 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOCI: Trajectory Optimization on Gaussian Splats
May 13, 2025



3D Gaussian Splatting (3DGS) has recently gained popularity as a faster alternative to Neural Radiance Fields (NeRFs) in 3D reconstruction and view synthesis methods. Leveraging the spatial information encoded in 3DGS, this work proposes FOCI (Field Overlap Collision Integral), an algorithm that is able to optimize trajectories directly on the Gaussians themselves. FOCI leverages a novel and interpretable collision formulation for 3DGS using the notion of the overlap integral between Gaussians. Contrary to other approaches, which represent the robot with conservative bounding boxes that underestimate the traversability of the environment, we propose to represent the environment and the robot as Gaussian Splats. This not only has desirable computational properties, but also allows for orientation-aware planning, allowing the robot to pass through very tight and narrow spaces. We extensively test our algorithm in both synthetic and real Gaussian Splats, showcasing that collision-free trajectories for the ANYmal legged robot that can be computed in a few seconds, even with hundreds of thousands of Gaussians making up the environment. The project page and code are available at https://rffr.leggedrobotics.com/works/foci/
Continuous-Time State Estimation Methods in Robotics: A Survey
Nov 06, 2024



Accurate, efficient, and robust state estimation is more important than ever in robotics as the variety of platforms and complexity of tasks continue to grow. Historically, discrete-time filters and smoothers have been the dominant approach, in which the estimated variables are states at discrete sample times. The paradigm of continuous-time state estimation proposes an alternative strategy by estimating variables that express the state as a continuous function of time, which can be evaluated at any query time. Not only can this benefit downstream tasks such as planning and control, but it also significantly increases estimator performance and flexibility, as well as reduces sensor preprocessing and interfacing complexity. Despite this, continuous-time methods remain underutilized, potentially because they are less well-known within robotics. To remedy this, this work presents a unifying formulation of these methods and the most exhaustive literature review to date, systematically categorizing prior work by methodology, application, state variables, historical context, and theoretical contribution to the field. By surveying splines and Gaussian processes together and contextualizing works from other research domains, this work identifies and analyzes open problems in continuous-time state estimation and suggests new research directions.
DiffSim2Real: Deploying Quadrupedal Locomotion Policies Purely Trained in Differentiable Simulation
Nov 04, 2024

Differentiable simulators provide analytic gradients, enabling more sample-efficient learning algorithms and paving the way for data intensive learning tasks such as learning from images. In this work, we demonstrate that locomotion policies trained with analytic gradients from a differentiable simulator can be successfully transferred to the real world. Typically, simulators that offer informative gradients lack the physical accuracy needed for sim-to-real transfer, and vice-versa. A key factor in our success is a smooth contact model that combines informative gradients with physical accuracy, ensuring effective transfer of learned behaviors. To the best of our knowledge, this is the first time a real quadrupedal robot is able to locomote after training exclusively in a differentiable simulation.
PRIMER: Perception-Aware Robust Learning-based Multiagent Trajectory Planner
Jun 14, 2024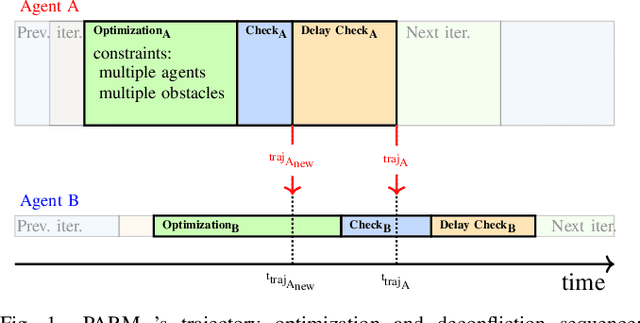
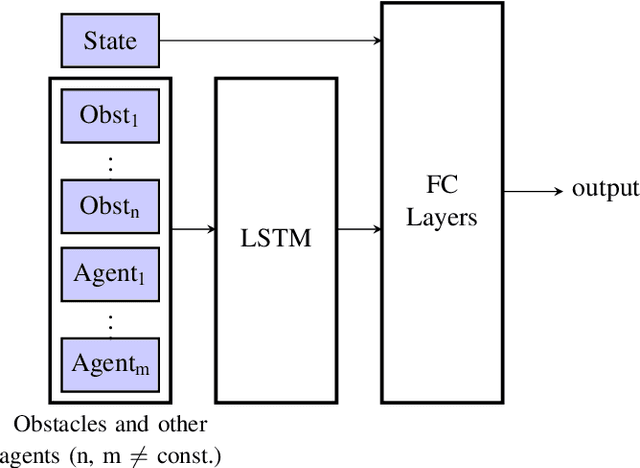
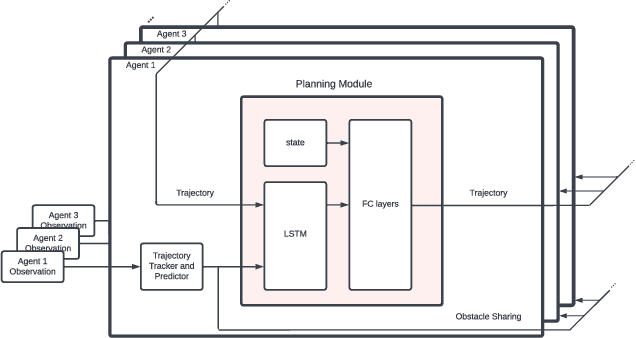

