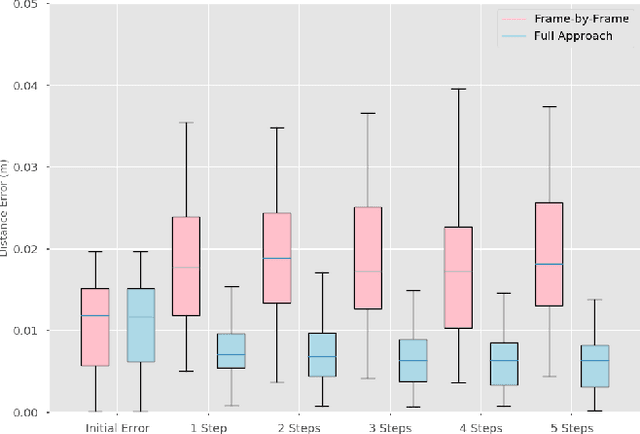
A key challenge towards the goal of multi-part assembly tasks is finding robust sensorimotor control methods in the presence of uncertainty. In contrast to previous works that rely on a priori knowledge on whether two parts match, we aim to learn this through physical interaction. We propose a hierachical approach that enables a robot to autonomously assemble parts while being uncertain about part types and positions. In particular, our probabilistic approach learns a set of differentiable filters that leverage the tactile sensorimotor trace from failed assembly attempts to update its belief about part position and type. This enables a robot to overcome assembly failure. We demonstrate the effectiveness of our approach on a set of object fitting tasks. The experimental results indicate that our proposed approach achieves higher precision in object position and type estimation, and accomplishes object fitting tasks faster than baselines.
Detect, Reject, Correct: Crossmodal Compensation of Corrupted Sensors
Dec 01, 2020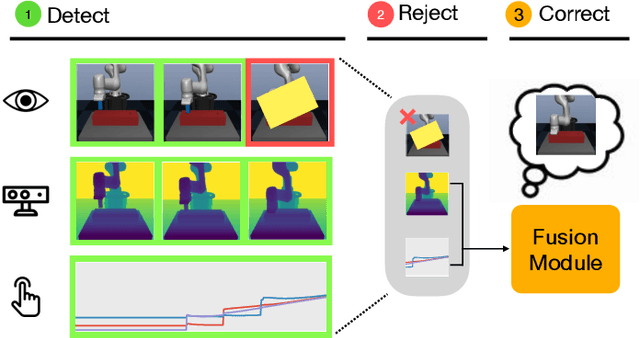
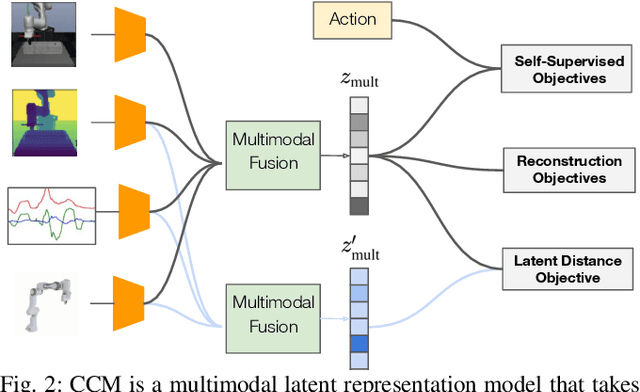
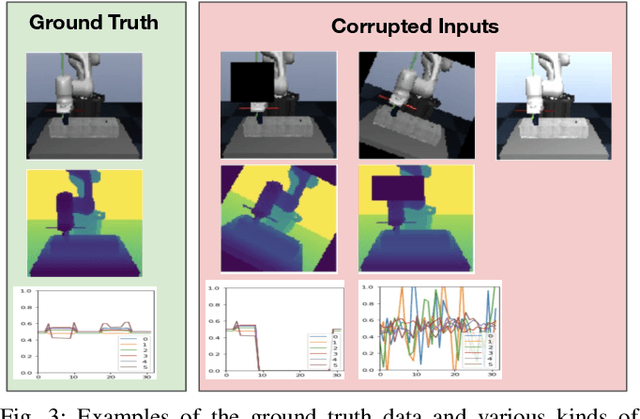
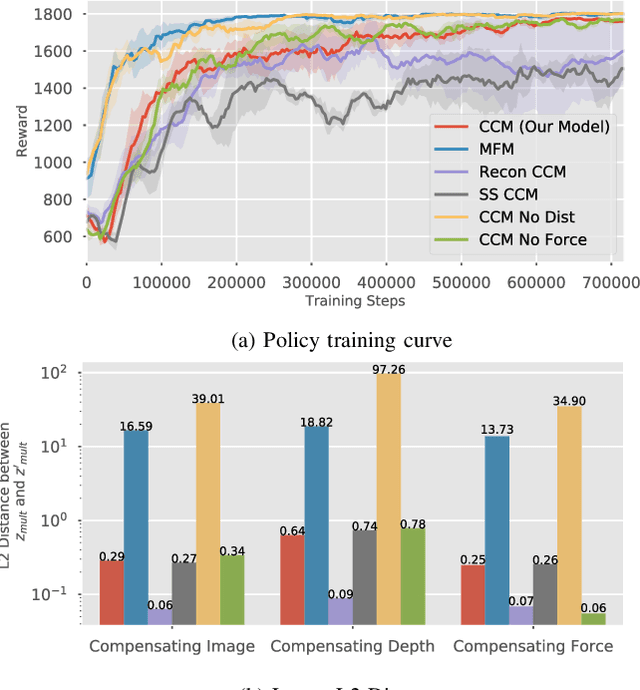
