 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffSim2Real: Deploying Quadrupedal Locomotion Policies Purely Trained in Differentiable Simulation
Nov 04, 2024
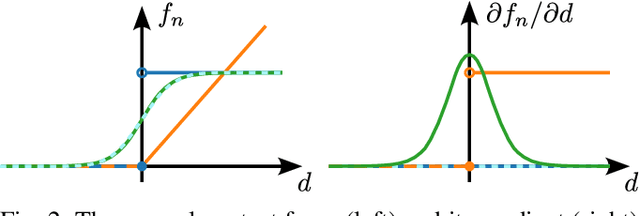

Differentiable simulators provide analytic gradients, enabling more sample-efficient learning algorithms and paving the way for data intensive learning tasks such as learning from images. In this work, we demonstrate that locomotion policies trained with analytic gradients from a differentiable simulator can be successfully transferred to the real world. Typically, simulators that offer informative gradients lack the physical accuracy needed for sim-to-real transfer, and vice-versa. A key factor in our success is a smooth contact model that combines informative gradients with physical accuracy, ensuring effective transfer of learned behaviors. To the best of our knowledge, this is the first time a real quadrupedal robot is able to locomote after training exclusively in a differentiable simulation.
Guided Reinforcement Learning for Robust Multi-Contact Loco-Manipulation
Oct 17, 2024
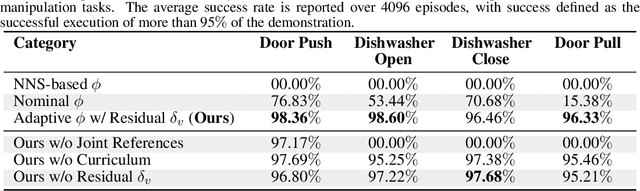
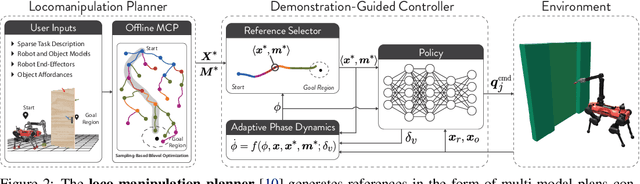

Reinforcement learning (RL) often necessitates a meticulous Markov Decision Process (MDP) design tailored to each task. This work aims to address this challenge by proposing a systematic approach to behavior synthesis and control for multi-contact loco-manipulation tasks, such as navigating spring-loaded doors and manipulating heavy dishwashers. We define a task-independent MDP to train RL policies using only a single demonstration per task generated from a model-based trajectory optimizer. Our approach incorporates an adaptive phase dynamics formulation to robustly track the demonstrations while accommodating dynamic uncertainties and external disturbances. We compare our method against prior motion imitation RL works and show that the learned policies achieve higher success rates across all considered tasks. These policies learn recovery maneuvers that are not present in the demonstration, such as re-grasping objects during execution or dealing with slippages. Finally, we successfully transfer the policies to a real robot, demonstrating the practical viability of our approach.
Learning Quadrupedal Locomotion via Differentiable Simulation
Apr 03, 2024



The emergence of differentiable simulators enabling analytic gradient computation has motivated a new wave of learning algorithms that hold the potential to significantly increase sample efficiency over traditional Reinforcement Learning (RL) methods. While recent research has demonstrated performance gains in scenarios with comparatively smooth dynamics and, thus, smooth optimization landscapes, research on leveraging differentiable simulators for contact-rich scenarios, such as legged locomotion, is scarce. This may be attributed to the discontinuous nature of contact, which introduces several challenges to optimizing with analytic gradients. The purpose of this paper is to determine if analytic gradients can be beneficial even in the face of contact. Our investigation focuses on the effects of different soft and hard contact models on the learning process, examining optimization challenges through the lens of contact simulation. We demonstrate the viability of employing analytic gradients to learn physically plausible locomotion skills with a quadrupedal robot using Short-Horizon Actor-Critic (SHAC), a learning algorithm leveraging analytic gradients, and draw a comparison to a state-of-the-art RL algorithm, Proximal Policy Optimization (PPO), to understand the benefits of analytic gradients.
