 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Accurate and Human-Like Driving using Semantic Maps and Attention
Jul 10, 2020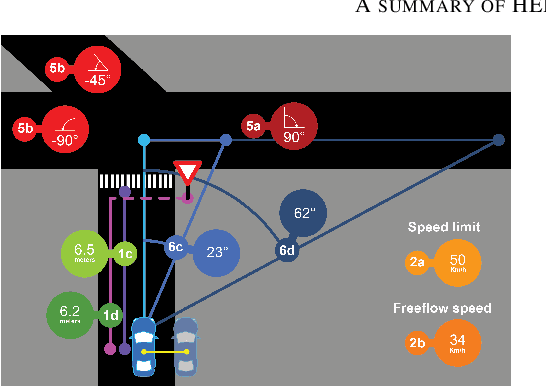
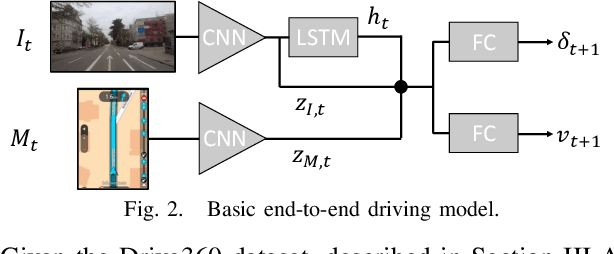
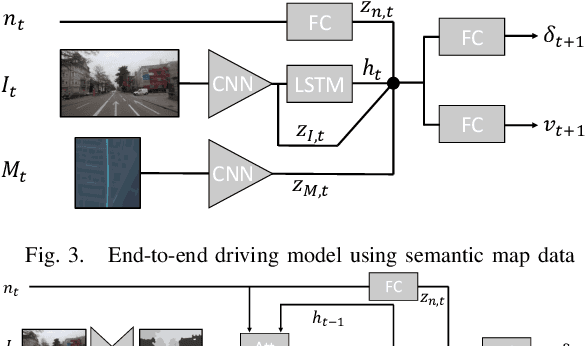
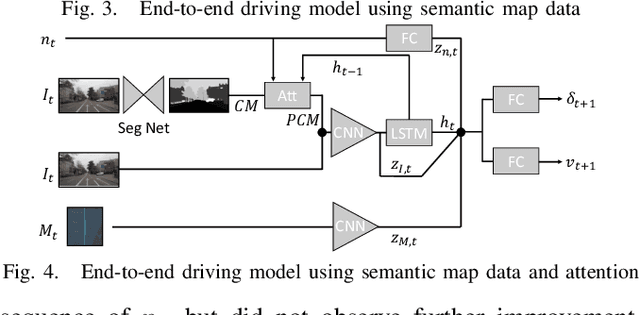
This paper investigates how end-to-end driving models can be improved to drive more accurately and human-like. To tackle the first issue we exploit semantic and visual maps from HERE Technologies and augment the existing Drive360 dataset with such. The maps are used in an attention mechanism that promotes segmentation confidence masks, thus focusing the network on semantic classes in the image that are important for the current driving situation. Human-like driving is achieved using adversarial learning, by not only minimizing the imitation loss with respect to the human driver but by further defining a discriminator, that forces the driving model to produce action sequences that are human-like. Our models are trained and evaluated on the Drive360 + HERE dataset, which features 60 hours and 3000 km of real-world driving data. Extensive experiments show that our driving models are more accurate and behave more human-like than previous methods.