Using sensor data from multiple modalities presents an opportunity to encode redundant and complementary features that can be useful when one modality is corrupted or noisy. Humans do this everyday, relying on touch and proprioceptive feedback in visually-challenging environments. However, robots might not always know when their sensors are corrupted, as even broken sensors can return valid values. In this work, we introduce the Crossmodal Compensation Model (CCM), which can detect corrupted sensor modalities and compensate for them. CMM is a representation model learned with self-supervision that leverages unimodal reconstruction loss for corruption detection. CCM then discards the corrupted modality and compensates for it with information from the remaining sensors. We show that CCM learns rich state representations that can be used for contact-rich manipulation policies, even when input modalities are corrupted in ways not seen during training time.
Multimodal Sensor Fusion with Differentiable Filters
Oct 25, 2020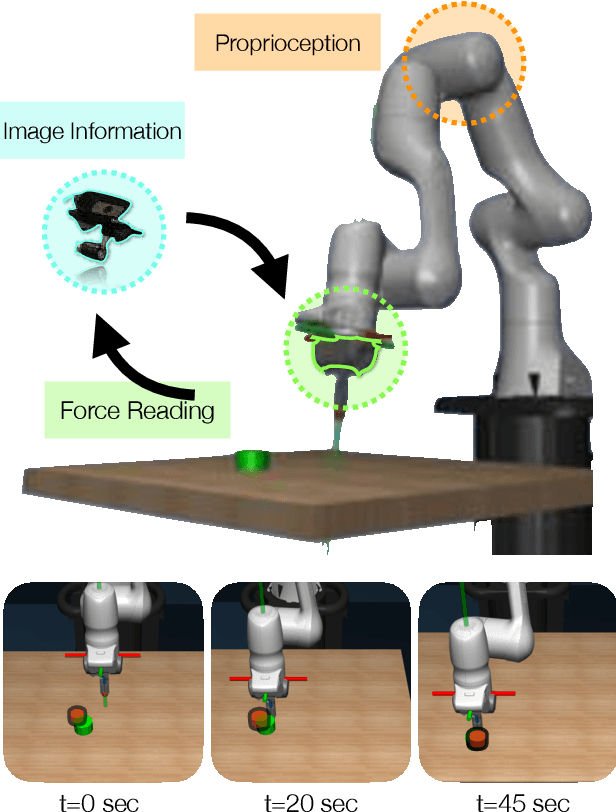
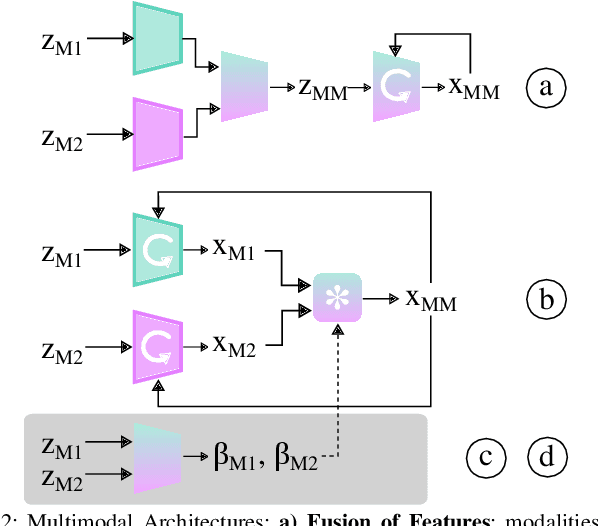
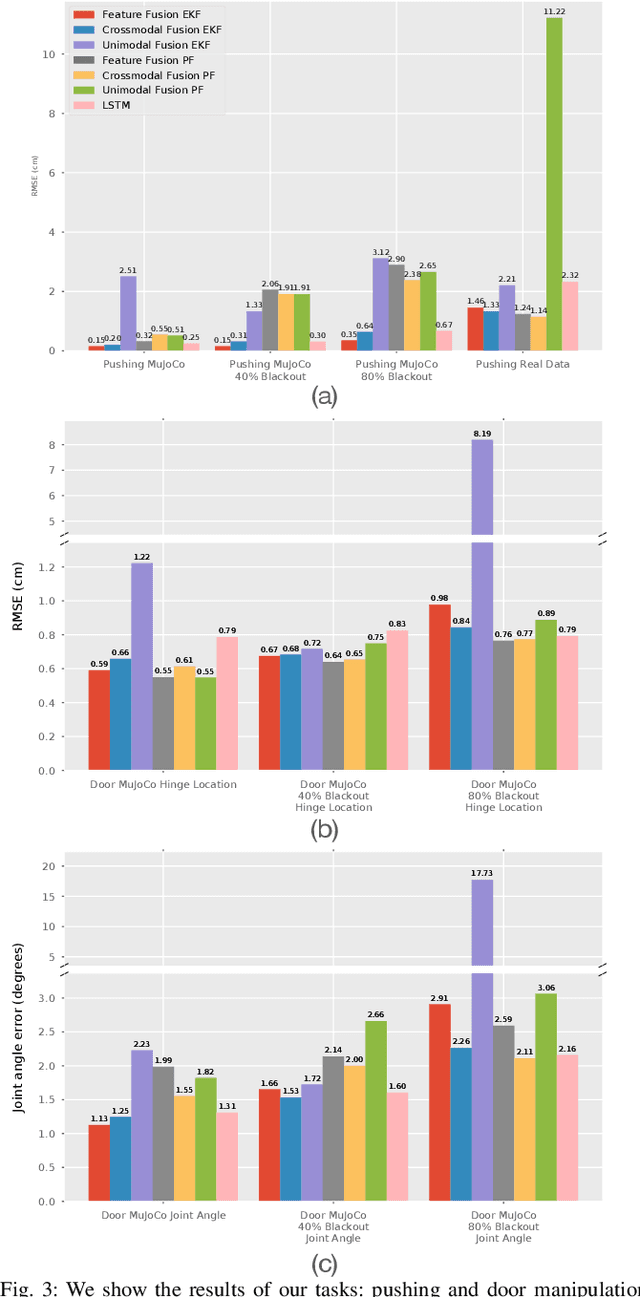
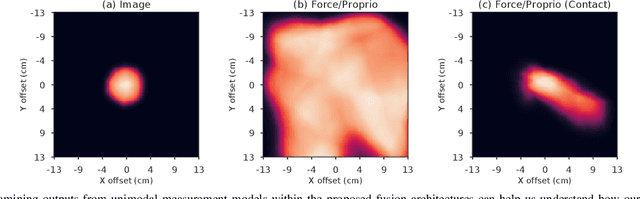
Leveraging multimodal information with recursive Bayesian filters improves performance and robustness of state estimation, as recursive filters can combine different modalities according to their uncertainties. Prior work has studied how to optimally fuse different sensor modalities with analytical state estimation algorithms. However, deriving the dynamics and measurement models along with their noise profile can be difficult or lead to intractable models. Differentiable filters provide a way to learn these models end-to-end while retaining the algorithmic structure of recursive filters. This can be especially helpful when working with sensor modalities that are high dimensional and have very different characteristics. In contact-rich manipulation, we want to combine visual sensing (which gives us global information) with tactile sensing (which gives us local information). In this paper, we study new differentiable filtering architectures to fuse heterogeneous sensor information. As case studies, we evaluate three tasks: two in planar pushing (simulated and real) and one in manipulating a kinematically constrained door (simulated). In extensive evaluations, we find that differentiable filters that leverage crossmodal sensor information reach comparable accuracies to unstructured LSTM models, while presenting interpretability benefits that may be important for safety-critical systems. We also release an open-source library for creating and training differentiable Bayesian filters in PyTorch, which can be found on our project website: https://sites.google.com/view/ multimodalfilter.