In decentralized multiagent trajectory planners, agents need to communicate and exchange their positions to generate collision-free trajectories. However, due to localization errors/uncertainties, trajectory deconfliction can fail even if trajectories are perfectly shared between agents. To address this issue, we first present PARM and PARM*, perception-aware, decentralized, asynchronous multiagent trajectory planners that enable a team of agents to navigate uncertain environments while deconflicting trajectories and avoiding obstacles using perception information. PARM* differs from PARM as it is less conservative, using more computation to find closer-to-optimal solutions. While these methods achieve state-of-the-art performance, they suffer from high computational costs as they need to solve large optimization problems onboard, making it difficult for agents to replan at high rates. To overcome this challenge, we present our second key contribution, PRIMER, a learning-based planner trained with imitation learning (IL) using PARM* as the expert demonstrator. PRIMER leverages the low computational requirements at deployment of neural networks and achieves a computation speed up to 5500 times faster than optimization-based approaches.
Learning Quadrupedal Locomotion via Differentiable Simulation
Apr 03, 2024



The emergence of differentiable simulators enabling analytic gradient computation has motivated a new wave of learning algorithms that hold the potential to significantly increase sample efficiency over traditional Reinforcement Learning (RL) methods. While recent research has demonstrated performance gains in scenarios with comparatively smooth dynamics and, thus, smooth optimization landscapes, research on leveraging differentiable simulators for contact-rich scenarios, such as legged locomotion, is scarce. This may be attributed to the discontinuous nature of contact, which introduces several challenges to optimizing with analytic gradients. The purpose of this paper is to determine if analytic gradients can be beneficial even in the face of contact. Our investigation focuses on the effects of different soft and hard contact models on the learning process, examining optimization challenges through the lens of contact simulation. We demonstrate the viability of employing analytic gradients to learn physically plausible locomotion skills with a quadrupedal robot using Short-Horizon Actor-Critic (SHAC), a learning algorithm leveraging analytic gradients, and draw a comparison to a state-of-the-art RL algorithm, Proximal Policy Optimization (PPO), to understand the benefits of analytic gradients.
RAYEN: Imposition of Hard Convex Constraints on Neural Networks
Jul 17, 2023



This paper presents RAYEN, a framework to impose hard convex constraints on the output or latent variable of a neural network. RAYEN guarantees that, for any input or any weights of the network, the constraints are satisfied at all times. Compared to other approaches, RAYEN does not perform a computationally-expensive orthogonal projection step onto the feasible set, does not rely on soft constraints (which do not guarantee the satisfaction of the constraints at test time), does not use conservative approximations of the feasible set, and does not perform a potentially slow inner gradient descent correction to enforce the constraints. RAYEN supports any combination of linear, convex quadratic, second-order cone (SOC), and linear matrix inequality (LMI) constraints, achieving a very small computational overhead compared to unconstrained networks. For example, it is able to impose 1K quadratic constraints on a 1K-dimensional variable with an overhead of less than 8 ms, and an LMI constraint with 300x300 dense matrices on a 10K-dimensional variable in less than 12 ms. When used in neural networks that approximate the solution of constrained optimization problems, RAYEN achieves computation times between 20 and 7468 times faster than state-of-the-art algorithms, while guaranteeing the satisfaction of the constraints at all times and obtaining a cost very close to the optimal one.