Self-supervised Object Motion and Depth Estimation from Video
Dec 09, 2019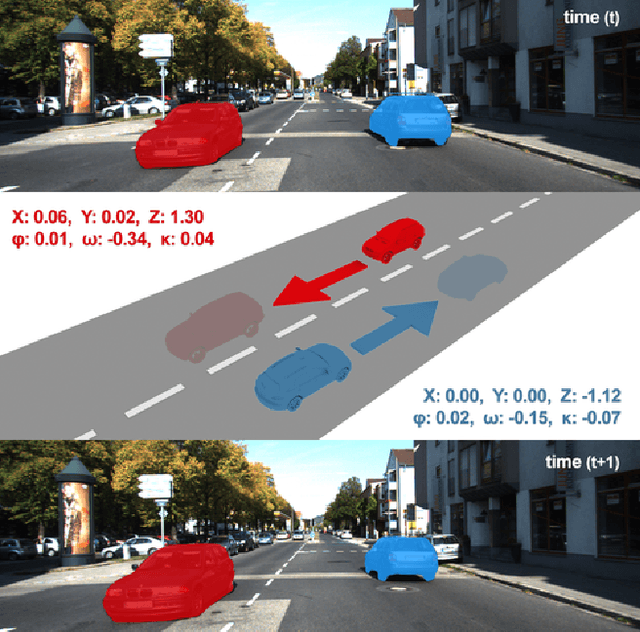
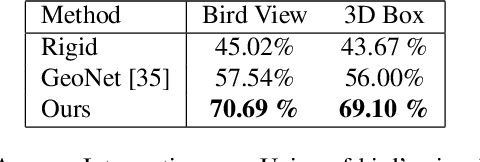
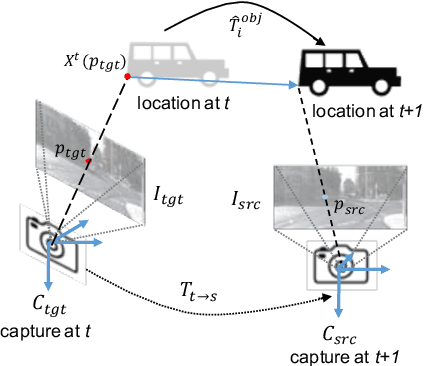
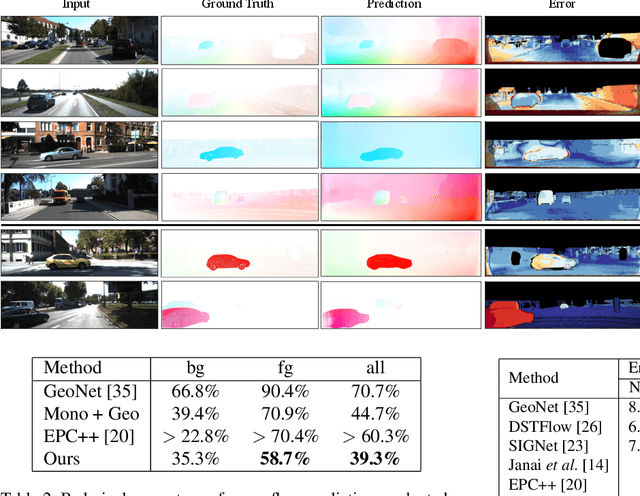
We present a self-supervised learning framework to estimate the individual object motion and monocular depth from video. We model the object motion as a 6 degree-of-freedom rigid-body transformation. The instance segmentation mask is leveraged to introduce the information of object. Compared with methods which predict pixel-wise optical flow map to model the motion, our approach significantly reduces the number of values to be estimated. Furthermore, our system eliminates the scale ambiguity of predictions, through employing the pre-computed camera ego-motion and the left-right photometric consistency. Experiments on KITTI driving dataset demonstrate our system is capable to capture the object motion without external annotation, and contribute to the depth prediction in dynamic area. Our system outperforms earlier self-supervised approaches in terms of 3D scene flow prediction, and produces comparable results on optical flow estimation.
