 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Promptable Video Object Segmentation
May 12, 2026The performance of promptable video object segmentation (PVOS) models substantially degrades under input corruptions, which prevents PVOS deployment in safety-critical domains. This paper offers the first comprehensive study on robust PVOS (RobustPVOS). We first construct a new, comprehensive benchmark with two real-world evaluation datasets of 351 video clips and more than 2,500 object masks under real-world adverse conditions. At the same time, we generate synthetic training data by applying diverse and temporally varying corruptions to existing VOS datasets. Moreover, we present a new RobustPVOS method, dubbed Memory-object-conditioned Gated-rank Adaptation (MoGA). The key to successfully performing RobustPVOS is two-fold: effectively handling object-specific degradation and ensuring temporal consistency in predictions. MoGA leverages object-specific representations maintained in memory across frames to condition the robustification process, which allows the model to handle each tracked object differently in a temporally consistent way. Extensive experiments on our benchmark validate MoGA's efficacy, showing consistent and significant improvements across diverse corruption types on both synthetic and real-world datasets, establishing a strong baseline for future RobustPVOS research. Our benchmark is publicly available at https://sohyun-l.github.io/RobustPVOS_project_page/.
AURORA-KITTI: Any-Weather Depth Completion and Denoising in the Wild
Mar 16, 2026Robust depth completion is fundamental to real-world 3D scene understanding, yet existing RGB-LiDAR fusion methods degrade significantly under adverse weather, where both camera images and LiDAR measurements suffer from weather-induced corruption. In this paper, we introduce AURORA-KITTI, the first large-scale multi-modal, multi-weather benchmark for robust depth completion in the wild. We further formulate Depth Completion and Denoising (DCD) as a unified task that jointly reconstructs a dense depth map from corrupted sparse inputs while suppressing weather-induced noise. AURORA-KITTI contains over \textit{82K} weather-consistent RGBL pairs with metric depth ground truth, spanning diverse weather types, three severity levels, day and night scenes, paired clean references, lens occlusion conditions, and textual descriptions. Moreover, we introduce DDCD, an efficient distillation-based baseline that leverages depth foundation models to inject clean structural priors into in-the-wild DCD training. DDCD achieves state-of-the-art performance on AURORA-KITTI and the real-world DENSE dataset while maintaining efficiency. Notably, our results further show that weather-aware, physically consistent data contributes more to robustness than architectural modifications alone. Data and code will be released upon publication.
Video Depth Propagation
Dec 11, 2025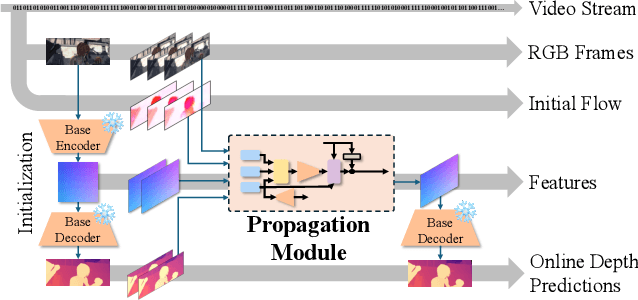
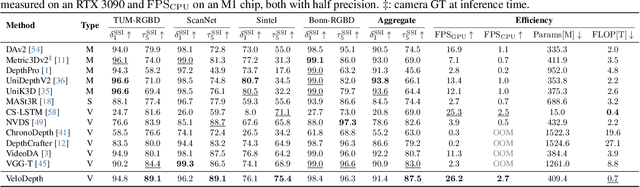
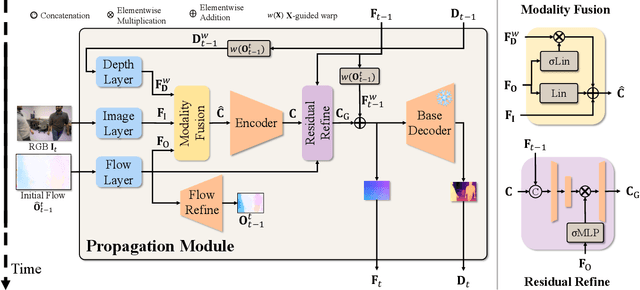
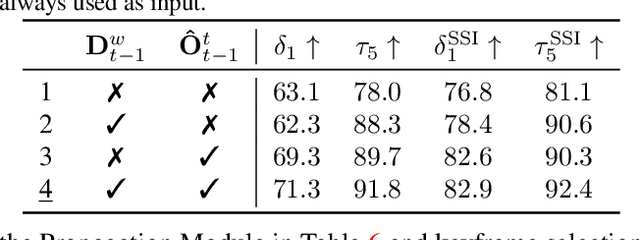
Depth estimation in videos is essential for visual perception in real-world applications. However, existing methods either rely on simple frame-by-frame monocular models, leading to temporal inconsistencies and inaccuracies, or use computationally demanding temporal modeling, unsuitable for real-time applications. These limitations significantly restrict general applicability and performance in practical settings. To address this, we propose VeloDepth, an efficient and robust online video depth estimation pipeline that effectively leverages spatiotemporal priors from previous depth predictions and performs deep feature propagation. Our method introduces a novel Propagation Module that refines and propagates depth features and predictions