 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tricycle Model to Accurately Control an Autonomous Racecar with Locked Differential
Dec 22, 2023In this paper, we present a novel formulation to model the effects of a locked differential on the lateral dynamics of an autonomous open-wheel racecar. The model is used in a Model Predictive Controller in which we included a micro-steps discretization approach to accurately linearize the dynamics and produce a prediction suitable for real-time implementation. The stability analysis of the model is presented, as well as a brief description of the overall planning and control scheme which includes an offline trajectory generation pipeline, an online local speed profile planner, and a low-level longitudinal controller. An improvement of the lateral path tracking is demonstrated in preliminary experimental results that have been produced on a Dallara AV-21 during the first Indy Autonomous Challenge event on the Monza F1 racetrack. Final adjustments and tuning have been performed in a high-fidelity simulator demonstrating the effectiveness of the solution when performing close to the tire limits.
Object-centric Cross-modal Feature Distillation for Event-based Object Detection
Nov 09, 2023Event cameras are gaining popularity due to their unique properties, such as their low latency and high dynamic range. One task where these benefits can be crucial is real-time object detection. However, RGB detectors still outperform event-based detectors due to the sparsity of the event data and missing visual details. In this paper, we develop a novel knowledge distillation approach to shrink the performance gap between these two modalities. To this end, we propose a cross-modality object detection distillation method that by design can focus on regions where the knowledge distillation works best. We achieve this by using an object-centric slot attention mechanism that can iteratively decouple features maps into object-centric features and corresponding pixel-features used for distillation. We evaluate our novel distillation approach on a synthetic and a real event dataset with aligned grayscale images as a teacher modality. We show that object-centric distillation allows to significantly improve the performance of the event-based student object detector, nearly halving the performance gap with respect to the teacher.
er.autopilot 1.0: The Full Autonomous Stack for Oval Racing at High Speeds
Oct 27, 2023



The Indy Autonomous Challenge (IAC) brought together for the first time in history nine autonomous racing teams competing at unprecedented speed and in head-to-head scenario, using independently developed software on open-wheel racecars. This paper presents the complete software architecture used by team TII EuroRacing (TII-ER), covering all the modules needed to avoid static obstacles, perform active overtakes and reach speeds above 75 m/s (270 km/h). In addition to the most common modules related to perception, planning, and control, we discuss the approaches used for vehicle dynamics modelling, simulation, telemetry, and safety. Overall results and the performance of each module are described, as well as the lessons learned during the first two events of the competition on oval tracks, where the team placed respectively second and third.
U-BEV: Height-aware Bird's-Eye-View Segmentation and Neural Map-based Relocalization
Oct 20, 2023



Efficient relocalization is essential for intelligent vehicles when GPS reception is insufficient or sensor-based localization fails. Recent advances in Bird's-Eye-View (BEV) segmentation allow for accurate estimation of local scene appearance and in turn, can benefit the relocalization of the vehicle. However, one downside of BEV methods is the heavy computation required to leverage the geometric constraints. This paper presents U-BEV, a U-Net inspired architecture that extends the current state-of-the-art by allowing the BEV to reason about the scene on multiple height layers before flattening the BEV features. We show that this extension boosts the performance of the U-BEV by up to 4.11 IoU. Additionally, we combine the encoded neural BEV with a differentiable template matcher to perform relocalization on neural SD-map data. The model is fully end-to-end trainable and outperforms transformer-based BEV methods of similar computational complexity by 1.7 to 2.8 mIoU and BEV-based relocalization by over 26% Recall Accuracy on the nuScenes dataset.
Real-Time Motion Prediction via Heterogeneous Polyline Transformer with Relative Pose Encoding
Oct 19, 2023



