 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffSim2Real: Deploying Quadrupedal Locomotion Policies Purely Trained in Differentiable Simulation
Nov 04, 2024
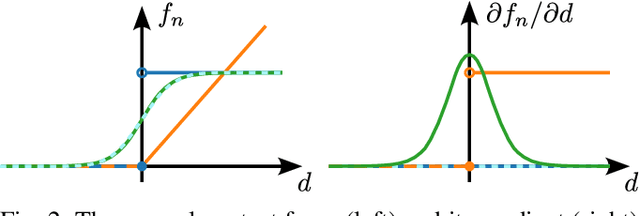

Differentiable simulators provide analytic gradients, enabling more sample-efficient learning algorithms and paving the way for data intensive learning tasks such as learning from images. In this work, we demonstrate that locomotion policies trained with analytic gradients from a differentiable simulator can be successfully transferred to the real world. Typically, simulators that offer informative gradients lack the physical accuracy needed for sim-to-real transfer, and vice-versa. A key factor in our success is a smooth contact model that combines informative gradients with physical accuracy, ensuring effective transfer of learned behaviors. To the best of our knowledge, this is the first time a real quadrupedal robot is able to locomote after training exclusively in a differentiable simulation.
PWM: Policy Learning with Large World Models
Jul 02, 2024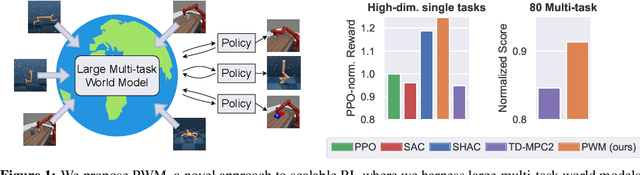


Reinforcement Learning (RL) has achieved impressive results on complex tasks but struggles in multi-task settings with different embodiments. World models offer scalability by learning a simulation of the environment, yet they often rely on inefficient gradient-free optimization methods. We introduce Policy learning with large World Models (PWM), a novel model-based RL algorithm that learns continuous control policies from large multi-task world models. By pre-training the world model on offline data and using it for first-order gradient policy learning, PWM effectively solves tasks with up to 152 action dimensions and outperforms methods using ground-truth dynamics. Additionally, PWM scales to an 80-task setting, achieving up to 27% higher rewards than existing baselines without the need for expensive online planning. Visualizations and code available at https://policy-world-model.github.io
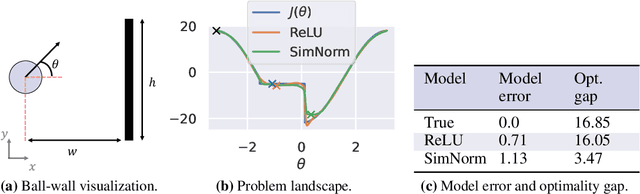
Adaptive Horizon Actor-Critic for Policy Learning in Contact-Rich Differentiable Simulation
May 28, 2024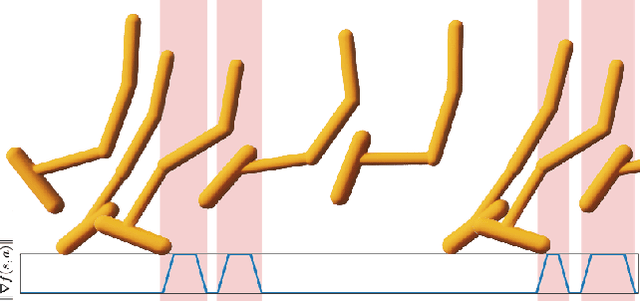
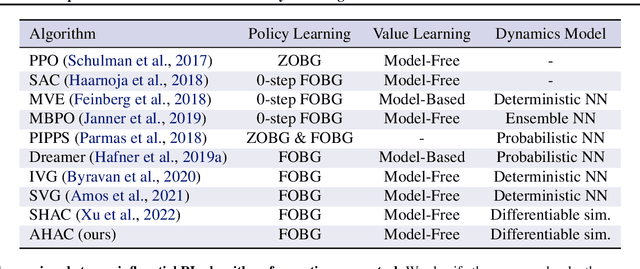
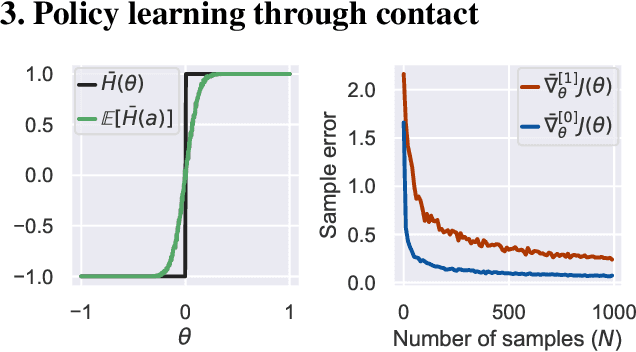