Learning a Curve Guardian for Motorcycles
Jul 12, 2019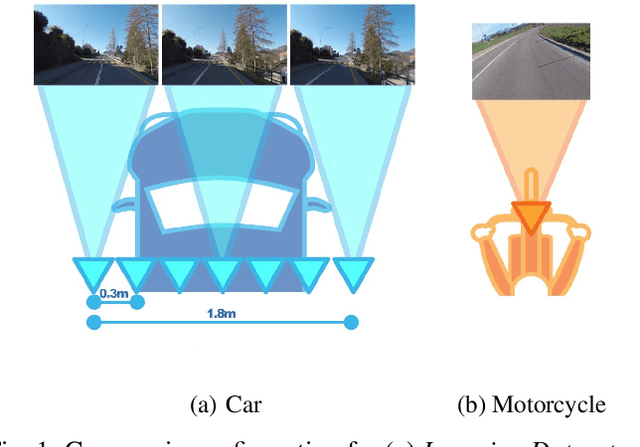
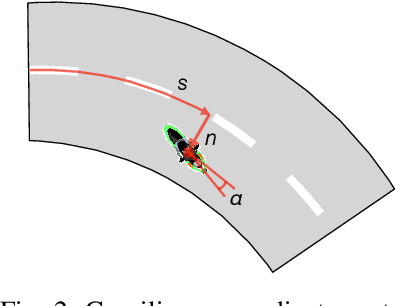
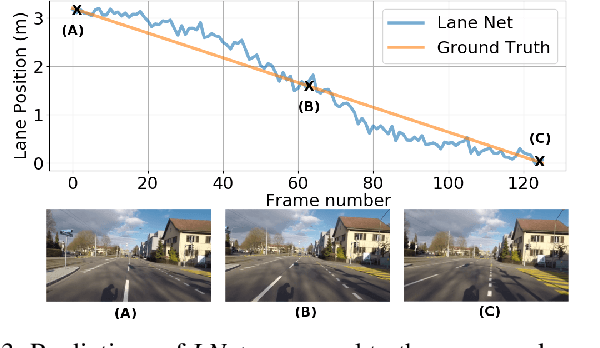
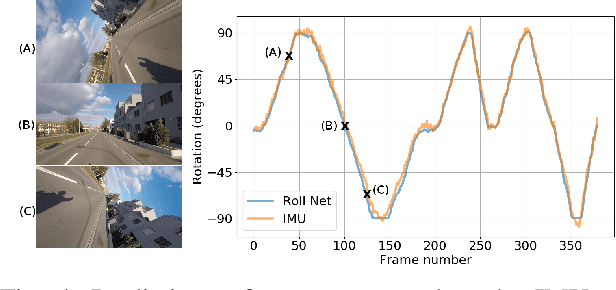
Up to 17% of all motorcycle accidents occur when the rider is maneuvering through a curve and the main cause of curve accidents can be attributed to inappropriate speed and wrong intra-lane position of the motorcycle. Existing curve warning systems lack crucial state estimation components and do not scale well. We propose a new type of road curvature warning system for motorcycles, combining the latest advances in computer vision, optimal control and mapping technologies to alleviate these shortcomings. Our contributes are fourfold: 1) we predict the motorcycle's intra-lane position using a convolutional neural network (CNN), 2) we predict the motorcycle roll angle using a CNN, 3) we use an upgraded controller model that incorporates road incline for a more realistic model and prediction, 4) we design a scale-able system by utilizing HERE Technologies map database to obtain the accurate road geometry of the future path. In addition, we present two datasets that are used for training and evaluating of our system respectively, both datasets will be made publicly available. We test our system on a diverse set of real world scenarios and present a detailed case-study. We show that our system is able to predict more accurate and safer curve trajectories, and consequently warn and improve the safety for motorcyclists.