Versatile Multi-Contact Planning and Control for Legged Loco-Manipulation
Aug 17, 2023Loco-manipulation planning skills are pivotal for expanding the utility of robots in everyday environments. These skills can be assessed based on a system's ability to coordinate complex holistic movements and multiple contact interactions when solving different tasks. However, existing approaches have been merely able to shape such behaviors with hand-crafted state machines, densely engineered rewards, or pre-recorded expert demonstrations. Here, we propose a minimally-guided framework that automatically discovers whole-body trajectories jointly with contact schedules for solving general loco-manipulation tasks in pre-modeled environments. The key insight is that multi-modal problems of this nature can be formulated and treated within the context of integrated Task and Motion Planning (TAMP). An effective bilevel search strategy is achieved by incorporating domain-specific rules and adequately combining the strengths of different planning techniques: trajectory optimization and informed graph search coupled with sampling-based planning. We showcase emergent behaviors for a quadrupedal mobile manipulator exploiting both prehensile and non-prehensile interactions to perform real-world tasks such as opening/closing heavy dishwashers and traversing spring-loaded doors. These behaviors are also deployed on the real system using a two-layer whole-body tracking controller.
A Collision-Free MPC for Whole-Body Dynamic Locomotion and Manipulation
Feb 24, 2022
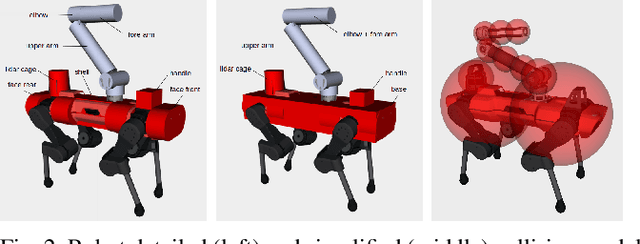


In this paper, we present a real-time whole-body planner for collision-free legged mobile manipulation. We enforce both self-collision and environment-collision avoidance as soft constraints within a Model Predictive Control (MPC) scheme that solves a multi-contact optimal control problem. By penalizing the signed distances among a set of representative primitive collision bodies, the robot is able to safely execute a variety of dynamic maneuvers while preventing any self-collisions. Moreover, collision-free navigation and manipulation in both static and dynamic environments are made viable through efficient queries of distances and their gradients via a euclidean signed distance field. We demonstrate through a comparative study that our approach only slightly increases the computational complexity of the MPC planning. Finally, we validate the effectiveness of our framework through a set of hardware experiments involving dynamic mobile manipulation tasks with potential collisions, such as locomotion balancing with the swinging arm, weight throwing, and autonomous door opening.
Passivity-based control for haptic teleoperation of a legged manipulator in presence of time-delays
Aug 17, 2021

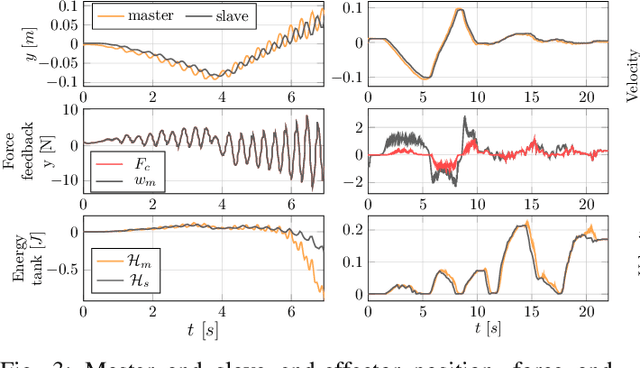
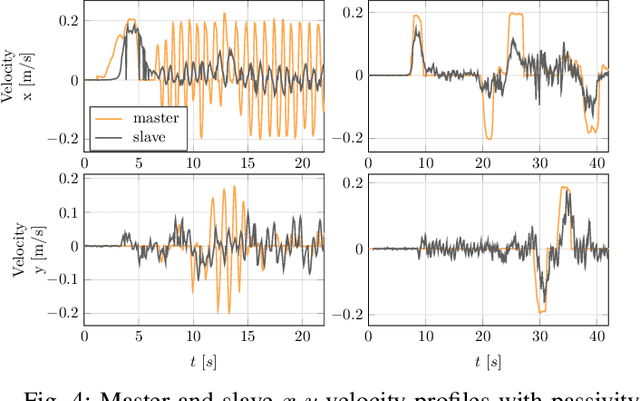
When dealing with the haptic teleoperation of multi-limbed mobile manipulators, the problem of mitigating the destabilizing effects arising from the communication link between the haptic device and the remote robot has not been properly addressed. In this work, we propose a passive control architecture to haptically teleoperate a legged mobile manipulator, while remaining stable in the presence of time delays and frequency mismatches in the master and slave controllers. At the master side, a discrete-time energy modulation of the control input is proposed. At the slave side, passivity constraints are included in an optimization-based whole-body controller to satisfy the energy limitations. A hybrid teleoperation scheme allows the human operator to remotely operate the robot's end-effector while in stance mode, and its base velocity in locomotion mode. The resulting control architecture is demonstrated on a quadrupedal robot with an artificial delay added to the network.