Model-Free Reinforcement Learning~(MFRL), leveraging the policy gradient theorem, has demonstrated considerable success in continuous control tasks. However, these approaches are plagued by high gradient variance due to zeroth-order gradient estimation, resulting in suboptimal policies. Conversely, First-Order Model-Based Reinforcement Learning~(FO-MBRL) methods, employing differentiable simulation, provide gradients with reduced variance but are susceptible to sampling error in scenarios involving stiff dynamics, such as physical contact. This paper investigates the source of this error and introduces Adaptive Horizon Actor-Critic (AHAC), an FO-MBRL algorithm that reduces gradient error by adapting the model-based horizon to avoid stiff dynamics. Empirical findings reveal that AHAC outperforms MFRL baselines, attaining 40\% more reward across a set of locomotion tasks, and efficiently scaling to high-dimensional control environments with improved wall-clock-time efficiency.
Iterative Semi-parametric Dynamics Model Learning For Autonomous Racing
Nov 17, 2020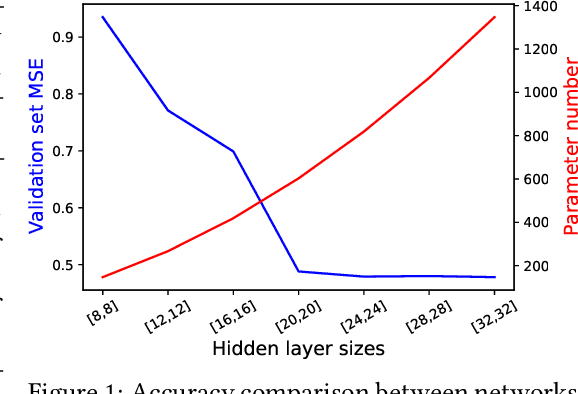
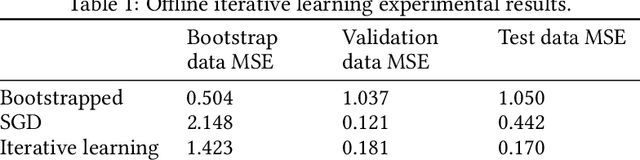

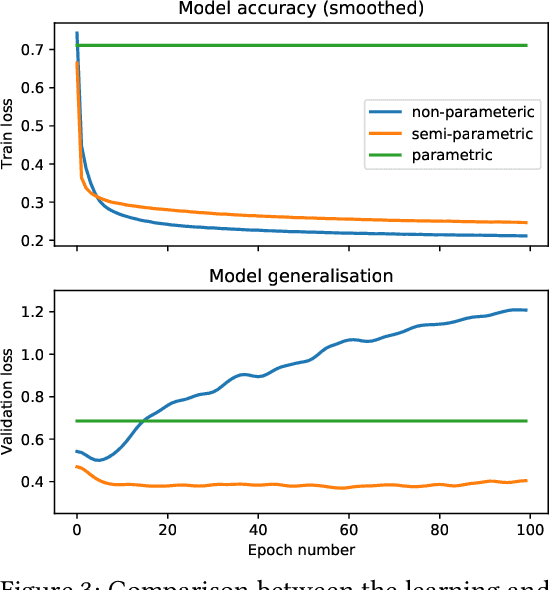
Accurately modeling robot dynamics is crucial to safe and efficient motion control. In this paper, we develop and apply an iterative learning semi-parametric model, with a neural network, to the task of autonomous racing with a Model Predictive Controller (MPC). We present a novel non-linear semi-parametric dynamics model where we represent the known dynamics with a parametric model, and a neural network captures the unknown dynamics. We show that our model can learn more accurately than a purely parametric model and generalize better than a purely non-parametric model, making it ideal for real-world applications where collecting data from the full state space is not feasible. We present a system where the model is bootstrapped on pre-recorded data and then updated iteratively at run time. Then we apply our iterative learning approach to the simulated problem of autonomous racing and show that it can safely adapt to modified dynamics online and even achieve better performance than models trained on data from manual driving.