Learning Accurate, Comfortable and Human-like Driving
Mar 26, 2019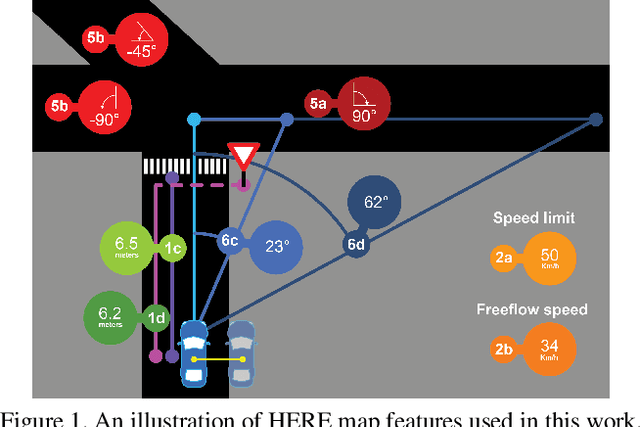

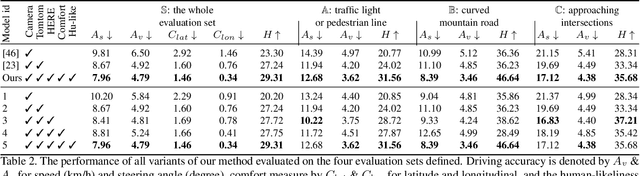
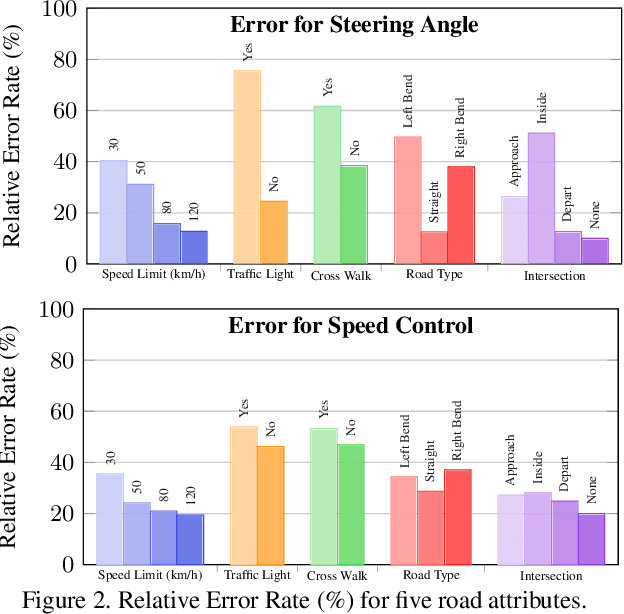
Autonomous vehicles are more likely to be accepted if they drive accurately, comfortably, but also similar to how human drivers would. This is especially true when autonomous and human-driven vehicles need to share the same road. The main research focus thus far, however, is still on improving driving accuracy only. This paper formalizes the three concerns with the aim of accurate, comfortable and human-like driving. Three contributions are made in this paper. First, numerical map data from HERE Technologies are employed for more accurate driving; a set of map features which are believed to be relevant to driving are engineered to navigate better. Second, the learning procedure is improved from a pointwise prediction to a sequence-based prediction and passengers' comfort measures are embedded into the learning algorithm. Finally, we take advantage of the advances in adversary learning to learn human-like driving; specifically, the standard L1 or L2 loss is augmented by an adversary loss which is based on a discriminator trained to distinguish between human driving and machine driving. Our model is trained and evaluated on the Drive360 dataset, which features 60 hours and 3000 km of real-world driving data. Extensive experiments show that our driving model is more accurate, more comfortable and behaves more like a human driver than previous methods. The resources of this work will be released on the project page.
