 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViserDex: Visual Sim-to-Real for Robust Dexterous In-hand Reorientation
Apr 13, 2026In-hand object reorientation requires precise estimation of the object pose to handle complex task dynamics. While RGB sensing offers rich semantic cues for pose tracking, existing solutions rely on multi-camera setups or costly ray tracing. We present a sim-to-real framework for monocular RGB in-hand reorientation that integrates 3D Gaussian Splatting (3DGS) to bridge the visual sim-to-real gap. Our key insight is performing domain randomization in the Gaussian representation space: by applying physically consistent, pre-rendering augmentations to 3D Gaussians, we generate photorealistic, randomized visual data for object pose estimation. The manipulation policy is trained using curriculum-based reinforcement learning with teacher-student distillation, enabling efficient learning of complex behaviors. Importantly, both perception and control models can be trained independently on consumer-grade hardware, eliminating the need for large compute clusters. Experiments show that the pose estimator trained with 3DGS data outperforms those trained using conventional rendering data in challenging visual environments. We validate the system on a physical multi-fingered hand equipped with an RGB camera, demonstrating robust reorientation of five diverse objects even under challenging lighting conditions. Our results highlight Gaussian splatting as a practical path for RGB-only dexterous manipulation. For videos of the hardware deployments and additional supplementary materials, please refer to the project website: https://rffr.leggedrobotics.com/works/viserdex/
FOCI: Trajectory Optimization on Gaussian Splats
May 13, 2025



3D Gaussian Splatting (3DGS) has recently gained popularity as a faster alternative to Neural Radiance Fields (NeRFs) in 3D reconstruction and view synthesis methods. Leveraging the spatial information encoded in 3DGS, this work proposes FOCI (Field Overlap Collision Integral), an algorithm that is able to optimize trajectories directly on the Gaussians themselves. FOCI leverages a novel and interpretable collision formulation for 3DGS using the notion of the overlap integral between Gaussians. Contrary to other approaches, which represent the robot with conservative bounding boxes that underestimate the traversability of the environment, we propose to represent the environment and the robot as Gaussian Splats. This not only has desirable computational properties, but also allows for orientation-aware planning, allowing the robot to pass through very tight and narrow spaces. We extensively test our algorithm in both synthetic and real Gaussian Splats, showcasing that collision-free trajectories for the ANYmal legged robot that can be computed in a few seconds, even with hundreds of thousands of Gaussians making up the environment. The project page and code are available at https://rffr.leggedrobotics.com/works/foci/
Radiance Fields for Robotic Teleoperation
Jul 29, 2024Radiance field methods such as Neural Radiance Fields (NeRFs) or 3D Gaussian Splatting (3DGS), have revolutionized graphics and novel view synthesis. Their ability to synthesize new viewpoints with photo-realistic quality, as well as capture complex volumetric and specular scenes, makes them an ideal visualization for robotic teleoperation setups. Direct camera teleoperation provides high-fidelity operation at the cost of maneuverability, while reconstruction-based approaches offer controllable scenes with lower fidelity. With this in mind, we propose replacing the traditional reconstruction-visualization components of the robotic teleoperation pipeline with online Radiance Fields, offering highly maneuverable scenes with photorealistic quality. As such, there are three main contributions to state of the art: (1) online training of Radiance Fields using live data from multiple cameras, (2) support for a variety of radiance methods including NeRF and 3DGS, (3) visualization suite for these methods including a virtual reality scene. To enable seamless integration with existing setups, these components were tested with multiple robots in multiple configurations and were displayed using traditional tools as well as the VR headset. The results across methods and robots were compared quantitatively to a baseline of mesh reconstruction, and a user study was conducted to compare the different visualization methods. For videos and code, check out https://leggedrobotics.github.io/rffr.github.io/.
ICGNet: A Unified Approach for Instance-Centric Grasping
Jan 18, 2024



Accurate grasping is the key to several robotic tasks including assembly and household robotics. Executing a successful grasp in a cluttered environment requires multiple levels of scene understanding: First, the robot needs to analyze the geometric properties of individual objects to find feasible grasps. These grasps need to be compliant with the local object geometry. Second, for each proposed grasp, the robot needs to reason about the interactions with other objects in the scene. Finally, the robot must compute a collision-free grasp trajectory while taking into account the geometry of the target object. Most grasp detection algorithms directly predict grasp poses in a monolithic fashion, which does not capture the composability of the environment. In this paper, we introduce an end-to-end architecture for object-centric grasping. The method uses pointcloud data from a single arbitrary viewing direction as an input and generates an instance-centric representation for each partially observed object in the scene. This representation is further used for object reconstruction and grasp detection in cluttered table-top scenes. We show the effectiveness of the proposed method by extensively evaluating it against state-of-the-art methods on synthetic datasets, indicating superior performance for grasping and reconstruction. Additionally, we demonstrate real-world applicability by decluttering scenes with varying numbers of objects.