The real-world deployment of an autonomous driving system requires its components to run on-board and in real-time, including the motion prediction module that predicts the future trajectories of surrounding traffic participants. Existing agent-centric methods have demonstrated outstanding performance on public benchmarks. However, they suffer from high computational overhead and poor scalability as the number of agents to be predicted increases. To address this problem, we introduce the K-nearest neighbor attention with relative pose encoding (KNARPE), a novel attention mechanism allowing the pairwise-relative representation to be used by Transformers. Then, based on KNARPE we present the Heterogeneous Polyline Transformer with Relative pose encoding (HPTR), a hierarchical framework enabling asynchronous token update during the online inference. By sharing contexts among agents and reusing the unchanged contexts, our approach is as efficient as scene-centric methods, while performing on par with state-of-the-art agent-centric methods. Experiments on Waymo and Argoverse-2 datasets show that HPTR achieves superior performance among end-to-end methods that do not apply expensive post-processing or model ensembling. The code is available at https://github.com/zhejz/HPTR.
Prior Based Online Lane Graph Extraction from Single Onboard Camera Image
Jul 25, 2023



The local road network information is essential for autonomous navigation. This information is commonly obtained from offline HD-Maps in terms of lane graphs. However, the local road network at a given moment can be drastically different than the one given in the offline maps; due to construction works, accidents etc. Moreover, the autonomous vehicle might be at a location not covered in the offline HD-Map. Thus, online estimation of the lane graph is crucial for widespread and reliable autonomous navigation. In this work, we tackle online Bird's-Eye-View lane graph extraction from a single onboard camera image. We propose to use prior information to increase quality of the estimations. The prior is extracted from the dataset through a transformer based Wasserstein Autoencoder. The autoencoder is then used to enhance the initial lane graph estimates. This is done through optimization of the latent space vector. The optimization encourages the lane graph estimation to be logical by discouraging it to diverge from the prior distribution. We test the method on two benchmark datasets, NuScenes and Argoverse. The results show that the proposed method significantly improves the performance compared to state-of-the-art methods.
Improving Online Lane Graph Extraction by Object-Lane Clustering
Jul 20, 2023



Autonomous driving requires accurate local scene understanding information. To this end, autonomous agents deploy object detection and online BEV lane graph extraction methods as a part of their perception stack. In this work, we propose an architecture and loss formulation to improve the accuracy of local lane graph estimates by using 3D object detection outputs. The proposed method learns to assign the objects to centerlines by considering the centerlines as cluster centers and the objects as data points to be assigned a probability distribution over the cluster centers. This training scheme ensures direct supervision on the relationship between lanes and objects, thus leading to better performance. The proposed method improves lane graph estimation substantially over state-of-the-art methods. The extensive ablations show that our method can achieve significant performance improvements by using the outputs of existing 3D object detection methods. Since our method uses the detection outputs rather than detection method intermediate representations, a single model of our method can use any detection method at test time.
Online Lane Graph Extraction from Onboard Video
Apr 03, 2023



Autonomous driving requires a structured understanding of the surrounding road network to navigate. One of the most common and useful representation of such an understanding is done in the form of BEV lane graphs. In this work, we use the video stream from an onboard camera for online extraction of the surrounding's lane graph. Using video, instead of a single image, as input poses both benefits and challenges in terms of combining the information from different timesteps. We study the emerged challenges using three different approaches. The first approach is a post-processing step that is capable of merging single frame lane graph estimates into a unified lane graph. The second approach uses the spatialtemporal embeddings in the transformer to enable the network to discover the best temporal aggregation strategy. Finally, the third, and the proposed method, is an early temporal aggregation through explicit BEV projection and alignment of framewise features. A single model of this proposed simple, yet effective, method can process any number of images, including one, to produce accurate lane graphs. The experiments on the Nuscenes and Argoverse datasets show the validity of all the approaches while highlighting the superiority of the proposed method. The code will be made public.
A Multiplicative Value Function for Safe and Efficient Reinforcement Learning
Mar 07, 2023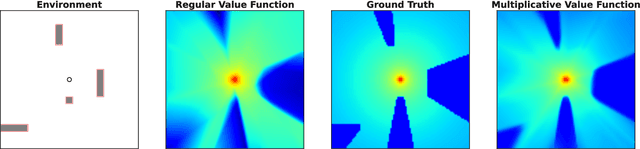
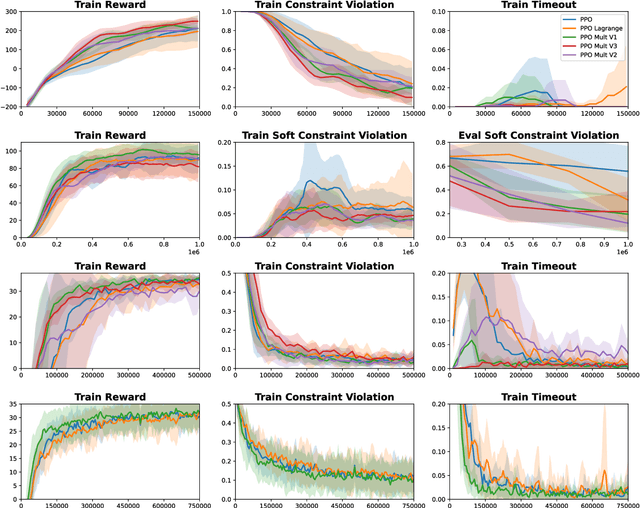