Generating Continuous Motion and Force Plans in Real-Time for Legged Mobile Manipulation
Apr 23, 2021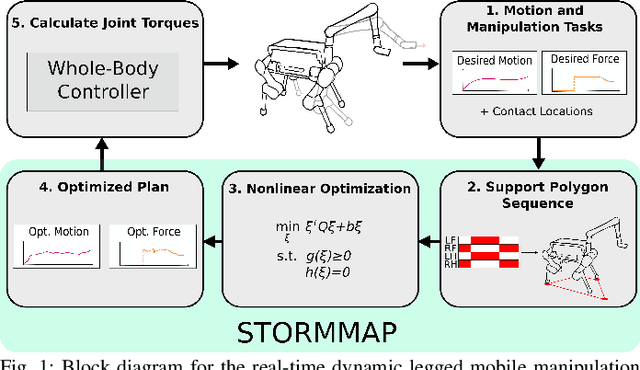

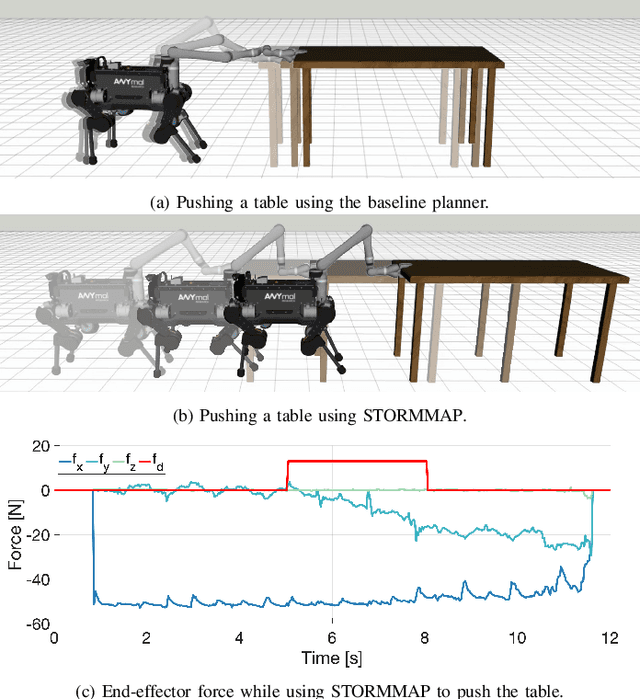
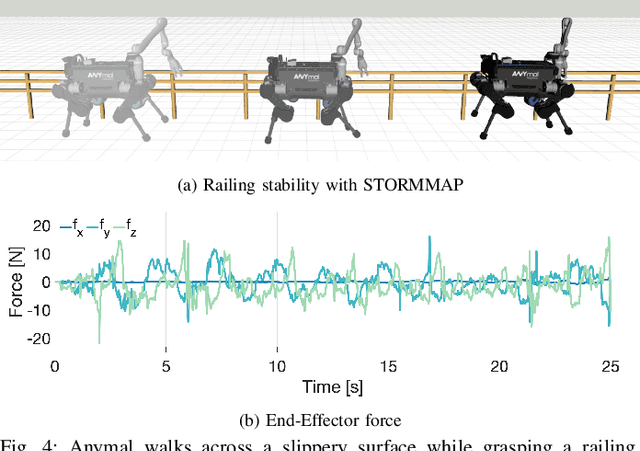
Manipulators can be added to legged robots, allowing them to interact with and change their environment. Legged mobile manipulation planners must consider how contact forces generated by these manipulators affect the system. Current planning strategies either treat these forces as immutable during planning or are unable to optimize over these contact forces while operating in real-time. This paper presents the Stability and Task Oriented Receding-Horizon Motion and Manipulation Autonomous Planner (STORMMAP) that is able to generate continuous plans for the robot's motion and manipulation force trajectories that ensure dynamic feasibility and stability of the platform, and incentivizes accomplishing manipulation and motion tasks specified by a user. STORMMAP uses a nonlinear optimization problem to compute these plans and is able to run in real-time by assuming contact locations are given a-priori, either by a user or an external algorithm. A variety of simulated experiments on a quadruped with a manipulator mounted to its torso demonstrate the versatility of STORMMAP. In contrast to existing state of the art methods, the approach described in this paper generates continuous plans in under ten milliseconds, an order of magnitude faster than previous strategies.