TULIP: Transformer for Upsampling of LiDAR Point Cloud
Dec 14, 2023



LiDAR Upsampling is a challenging task for the perception systems of robots and autonomous vehicles, due to the sparse and irregular structure of large-scale scene contexts. Recent works propose to solve this problem by converting LiDAR data from 3D Euclidean space into an image super-resolution problem in 2D image space. Although their methods can generate high-resolution range images with fine-grained details, the resulting 3D point clouds often blur out details and predict invalid points. In this paper, we propose TULIP, a new method to reconstruct high-resolution LiDAR point clouds from low-resolution LiDAR input. We also follow a range image-based approach but specifically modify the patch and window geometries of a Swin-Transformer-based network to better fit the characteristics of range images. We conducted several experiments on three different public real-world and simulated datasets. TULIP outperforms state-of-the-art methods in all relevant metrics and generates robust and more realistic point clouds than prior works.
Lidar Line Selection with Spatially-Aware Shapley Value for Cost-Efficient Depth Completion
Mar 21, 2023Lidar is a vital sensor for estimating the depth of a scene. Typical spinning lidars emit pulses arranged in several horizontal lines and the monetary cost of the sensor increases with the number of these lines. In this work, we present the new problem of optimizing the positioning of lidar lines to find the most effective configuration for the depth completion task. We propose a solution to reduce the number of lines while retaining the up-to-the-mark quality of depth completion. Our method consists of two components, (1) line selection based on the marginal contribution of a line computed via the Shapley value and (2) incorporating line position spread to take into account its need to arrive at image-wide depth completion. Spatially-aware Shapley values (SaS) succeed in selecting line subsets that yield a depth accuracy comparable to the full lidar input while using just half of the lines.
P3Depth: Monocular Depth Estimation with a Piecewise Planarity Prior
Apr 05, 2022


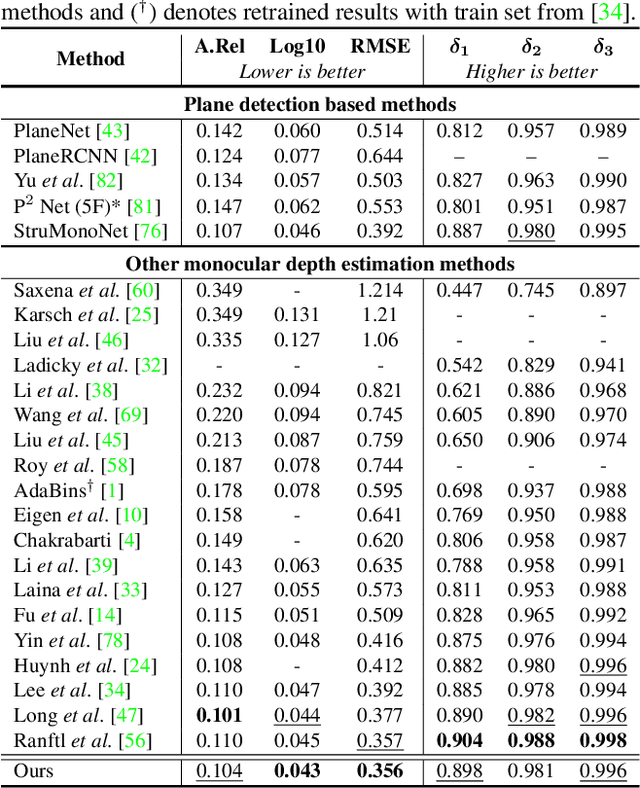
Monocular depth estimation is vital for scene understanding and downstream tasks. We focus on the supervised setup, in which ground-truth depth is available only at training time. Based on knowledge about the high regularity of real 3D scenes, we propose a method that learns to selectively leverage information from coplanar pixels to improve the predicted depth. In particular, we introduce a piecewise planarity