Curriculum Model Adaptation with Synthetic and Real Data for Semantic Foggy Scene Understanding
Jan 05, 2019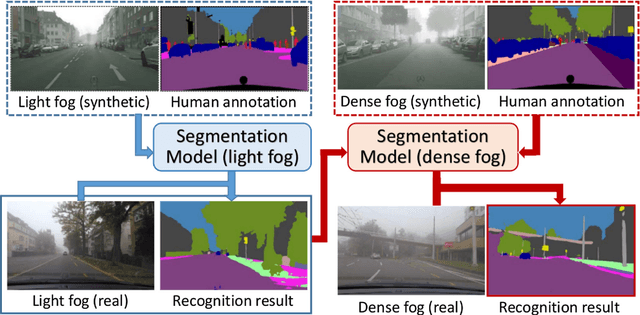
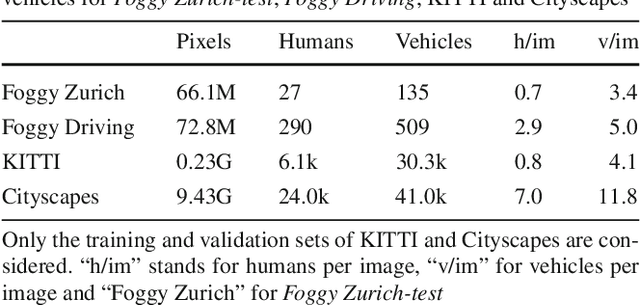

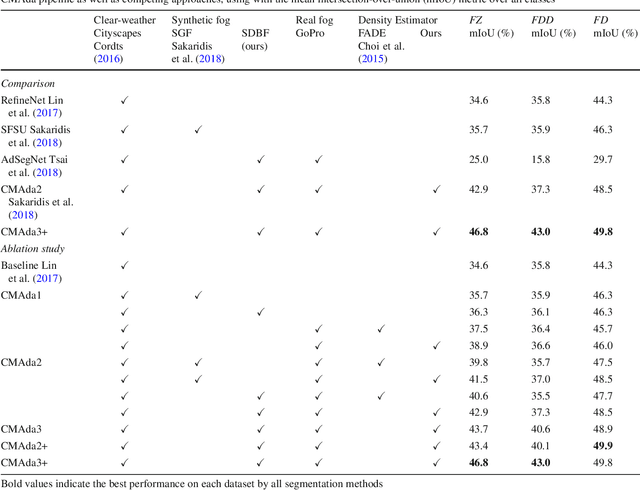
This work addresses the problem of semantic scene understanding under fog. Although marked progress has been made in semantic scene understanding, it is mainly concentrated on clear-weather scenes. Extending semantic segmentation methods to adverse weather conditions such as fog is crucial for outdoor applications. In this paper, we propose a novel method, named Curriculum Model Adaptation (CMAda), which gradually adapts a semantic segmentation model from light synthetic fog to dense real fog in multiple steps, using both labeled synthetic foggy data and unlabeled real foggy data. The method is based on the fact that the results of semantic segmentation in moderately adverse conditions (light fog) can be bootstrapped to solve the same problem in highly adverse conditions (dense fog). CMAda is extensible to other adverse conditions and provides a new paradigm for learning with synthetic data and unlabeled real data. In addition, we present three other main stand-alone contributions: 1) a novel method to add synthetic fog to real, clear-weather scenes using semantic input; 2) a new fog density estimator; 3) a novel fog densification method to densify the fog in real foggy scenes without using depth; and 4) the Foggy Zurich dataset comprising 3808 real foggy images, with pixel-level semantic annotations for 40 images under dense fog. Our experiments show that 1) our fog simulation and fog density estimator outperform their state-of-the-art counterparts with respect to the task of semantic foggy scene understanding (SFSU); 2) CMAda improves the performance of state-of-the-art models for SFSU significantly, benefiting both from our synthetic and real foggy data. The datasets and code are available at the project website.
