 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Object Motion and Depth Estimation from Video
Paper and Code
Dec 09, 2019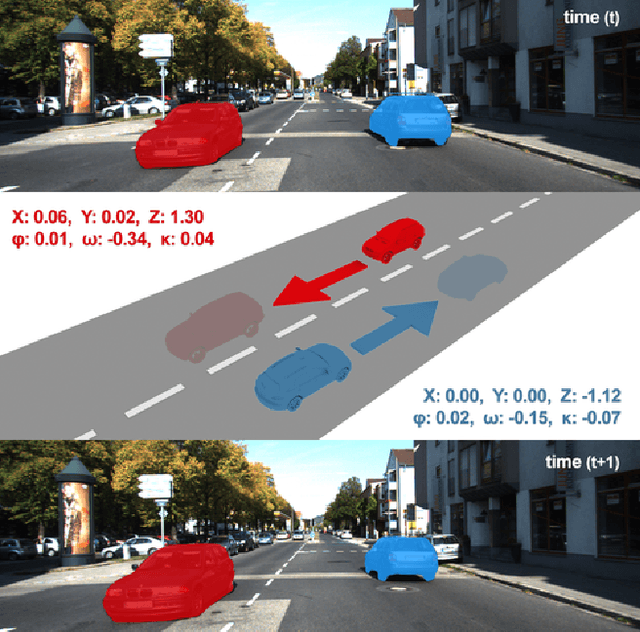
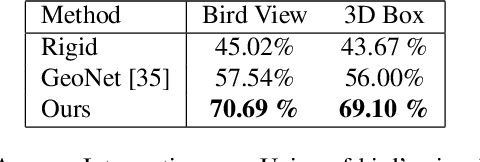
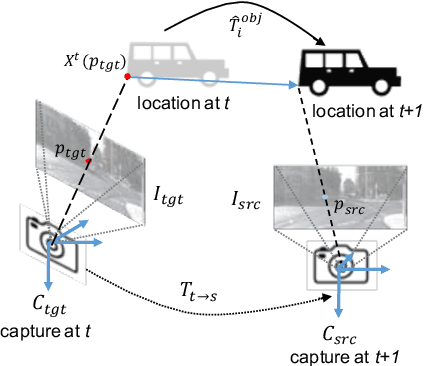
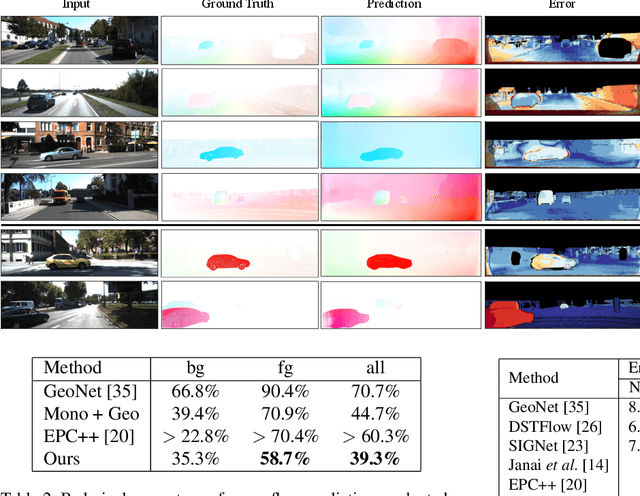
We present a self-supervised learning framework to estimate the individual object motion and monocular depth from video. We model the object motion as a 6 degree-of-freedom rigid-body transformation. The instance segmentation mask is leveraged to introduce the information of object. Compared with methods which predict pixel-wise optical flow map to model the motion, our approach significantly reduces the number of values to be estimated. Furthermore, our system eliminates the scale ambiguity of predictions, through employing the pre-computed camera ego-motion and the left-right photometric consistency. Experiments on KITTI driving dataset demonstrate our system is capable to capture the object motion without external annotation, and contribute to the depth prediction in dynamic area. Our system outperforms earlier self-supervised approaches in terms of 3D scene flow prediction, and produces comparable results on optical flow estimation.