Robust MADER: Decentralized Multiagent Trajectory Planner Robust to Communication Delay in Dynamic Environments
Mar 10, 2023
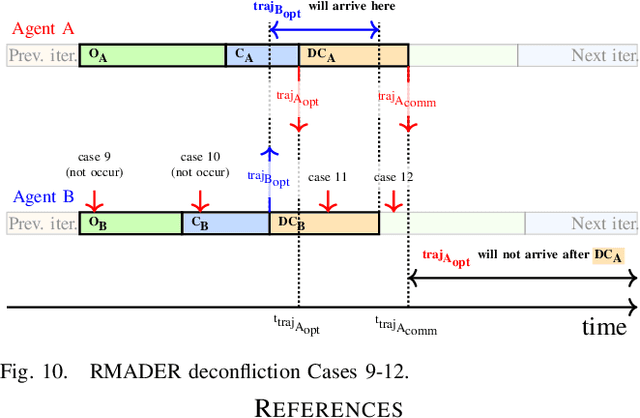

Communication delays can be catastrophic for multiagent systems. However, most existing state-of-the-art multiagent trajectory planners assume perfect communication and therefore lack a strategy to rectify this issue in real-world environments. To address this challenge, we propose Robust MADER (RMADER), a decentralized, asynchronous multiagent trajectory planner robust to communication delay. By always keeping a guaranteed collision-free trajectory and performing a delay check step, RMADER is able to guarantee safety even under communication delay. We perform an in-depth analysis of trajectory deconfliction among agents, extensive benchmark studies, and hardware flight experiments with multiple dynamic obstacles. We show that RMADER outperforms existing approaches by achieving a 100% success rate of collision-free trajectory generation, whereas the next best asynchronous decentralized method only achieves 83% success.
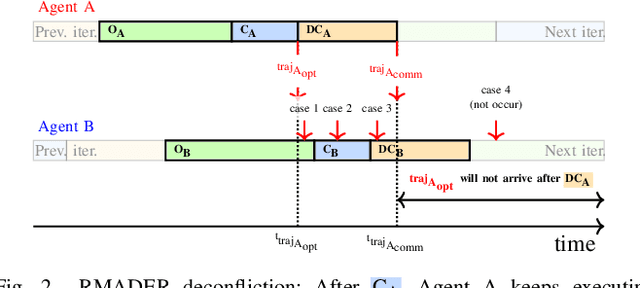
Robust MADER: Decentralized and Asynchronous Multiagent Trajectory Planner Robust to Communication Delay
Oct 06, 2022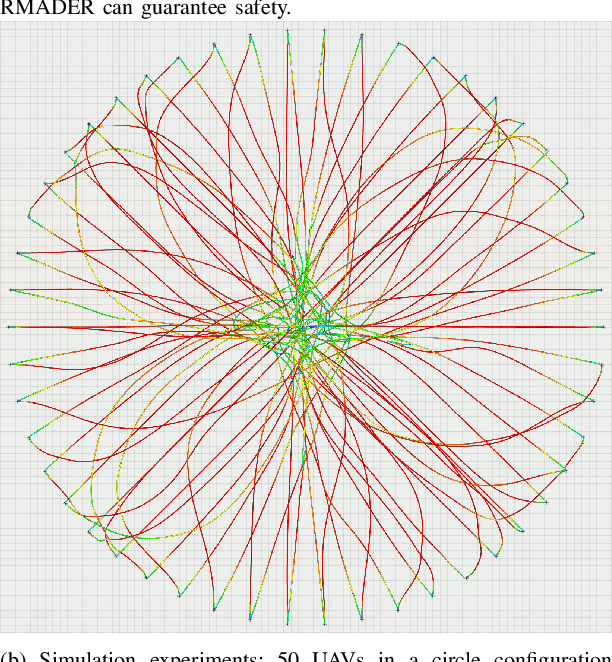
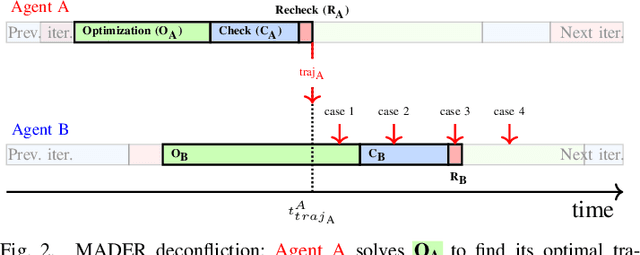
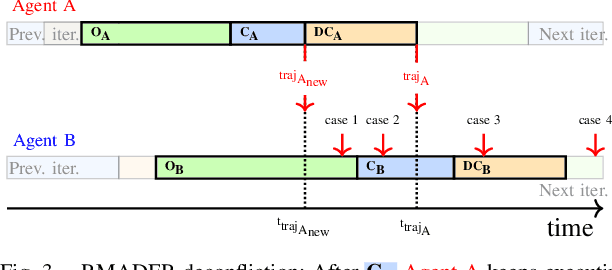
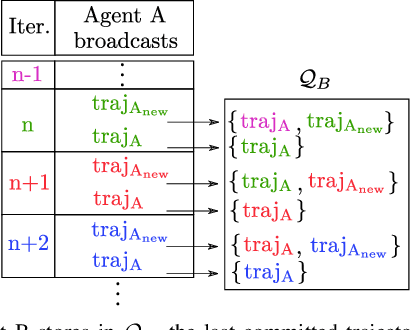
Although communication delays can disrupt multiagent systems, most of the existing multiagent trajectory planners lack a strategy to address this issue. State-of-the-art approaches typically assume perfect communication environments, which is hardly realistic in real-world experiments. This paper presents Robust MADER (RMADER), a decentralized and asynchronous multiagent