End-to-End Learning of Driving Models with Surround-View Cameras and Route Planners
Aug 06, 2018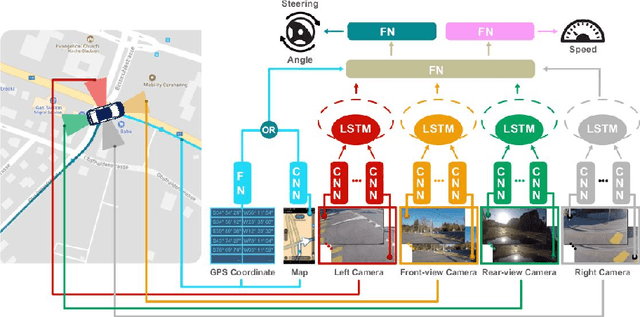
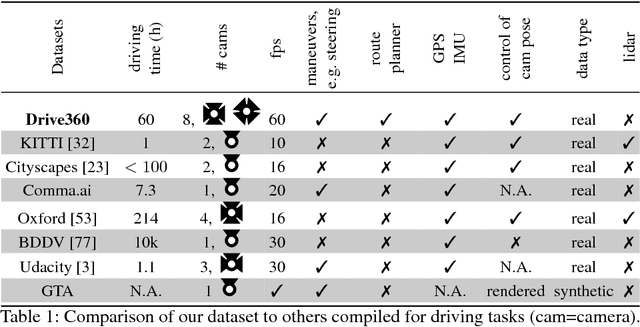
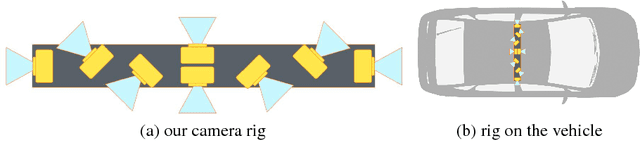

For human drivers, having rear and side-view mirrors is vital for safe driving. They deliver a more complete view of what is happening around the car. Human drivers also heavily exploit their mental map for navigation. Nonetheless, several methods have been published that learn driving models with only a front-facing camera and without a route planner. This lack of information renders the self-driving task quite intractable. We investigate the problem in a more realistic setting, which consists of a surround-view camera system with eight cameras, a route planner, and a CAN bus reader. In particular, we develop a sensor setup that provides data for a 360-degree view of the area surrounding the vehicle, the driving route to the destination, and low-level driving maneuvers (e.g. steering angle and speed) by human drivers. With such a sensor setup we collect a new driving dataset, covering diverse driving scenarios and varying weather/illumination conditions. Finally, we learn a novel driving model by integrating information from the surround-view cameras and the route planner. Two route planners are exploited: 1) by representing the planned routes on OpenStreetMap as a stack of GPS coordinates, and 2) by rendering the planned routes on TomTom Go Mobile and recording the progression into a video. Our experiments show that: 1) 360-degree surround-view cameras help avoid failures made with a single front-view camera, in particular for city driving and intersection scenarios; and 2) route planners help the driving task significantly, especially for steering angle prediction.
Model Adaptation with Synthetic and Real Data for Semantic Dense Foggy Scene Understanding
Aug 03, 2018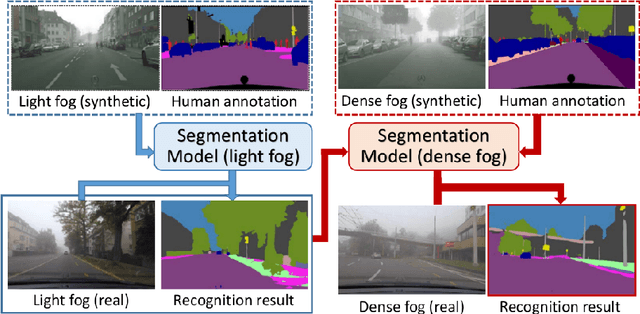



This work addresses the problem of semantic scene understanding under dense fog. Although considerable progress has been made in semantic scene understanding, it is mainly related to clear-weather scenes. Extending recognition methods to adverse weather conditions such as fog is crucial for outdoor applications. In this paper, we propose a novel method, named Curriculum Model Adaptation (CMAda), which gradually adapts a semantic segmentation model from light synthetic fog to dense real fog in multiple steps, using both synthetic and real foggy data. In addition, we present three other main stand-alone contributions: 1) a novel method to add synthetic fog to real, clear-weather scenes using semantic input; 2) a new fog density estimator; 3) the Foggy Zurich dataset comprising $3808$ real foggy images, with pixel-level semantic annotations for $16$ images with dense fog. Our experiments show that 1) our fog simulation slightly outperforms a state-of-the-art competing simulation with respect to the task of semantic foggy scene understanding (SFSU); 2) CMAda improves the performance of state-of-the-art models for SFSU significantly by leveraging unlabeled real foggy data. The datasets and code are publicly available.