prior which states that for each pixel, there is a seed pixel which shares the same planar 3D surface with the former. Motivated by this prior, we design a network with two heads. The first head outputs pixel-level plane coefficients, while the second one outputs a dense offset vector field that identifies the positions of seed pixels. The plane coefficients of seed pixels are then used to predict depth at each position. The resulting prediction is adaptively fused with the initial prediction from the first head via a learned confidence to account for potential deviations from precise local planarity. The entire architecture is trained end-to-end thanks to the differentiability of the proposed modules and it learns to predict regular depth maps, with sharp edges at occlusion boundaries. An extensive evaluation of our method shows that we set the new state of the art in supervised monocular depth estimation, surpassing prior methods on NYU Depth-v2 and on the Garg split of KITTI. Our method delivers depth maps that yield plausible 3D reconstructions of the input scenes. Code is available at: https://github.com/SysCV/P3Depth
Don't Forget The Past: Recurrent Depth Estimation from Monocular Video
Jan 08, 2020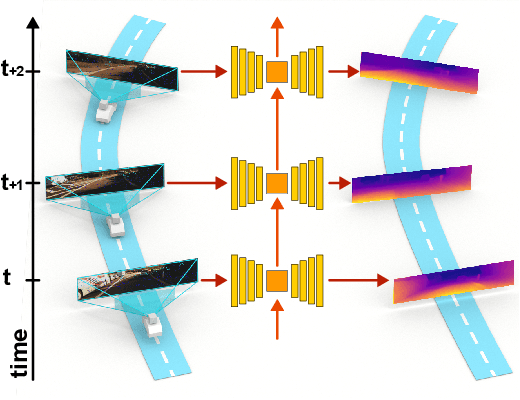
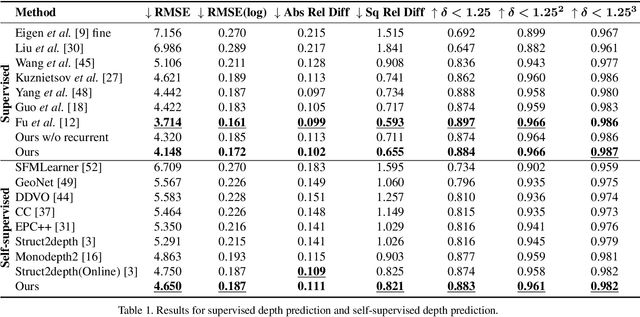
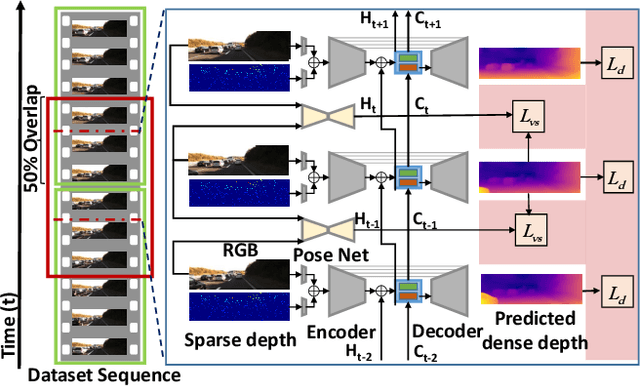
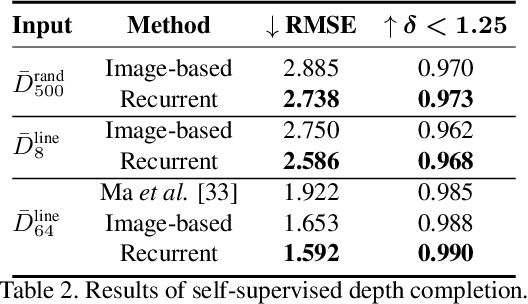
Autonomous cars need continuously updated depth information. Thus far, the depth is mostly estimated independently for a single frame at a time, even if the method starts from video input. Our method produces a time series of depth maps, which makes it an ideal candidate for online learning approaches. In particular, we put three different types of depth estimation (supervised depth prediction, self-supervised depth prediction, and self-supervised depth completion) into a common framework. We integrate the corresponding networks with a convolutional LSTM such that the spatiotemporal structures of depth across frames can be exploited to yield a more accurate depth estimation. Our method is flexible. It can be applied to monocular videos only or be combined with different types of sparse depth patterns. We carefully study the architecture of the recurrent network and its training strategy. We are first to successfully exploit recurrent networks for real-time self-supervised monocular depth estimation and completion. Extensive experiments show that our recurrent method outperforms its image-based counterpart consistently and significantly in both self-supervised scenarios. It also outperforms previous depth estimation methods of the three popular groups.