trajectory planner that can handle communication delays among agents. By broadcasting both the newly optimized trajectory and the committed trajectory, and by performing a delay check step, RMADER is able to guarantee safety even under communication delay. RMADER was validated through extensive simulation and hardware flight experiments and achieved a 100% success rate of collision-free trajectory generation, outperforming state-of-the-art approaches.
Deep-PANTHER: Learning-Based Perception-Aware Trajectory Planner in Dynamic Environments
Sep 02, 2022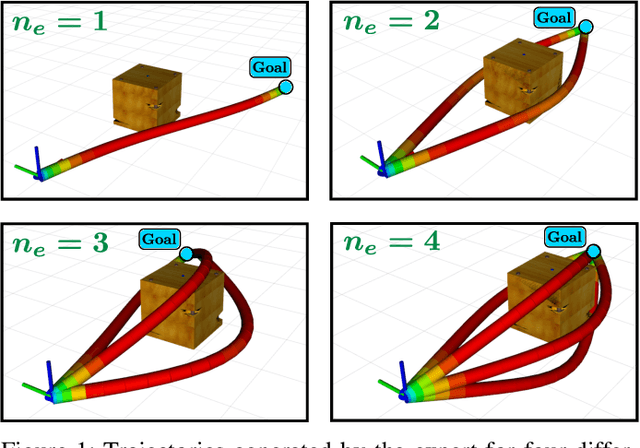
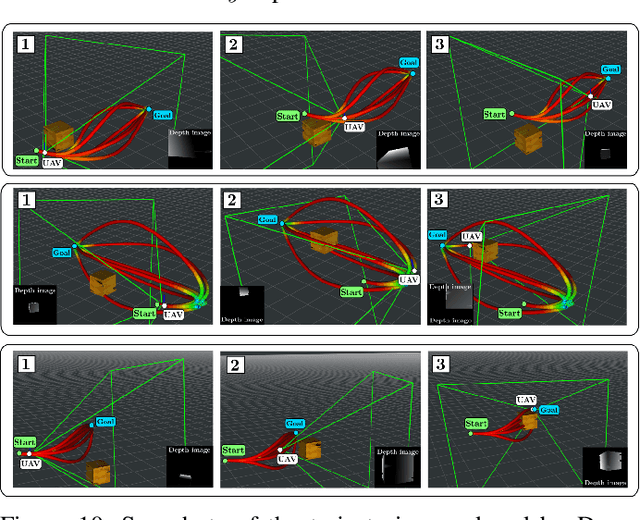
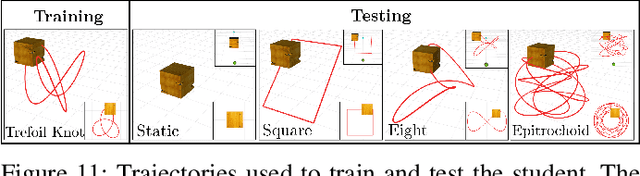
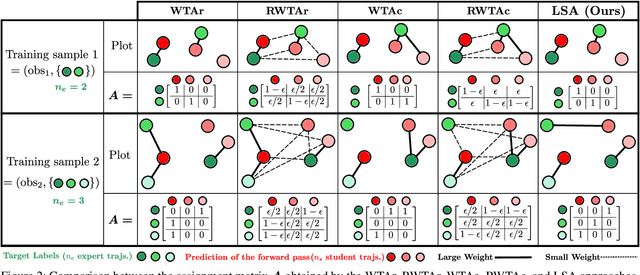
This paper presents Deep-PANTHER, a learning-based perception-aware trajectory planner for unmanned aerial vehicles (UAVs) in dynamic environments. Given the current state of the UAV, and the predicted trajectory and size of the obstacle, Deep-PANTHER generates multiple trajectories to avoid a dynamic obstacle while simultaneously maximizing its presence in the field of view (FOV) of the onboard camera. To obtain a computationally tractable real-time solution, imitation learning is leveraged to train a Deep-PANTHER policy using demonstrations provided by a multimodal optimization-based expert. Extensive simulations show replanning times that are two orders of magnitude faster than the optimization-based expert, while achieving a similar cost. By ensuring that each expert trajectory is assigned to one distinct student trajectory in the loss function, Deep-PANTHER can also capture the multimodality of the problem and achieve a mean squared error (MSE) loss with respect to the expert that is up to 18 times smaller than state-of-the-art (Relaxed) Winner-Takes-All approaches. Deep-PANTHER is also shown to generalize well to obstacle trajectories that differ from the ones used in training.