Failure Prediction for Autonomous Driving
May 04, 2018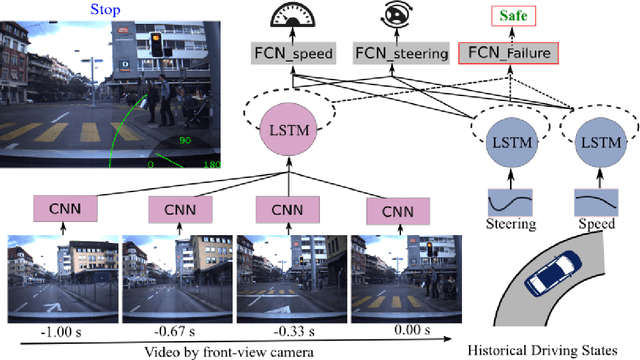
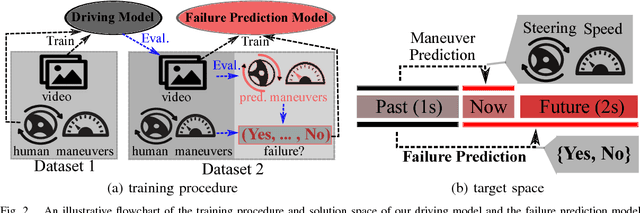
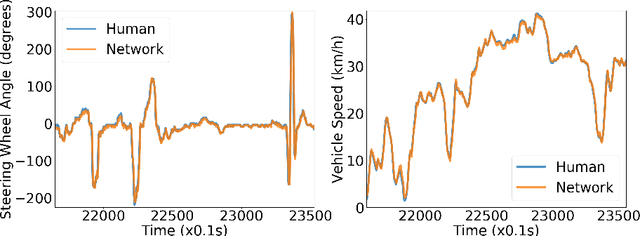
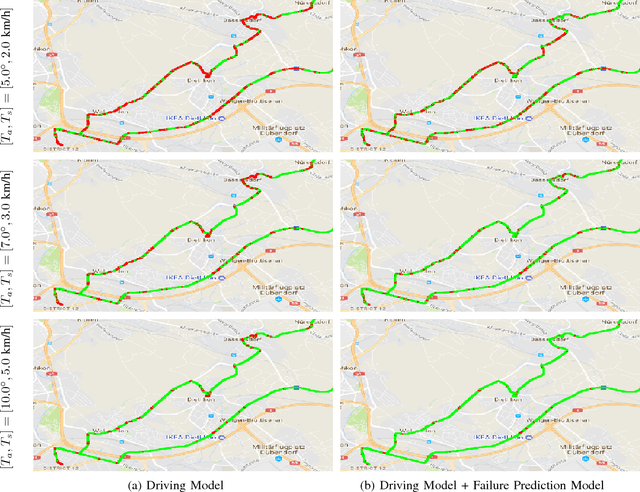
The primary focus of autonomous driving research is to improve driving accuracy. While great progress has been made, state-of-the-art algorithms still fail at times. Such failures may have catastrophic consequences. It therefore is important that automated cars foresee problems ahead as early as possible. This is also of paramount importance if the driver will be asked to take over. We conjecture that failures do not occur randomly. For instance, driving models may fail more likely at places with heavy traffic, at complex intersections, and/or under adverse weather/illumination conditions. This work presents a method to learn to predict the occurrence of these failures, i.e. to assess how difficult a scene is to a given driving model and to possibly give the human driver an early headsup. A camera-based driving model is developed and trained over real driving datasets. The discrepancies between the model's predictions and the human `ground-truth' maneuvers were then recorded, to yield the `failure' scores. Experimental results show that the failure score can indeed be learned and predicted. Thus, our prediction method is able to improve the overall safety of an automated driving model by alerting the human driver timely, leading to better human-vehicle collaborative driving.