using flow-based warping coupled with learned residual corrections. In addition, our design structurally enforces temporal consistency, resulting in stable depth predictions across consecutive frames with improved efficiency. Comprehensive zero-shot evaluation on multiple benchmarks demonstrates the state-of-the-art temporal consistency and competitive accuracy of VeloDepth, alongside its significantly faster inference compared to existing video-based depth estimators. VeloDepth thus provides a practical, efficient, and accurate solution for real-time depth estimation suitable for diverse perception tasks. Code and models are available at https://github.com/lpiccinelli-eth/velodepth
You Only Train Once
Jun 04, 2025



The title of this paper is perhaps an overclaim. Of course, the process of creating and optimizing a learned model inevitably involves multiple training runs which potentially feature different architectural designs, input and output encodings, and losses. However, our method, You Only Train Once (YOTO), indeed contributes to limiting training to one shot for the latter aspect of losses selection and weighting. We achieve this by automatically optimizing loss weight hyperparameters of learned models in one shot via standard gradient-based optimization, treating these hyperparameters as regular parameters of the networks and learning them. To this end, we leverage the differentiability of the composite loss formulation which is widely used for optimizing multiple empirical losses simultaneously and model it as a novel layer which is parameterized with a softmax operation that satisfies the inherent positivity constraints on loss hyperparameters while avoiding degenerate empirical gradients. We complete our joint end-to-end optimization scheme by defining a novel regularization loss on the learned hyperparameters, which models a uniformity prior among the employed losses while ensuring boundedness of the identified optima. We evidence the efficacy of YOTO in jointly optimizing loss hyperparameters and regular model parameters in one shot by comparing it to the commonly used brute-force grid search across state-of-the-art networks solving two key problems in computer vision, i.e. 3D estimation and semantic segmentation, and showing that it consistently outperforms the best grid-search model on unseen test data. Code will be made publicly available.
UniK3D: Universal Camera Monocular 3D Estimation
Mar 20, 2025



Monocular 3D estimation is crucial for visual perception. However, current methods fall short by relying on oversimplified assumptions, such as pinhole camera models or rectified images. These limitations severely restrict their general applicability, causing poor performance in real-world scenarios with fisheye or panoramic images and resulting in substantial context loss. To address this, we present UniK3D, the first generalizable method for monocular 3D estimation able to model any camera. Our method introduces a spherical 3D representation which allows for better disentanglement of camera and scene geometry and enables accurate metric 3D reconstruction for unconstrained camera models. Our camera component features a novel, model-independent representation of the pencil of rays, achieved through a learned superposition of spherical harmonics. We also introduce an angular loss, which, together with the camera module design, prevents the contraction of the 3D outputs for wide-view cameras. A comprehensive zero-shot evaluation on 13 diverse datasets demonstrates the state-of-the-art performance of UniK3D across 3D, depth, and camera metrics, with substantial gains in challenging large-field-of-view and panoramic settings, while maintaining top accuracy in conventional pinhole small-field-of-view domains. Code and models are available at github.com/lpiccinelli-eth/unik3d .