Contact-Implicit Trajectory Optimization for Dynamic Object Manipulation
Mar 01, 2021

We present a reformulation of a contact-implicit optimization (CIO) approach that computes optimal trajectories for rigid-body systems in contact-rich settings. A hard-contact model is assumed, and the unilateral constraints are imposed in the form of complementarity conditions. Newton's impact law is adopted for enhanced physical correctness. The optimal control problem is formulated as a multi-staged program through a multiple-shooting scheme. This problem structure is exploited within the FORCES Pro framework to retrieve optimal motion plans, contact sequences and control inputs with increased computational efficiency. We investigate our method on a variety of dynamic object manipulation tasks, performed by a six degrees of freedom robot. The dynamic feasibility of the optimal trajectories, as well as the repeatability and accuracy of the task-satisfaction are verified through simulations and real hardware experiments on one of the manipulation problems.
A Unified MPC Framework for Whole-Body Dynamic Locomotion and Manipulation
Mar 01, 2021
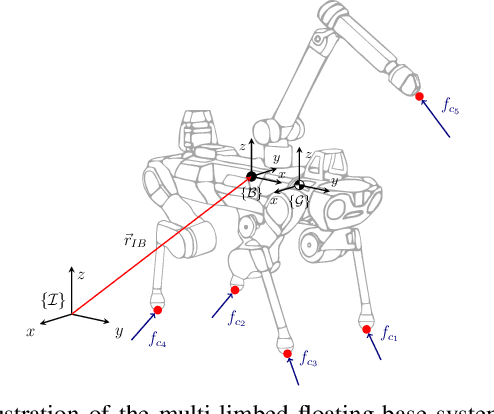
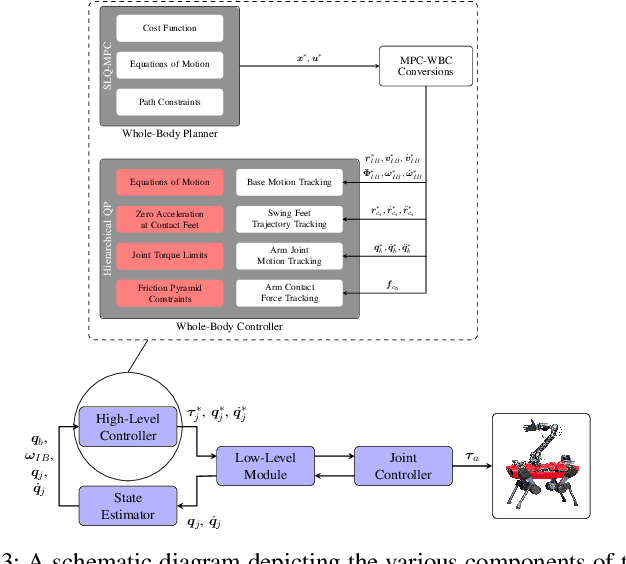

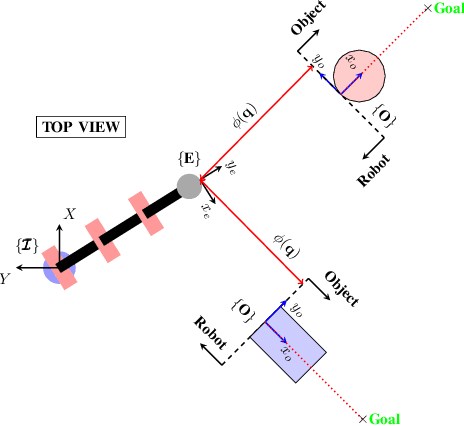
In this paper, we propose a whole-body planning framework that unifies dynamic locomotion and manipulation tasks by formulating a single multi-contact optimal control problem. We model the hybrid nature of a generic multi-limbed mobile manipulator as a switched system, and introduce a set of constraints that can encode any pre-defined gait sequence or manipulation schedule in the formulation. Since the system is designed to actively manipulate its environment, the equations of motion are composed by augmenting the robot's centroidal dynamics with the manipulated-object dynamics. This allows us to describe any high-level task in the same cost/constraint function. The resulting planning framework could be solved on the robot's onboard computer in real-time within a model predictive control scheme. This is demonstrated in a set of real hardware experiments done in free-motion, such as base or end-effector pose tracking, and while pushing/pulling a heavy resistive door. Robustness against model mismatches and external disturbances is also verified during these test cases.