Guided Uncertainty-Aware Policy Optimization: Combining Learning and Model-Based Strategies for Sample-Efficient Policy Learning
May 26, 2020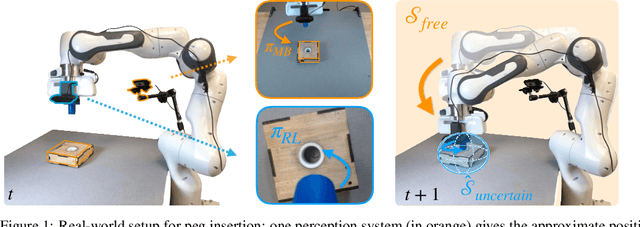
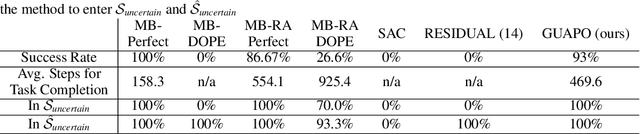
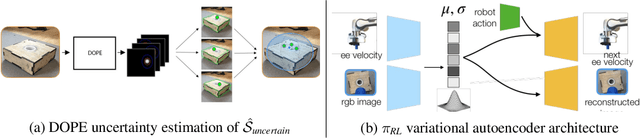
Traditional robotic approaches rely on an accurate model of the environment, a detailed description of how to perform the task, and a robust perception system to keep track of the current state. On the other hand, reinforcement learning approaches can operate directly from raw sensory inputs with only a reward signal to describe the task, but are extremely sample-inefficient and brittle. In this work, we combine the strengths of model-based methods with the flexibility of learning-based methods to obtain a general method that is able to overcome inaccuracies in the robotics perception/actuation pipeline, while requiring minimal interactions with the environment. This is achieved by leveraging uncertainty estimates to divide the space in regions where the given model-based policy is reliable, and regions where it may have flaws or not be well defined. In these uncertain regions, we show that a locally learned-policy can be used directly with raw sensory inputs. We test our algorithm, Guided Uncertainty-Aware Policy Optimization (GUAPO), on a real-world robot performing peg insertion. Videos are available at https://sites.google.com/view/guapo-rl
Variable Impedance Control in End-Effector Space: An Action Space for Reinforcement Learning in Contact-Rich Tasks
Aug 02, 2019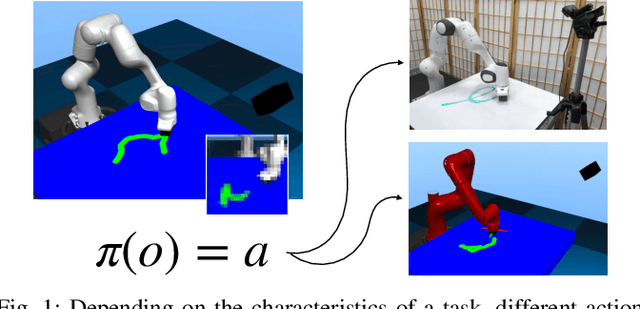
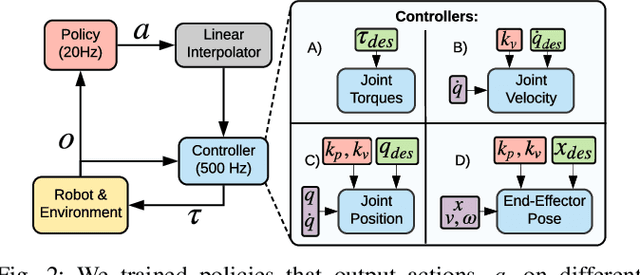
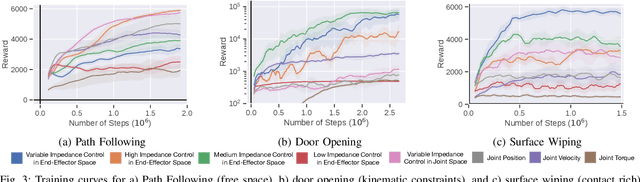
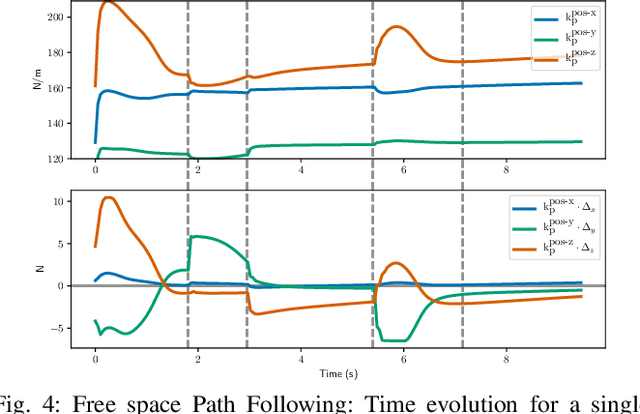
