 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGet a Grip: Multi-Finger Grasp Evaluation at Scale Enables Robust Sim-to-Real Transfer
Oct 31, 2024This work explores conditions under which multi-finger grasping algorithms can attain robust sim-to-real transfer. While numerous large datasets facilitate learning generative models for multi-finger grasping at scale, reliable real-world dexterous grasping remains challenging, with most methods degrading when deployed on hardware. An alternate strategy is to use discriminative grasp evaluation models for grasp selection and refinement, conditioned on real-world sensor measurements. This paradigm has produced state-of-the-art results for vision-based parallel-jaw grasping, but remains unproven in the multi-finger setting. In this work, we find that existing datasets and methods have been insufficient for training discriminitive models for multi-finger grasping. To train grasp evaluators at scale, datasets must provide on the order of millions of grasps, including both positive and negative examples, with corresponding visual data resembling measurements at inference time. To that end, we release a new, open-source dataset of 3.5M grasps on 4.3K objects annotated with RGB images, point clouds, and trained NeRFs. Leveraging this dataset, we train vision-based grasp evaluators that outperform both analytic and generative modeling-based baselines on extensive simulated and real-world trials across a diverse range of objects. We show via numerous ablations that the key factor for performance is indeed the evaluator, and that its quality degrades as the dataset shrinks, demonstrating the importance of our new dataset. Project website at: https://sites.google.com/view/get-a-grip-dataset.
Adaptive Horizon Actor-Critic for Policy Learning in Contact-Rich Differentiable Simulation
May 28, 2024
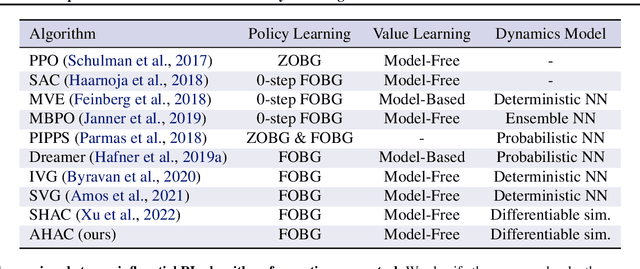
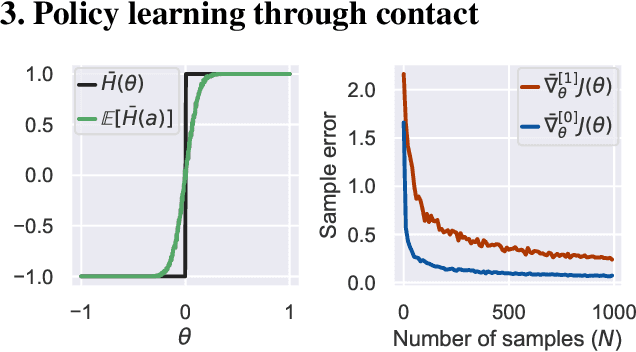

Model-Free Reinforcement Learning~(MFRL), leveraging the policy gradient theorem, has demonstrated considerable success in continuous control tasks. However, these approaches are plagued by high gradient variance due to zeroth-order gradient estimation, resulting in suboptimal policies. Conversely, First-Order Model-Based Reinforcement Learning~(FO-MBRL) methods, employing differentiable simulation, provide gradients with reduced variance but are susceptible to sampling error in scenarios involving stiff dynamics, such as physical contact. This paper investigates the source of this error and introduces Adaptive Horizon Actor-Critic (AHAC), an FO-MBRL algorithm that reduces gradient error by adapting the model-based horizon to avoid stiff dynamics. Empirical findings reveal that AHAC outperforms MFRL baselines, attaining 40\% more reward across a set of locomotion tasks, and efficiently scaling to high-dimensional control environments with improved wall-clock-time efficiency.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