Constraint Handling in Continuous-Time DDP-Based Model Predictive Control
Jan 15, 2021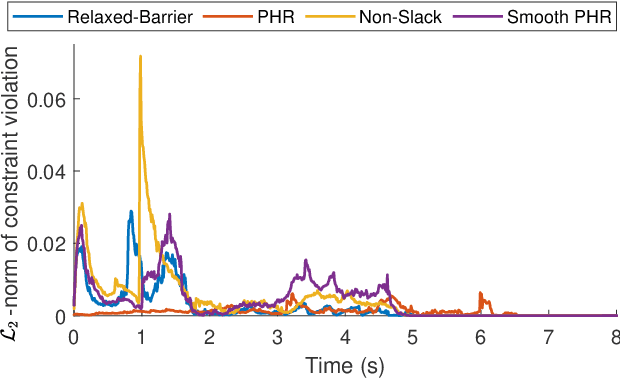
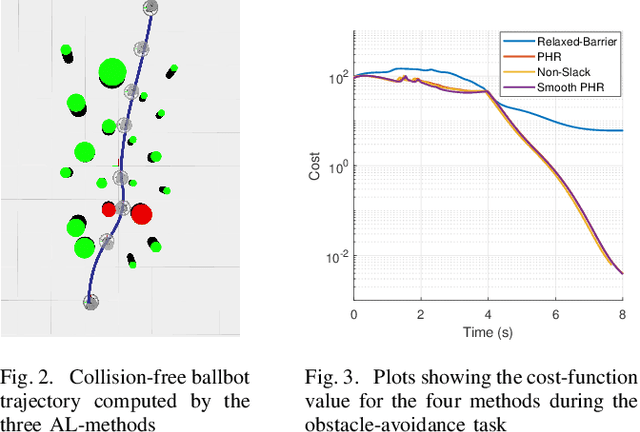
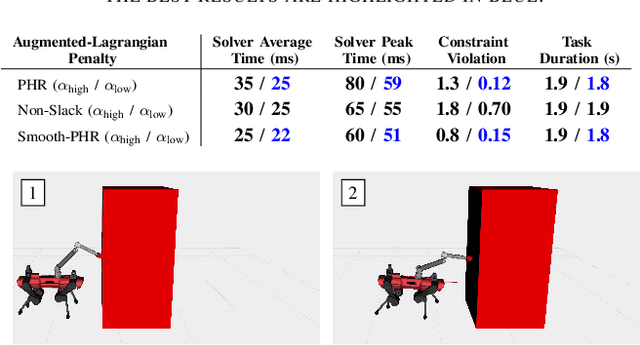
The Sequential Linear Quadratic (SLQ) algorithm is a continuous-time variant of the well-known Differential Dynamic Programming (DDP) technique with a Gauss-Newton Hessian approximation. This family of methods has gained popularity in the robotics community due to its efficiency in solving complex trajectory optimization problems. However, one major drawback of DDP-based formulations is their inability to properly incorporate path constraints. In this paper, we address this issue by devising a constrained SLQ algorithm that handles a mixture of constraints with a previously implemented projection technique and a new augmented-Lagrangian approach. By providing an appropriate multiplier update law, and by solving a single inner and outer loop iteration, we are able to retrieve suboptimal solutions at rates suitable for real-time model-predictive control applications. We particularly focus on the inequality-constrained case, where three augmented-Lagrangian penalty functions are introduced, along with their corresponding multiplier update rules. These are then benchmarked against a relaxed log-barrier formulation in a cart-pole swing up example, an obstacle-avoidance task, and an object-pushing task with a quadrupedal mobile manipulator.