NeBula: Quest for Robotic Autonomy in Challenging Environments; TEAM CoSTAR at the DARPA Subterranean Challenge
Mar 28, 2021

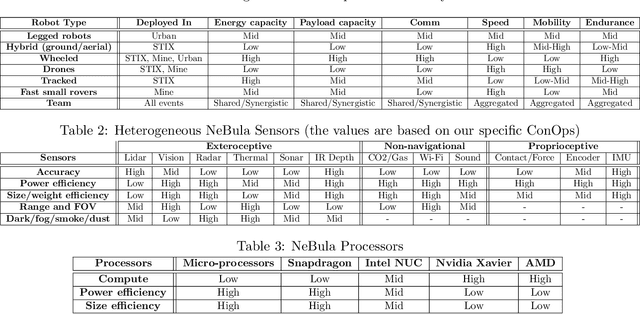
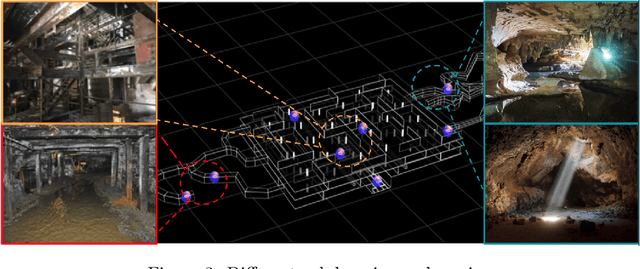
This paper presents and discusses algorithms, hardware, and software architecture developed by the TEAM CoSTAR (Collaborative SubTerranean Autonomous Robots), competing in the DARPA Subterranean Challenge. Specifically, it presents the techniques utilized within the Tunnel (2019) and Urban (2020) competitions, where CoSTAR achieved 2nd and 1st place, respectively. We also discuss CoSTAR's demonstrations in Martian-analog surface and subsurface (lava tubes) exploration. The paper introduces our autonomy solution, referred to as NeBula (Networked Belief-aware Perceptual Autonomy). NeBula is an uncertainty-aware framework that aims at enabling resilient and modular autonomy solutions by performing reasoning and decision making in the belief space (space of probability distributions over the robot and world states). We discuss various components of the NeBula framework, including: (i) geometric and semantic environment mapping; (ii) a multi-modal positioning system; (iii) traversability analysis and local planning; (iv) global motion planning and exploration behavior; (i) risk-aware mission planning; (vi) networking and decentralized reasoning; and (vii) learning-enabled adaptation. We discuss the performance of NeBula on several robot types (e.g. wheeled, legged, flying), in various environments. We discuss the specific results and lessons learned from fielding this solution in the challenging courses of the DARPA Subterranean Challenge competition.