Reinforcement Learning (RL) of contact-rich manipulation tasks has yielded impressive results in recent years. While many studies in RL focus on varying the observation space or reward model, few efforts focused on the choice of action space (e.g. joint or end-effector space, position, velocity, etc.). However, studies in robot motion control indicate that choosing an action space that conforms to the characteristics of the task can simplify exploration and improve robustness to disturbances. This paper studies the effect of different action spaces in deep RL and advocates for Variable Impedance Control in End-effector Space (VICES) as an advantageous action space for constrained and contact-rich tasks. We evaluate multiple action spaces on three prototypical manipulation tasks: Path Following (task with no contact), Door Opening (task with kinematic constraints), and Surface Wiping (task with continuous contact). We show that VICES improves sample efficiency, maintains low energy consumption, and ensures safety across all three experimental setups. Further, RL policies learned with VICES can transfer across different robot models in simulation, and from simulation to real for the same robot. Further information is available at https://stanfordvl.github.io/vices.
Making Sense of Vision and Touch: Learning Multimodal Representations for Contact-Rich Tasks
Jul 28, 2019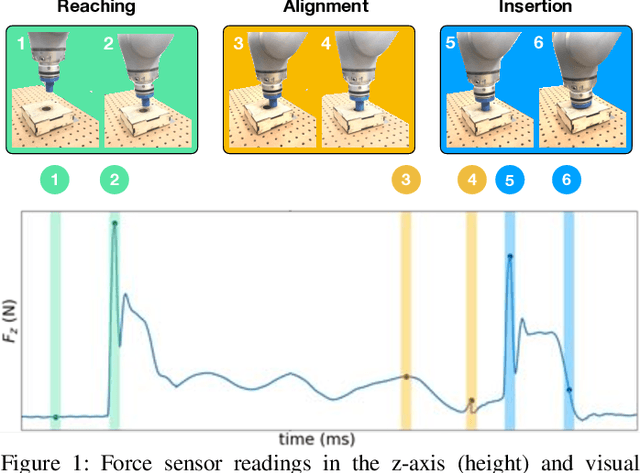
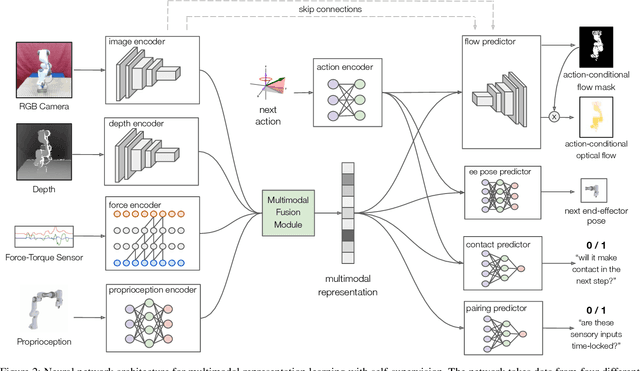
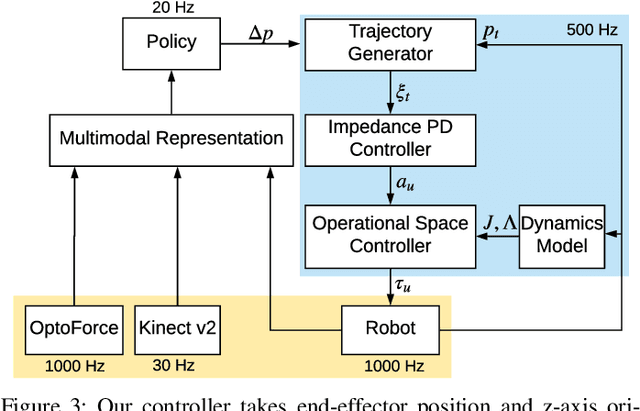
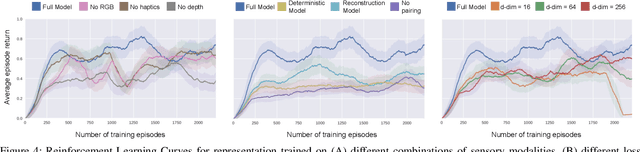
Contact-rich manipulation tasks in unstructured environments often require both haptic and visual feedback. It is non-trivial to manually design a robot controller that combines these modalities which have very different characteristics. While deep reinforcement learning has shown success in