A Robot Cluster for Reproducible Research in Dexterous Manipulation
Sep 22, 2021

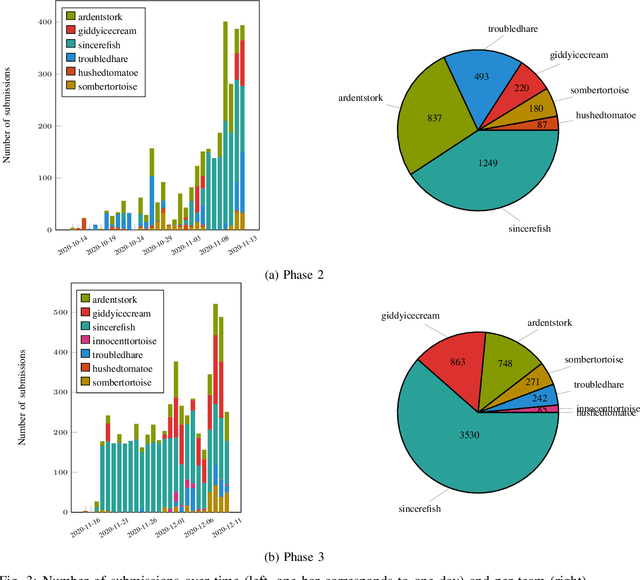
Dexterous manipulation remains an open problem in robotics. To coordinate efforts of the research community towards tackling this problem, we propose a shared benchmark. We designed and built robotic platforms that are hosted at the MPI-IS and can be accessed remotely. Each platform consists of three robotic fingers that are capable of dexterous object manipulation. Users are able to control the platforms remotely by submitting code that is executed automatically, akin to a computational cluster. Using this setup, i) we host robotics competitions, where teams from anywhere in the world access our platforms to tackle challenging tasks, ii) we publish the datasets collected during these competitions (consisting of hundreds of robot hours), and iii) we give researchers access to these platforms for their own projects.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Learning Latent Actions to Control Assistive Robots
Jul 10, 2021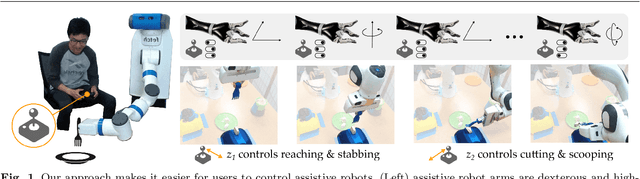

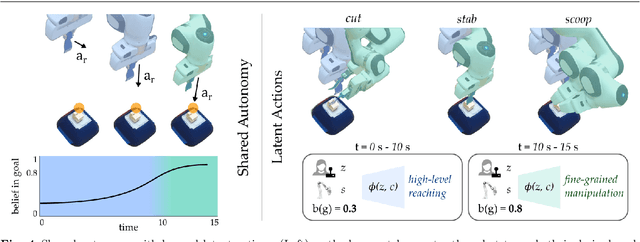
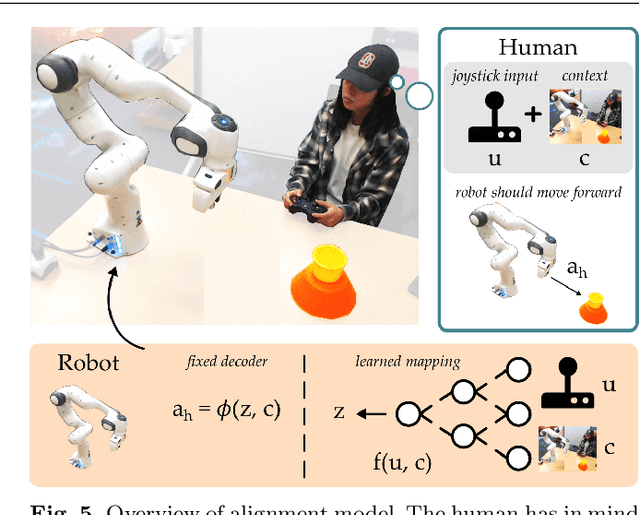
Assistive robot arms enable people with disabilities to conduct everyday tasks on their own. These arms are dexterous and high-dimensional; however, the interfaces people must use to control their robots are low-dimensional. Consider teleoperating a 7-DoF robot arm with a 2-DoF joystick. The robot is helping you eat dinner, and currently you want to cut a piece of tofu. Today's robots assume a pre-defined mapping between joystick inputs and robot actions: in one mode the joystick controls the robot's motion in the x-y plane, in another mode the joystick controls the robot's z-yaw motion, and so on. But this mapping misses out on the task you are trying to perform! Ideally, one joystick axis should control how the robot stabs the tofu and the other axis should control different cutting motions. Our insight is that we can achieve intuitive, user-friendly control of assistive robots by embedding the robot's high-dimensional actions into low-dimensional and human-controllable latent actions. We divide this process into three parts. First, we explore models for learning latent actions from offline task demonstrations, and formalize the properties that latent actions should satisfy. Next, we combine learned latent actions with autonomous robot assistance to help the user reach and maintain their high-level goals. Finally, we learn a personalized alignment model between joystick inputs and latent actions. We evaluate our resulting approach in four user studies where non-disabled participants reach marshmallows, cook apple pie, cut tofu, and assemble dessert. We then test our approach with two disabled adults who leverage assistive devices on a daily basis.