Self-supervised Object Motion and Depth Estimation from Video
Dec 09, 2019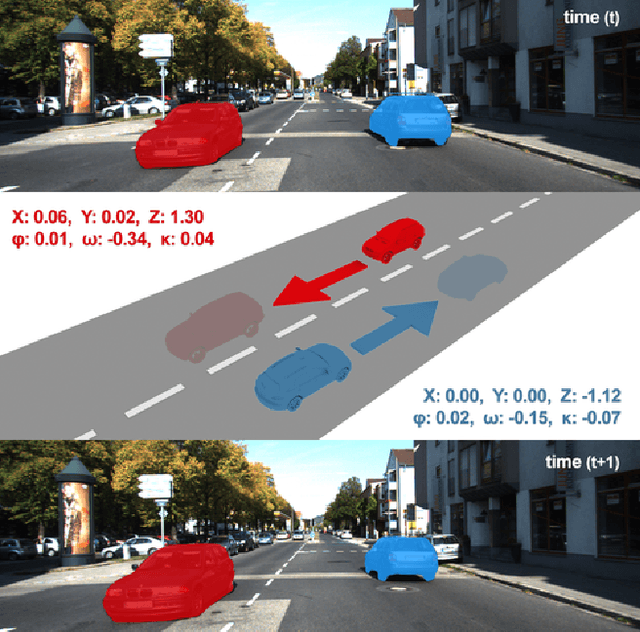
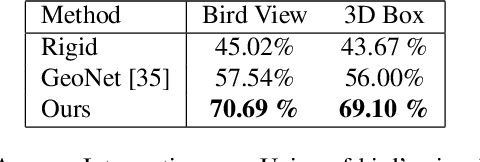
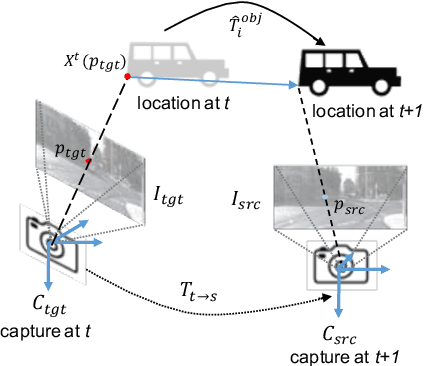
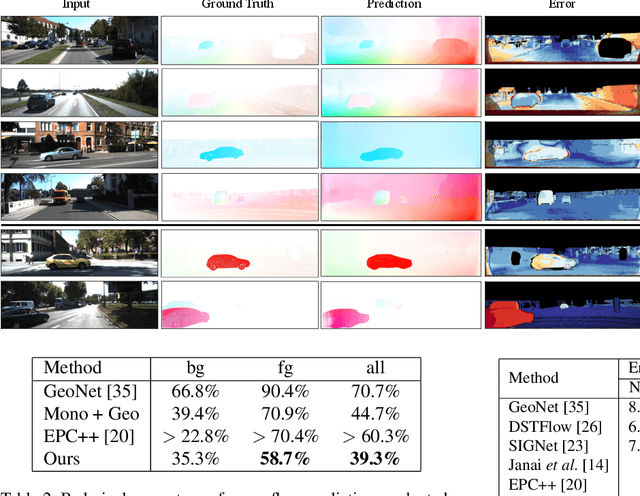
We present a self-supervised learning framework to estimate the individual object motion and monocular depth from video. We model the object motion as a 6 degree-of-freedom rigid-body transformation. The instance segmentation mask is leveraged to introduce the information of object. Compared with methods which predict pixel-wise optical flow map to model the motion, our approach significantly reduces the number of values to be estimated. Furthermore, our system eliminates the scale ambiguity of predictions, through employing the pre-computed camera ego-motion and the left-right photometric consistency. Experiments on KITTI driving dataset demonstrate our system is capable to capture the object motion without external annotation, and contribute to the depth prediction in dynamic area. Our system outperforms earlier self-supervised approaches in terms of 3D scene flow prediction, and produces comparable results on optical flow estimation.