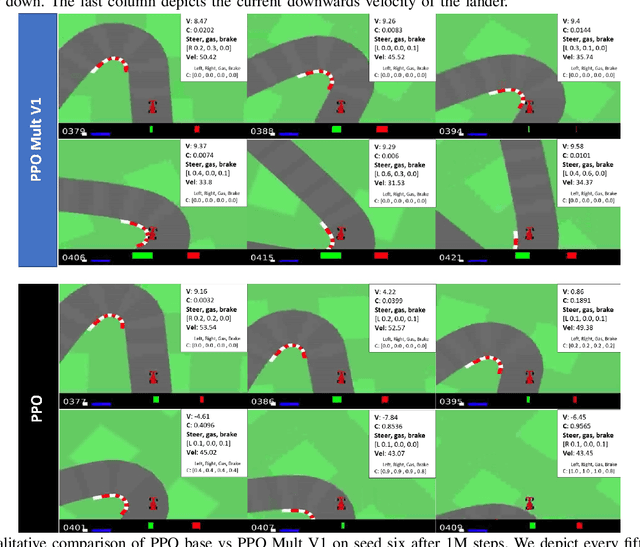
An emerging field of sequential decision problems is safe Reinforcement Learning (RL), where the objective is to maximize the reward while obeying safety constraints. Being able to handle constraints is essential for deploying RL agents in real-world environments, where constraint violations can harm the agent and the environment. To this end, we propose a safe model-free RL algorithm with a novel multiplicative value function consisting of a safety critic and a reward critic. The safety critic predicts the probability of constraint violation and discounts the reward critic that only estimates constraint-free returns. By splitting responsibilities, we facilitate the learning task leading to increased sample efficiency. We integrate our approach into two popular RL algorithms, Proximal Policy Optimization and Soft Actor-Critic, and evaluate our method in four safety-focused environments, including classical RL benchmarks augmented with safety constraints and robot navigation tasks with images and raw Lidar scans as observations. Finally, we make the zero-shot sim-to-real transfer where a differential drive robot has to navigate through a cluttered room. Our code can be found at https://github.com/nikeke19/Safe-Mult-RL.
TrafficBots: Towards World Models for Autonomous Driving Simulation and Motion Prediction
Mar 07, 2023



Data-driven simulation has become a favorable way to train and test autonomous driving algorithms. The idea of replacing the actual environment with a learned simulator has also been explored in model-based reinforcement learning in the context of world models. In this work, we show data-driven traffic simulation can be formulated as a world model. We present TrafficBots, a multi-agent policy built upon motion prediction and end-to-end driving, and based on TrafficBots we obtain a world model tailored for the planning module of autonomous vehicles. Existing data-driven traffic simulators are lacking configurability and scalability. To generate configurable behaviors, for each agent we introduce a destination as navigational information, and a time-invariant latent personality that specifies the behavioral style. To improve the scalability, we present a new scheme of positional encoding for angles, allowing all agents to share the same vectorized context and the use of an architecture based on dot-product attention. As a result, we can simulate all traffic participants seen in dense urban scenarios. Experiments on the Waymo open motion dataset show TrafficBots can simulate realistic multi-agent behaviors and achieve good performance on the motion prediction task.