Dexterous Manipulation Primitives for the Real Robot Challenge
Jan 27, 2021
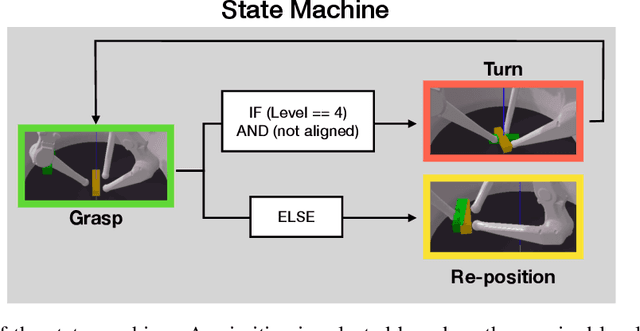
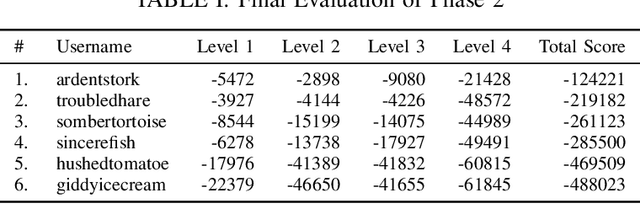
This report describes our approach for Phase 3 of the Real Robot Challenge. To solve cuboid manipulation tasks of varying difficulty, we decompose each task into the following primitives: moving the fingers to the cuboid to grasp it, turning it on the table to minimize orientation error, and re-positioning it to the goal position. We use model-based trajectory optimization and control to plan and execute these primitives. These grasping, turning, and re-positioning primitives are sequenced with a state-machine that determines which primitive to execute given the current object state and goal. Our method shows robust performance over multiple runs with randomized initial and goal positions. With this approach, our team placed second in the challenge, under the anonymous name "sombertortoise" on the leaderboard. Example runs of our method solving each of the four levels can be seen in this video (https://www.youtube.com/watch?v=I65Kwu9PGmg&list=PLt9QxrtaftrHGXcp4Oh8-s_OnQnBnLtei&index=1).
Recovery RL: Safe Reinforcement Learning with Learned Recovery Zones
Oct 29, 2020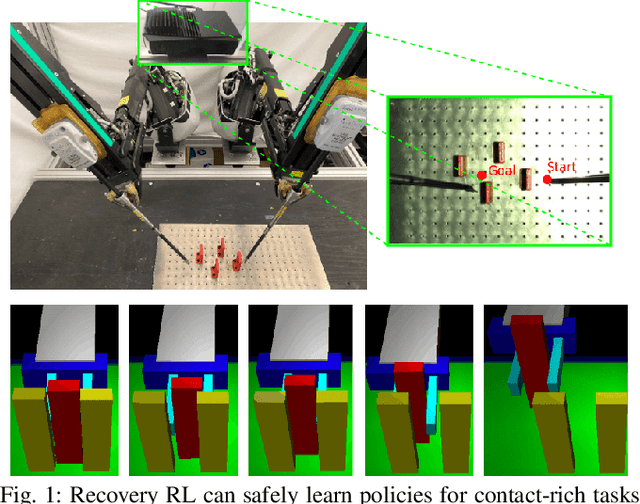
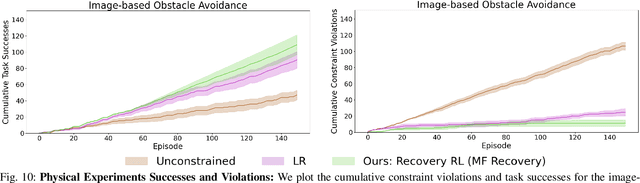
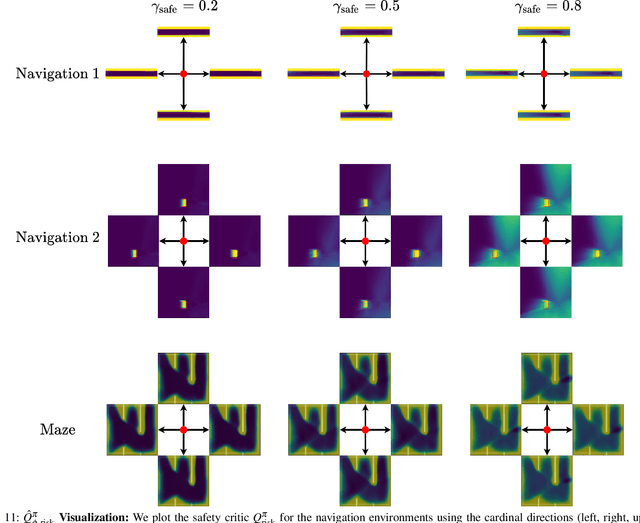
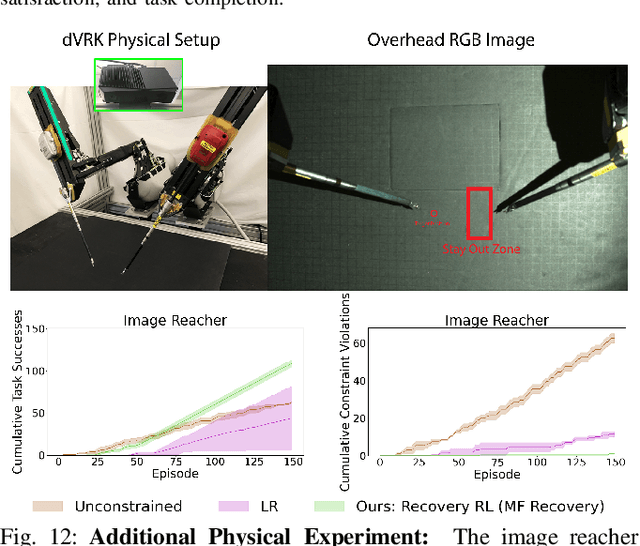
Safety remains a central obstacle preventing widespread use of RL in the real world: learning new tasks in uncertain environments requires extensive exploration, but safety requires limiting exploration. We propose Recovery RL, an algorithm which navigates this tradeoff by (1) leveraging offline data to learn about constraint violating zones before policy learning and (2) separating the goals of improving task performance and constraint satisfaction across two policies: a task policy that only optimizes the task reward and a recovery policy that guides the agent to safety when constraint violation is likely. We evaluate Recovery RL on 6 simulation domains, including two