learning control policies for high-dimensional inputs, these algorithms are generally intractable to deploy on real robots due to sample complexity. In this work, we use self-supervision to learn a compact and multimodal representation of our sensory inputs, which can then be used to improve the sample efficiency of our policy learning. Evaluating our method on a peg insertion task, we show that it generalizes over varying geometries, configurations, and clearances, while being robust to external perturbations. We also systematically study different self-supervised learning objectives and representation learning architectures. Results are presented in simulation and on a physical robot.
Making Sense of Vision and Touch: Self-Supervised Learning of Multimodal Representations for Contact-Rich Tasks
Mar 08, 2019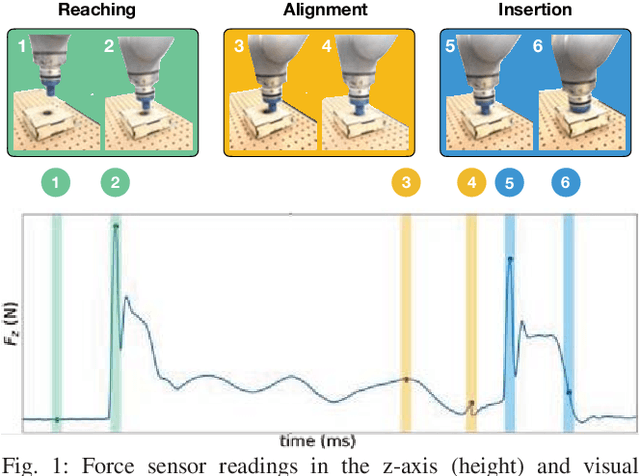
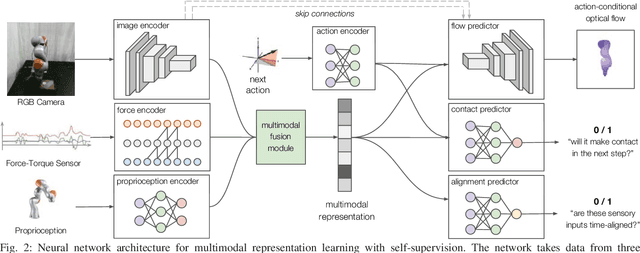

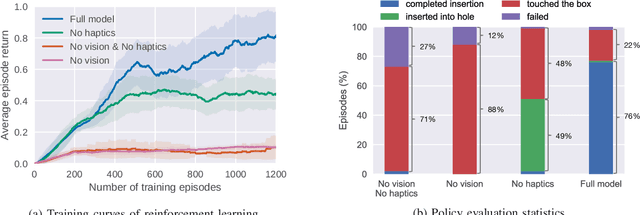
Contact-rich manipulation tasks in unstructured environments often require both haptic and visual feedback. However, it is non-trivial to manually design a robot controller that combines modalities with very different characteristics. While deep reinforcement learning has shown success in learning control policies for high-dimensional inputs, these algorithms are generally intractable to deploy on real robots due to sample complexity. We use self-supervision to learn a compact and multimodal representation of our sensory inputs, which can then be used to improve the sample efficiency of our policy learning. We evaluate our method on a peg insertion task, generalizing over different geometry, configurations, and clearances, while being robust to external perturbations. Results for simulated and real robot experiments are presented.