contact-rich manipulation tasks and an image-based navigation task, and an image-based obstacle avoidance task on a physical robot. We compare Recovery RL to 5 prior safe RL methods which jointly optimize for task performance and safety via constrained optimization or reward shaping and find that Recovery RL outperforms the next best prior method across all domains. Results suggest that Recovery RL trades off constraint violations and task successes 2 - 80 times more efficiently in simulation domains and 3 times more efficiently in physical experiments. See https://tinyurl.com/rl-recovery for videos and supplementary material.
Learning to be Safe: Deep RL with a Safety Critic
Oct 27, 2020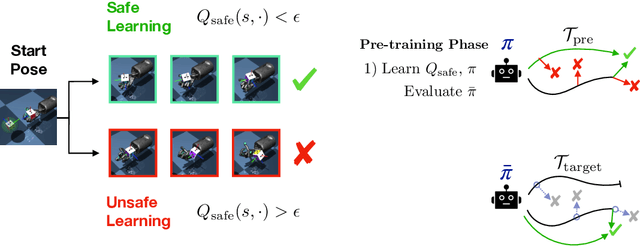
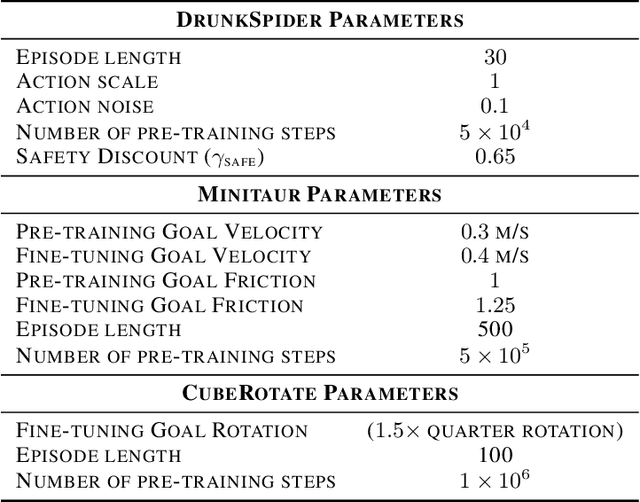
Safety is an essential component for deploying reinforcement learning (RL) algorithms in real-world scenarios, and is critical during the learning process itself. A natural first approach toward safe RL is to manually specify constraints on the policy's behavior. However, just as learning has enabled progress in large-scale development of AI systems, learning safety specifications may also be necessary to ensure safety in messy open-world environments where manual safety specifications cannot scale. Akin to how humans learn incrementally starting in child-safe environments, we propose to learn how to be safe in one set of tasks and environments, and then use that learned intuition to constrain future behaviors when learning new, modified tasks. We empirically study this form of safety-constrained transfer learning in three challenging domains: simulated navigation, quadruped locomotion, and dexterous in-hand manipulation. In comparison to standard deep RL techniques and prior approaches to safe RL, we find that our method enables the learning of new tasks and in new environments with both substantially fewer safety incidents, such as falling or dropping an object, and faster, more stable learning. This suggests a path forward not only for safer RL systems, but also for more effective RL systems.
Learning Hierarchical Control for Robust In-Hand Manipulation
Oct 24, 2019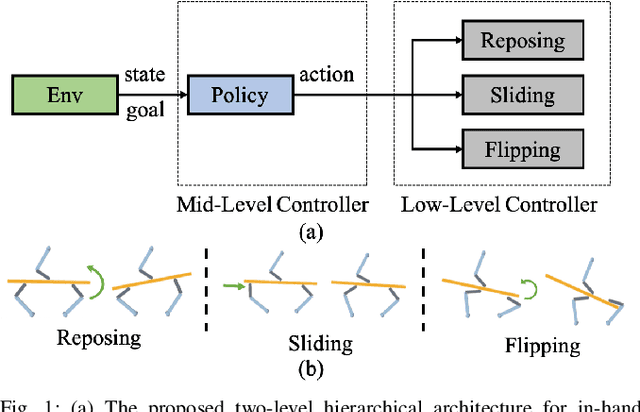
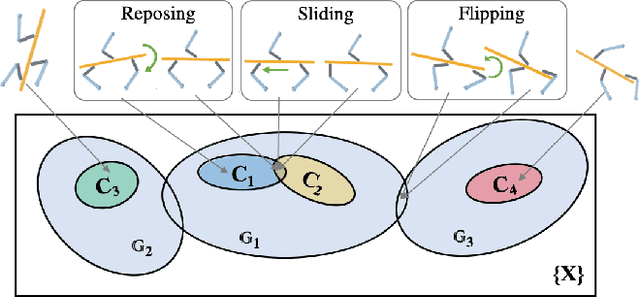
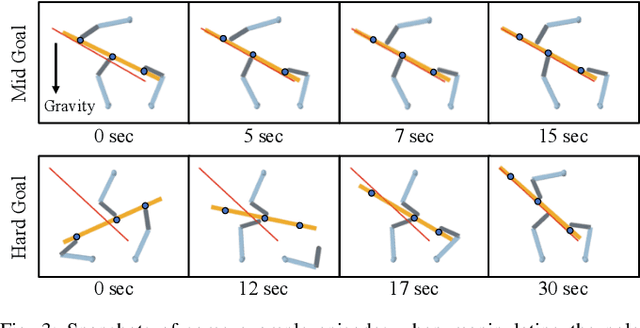
Robotic in-hand manipulation has been a long-standing challenge due to the complexity of modelling hand and object in contact and of coordinating finger motion for complex manipulation sequences. To address these challenges, the majority of prior work has either focused on model-based, low-level controllers or on model-free deep reinforcement learning that each have their own limitations. We propose a hierarchical method that relies on traditional, model-based controllers on the low-level and learned policies on the mid-level. The low-level controllers can robustly execute different manipulation primitives (reposing, sliding, flipping). The mid-level policy orchestrates these primitives. We extensively evaluate our approach in simulation with a 3-fingered hand that controls three degrees of freedom of elongated objects. We show that our approach can move objects between almost all the possible poses in the workspace while keeping them firmly grasped. We also show that our approach is robust to inaccuracies in the object models and to observation noise. Finally, we show how our approach generalizes to objects of other shapes.