UniDepthV2: Universal Monocular Metric Depth Estimation Made Simpler
Feb 27, 2025



Accurate monocular metric depth estimation (MMDE) is crucial to solving downstream tasks in 3D perception and modeling. However, the remarkable accuracy of recent MMDE methods is confined to their training domains. These methods fail to generalize to unseen domains even in the presence of moderate domain gaps, which hinders their practical applicability. We propose a new model, UniDepthV2, capable of reconstructing metric 3D scenes from solely single images across domains. Departing from the existing MMDE paradigm, UniDepthV2 directly predicts metric 3D points from the input image at inference time without any additional information, striving for a universal and flexible MMDE solution. In particular, UniDepthV2 implements a self-promptable camera module predicting a dense camera representation to condition depth features. Our model exploits a pseudo-spherical output representation, which disentangles the camera and depth representations. In addition, we propose a geometric invariance loss that promotes the invariance of camera-prompted depth features. UniDepthV2 improves its predecessor UniDepth model via a new edge-guided loss which enhances the localization and sharpness of edges in the metric depth outputs, a revisited, simplified and more efficient architectural design, and an additional uncertainty-level output which enables downstream tasks requiring confidence. Thorough evaluations on ten depth datasets in a zero-shot regime consistently demonstrate the superior performance and generalization of UniDepthV2. Code and models are available at https://github.com/lpiccinelli-eth/UniDepth
PBR-NeRF: Inverse Rendering with Physics-Based Neural Fields
Dec 12, 2024We tackle the ill-posed inverse rendering problem in 3D reconstruction with a Neural Radiance Field (NeRF) approach informed by Physics-Based Rendering (PBR) theory, named PBR-NeRF. Our method addresses a key limitation in most NeRF and 3D Gaussian Splatting approaches: they estimate view-dependent appearance without modeling scene materials and illumination. To address this limitation, we present an inverse rendering (IR) model capable of jointly estimating scene geometry, materials, and illumination. Our model builds upon recent NeRF-based IR approaches, but crucially introduces two novel physics-based priors that better constrain the IR estimation. Our priors are rigorously formulated as intuitive loss terms and achieve state-of-the-art material estimation without compromising novel view synthesis quality. Our method is easily adaptable to other inverse rendering and 3D reconstruction frameworks that require material estimation. We demonstrate the importance of extending current neural rendering approaches to fully model scene properties beyond geometry and view-dependent appearance. Code is publicly available at https://github.com/s3anwu/pbrnerf
Fine-Grained Spatial and Verbal Losses for 3D Visual Grounding
Nov 05, 2024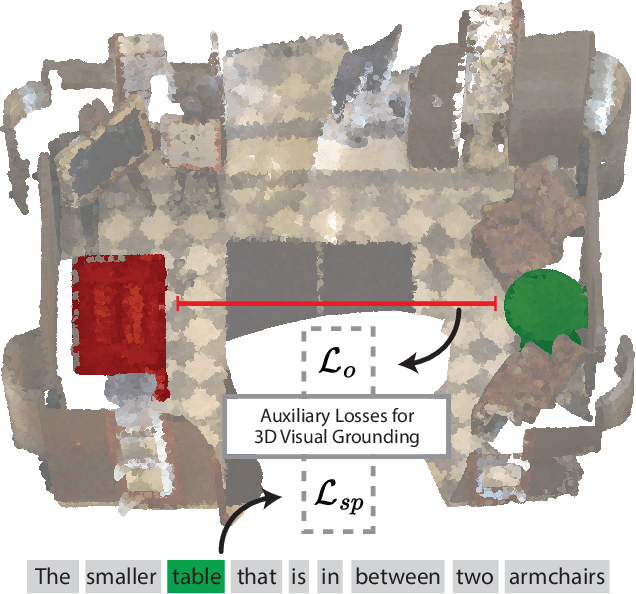
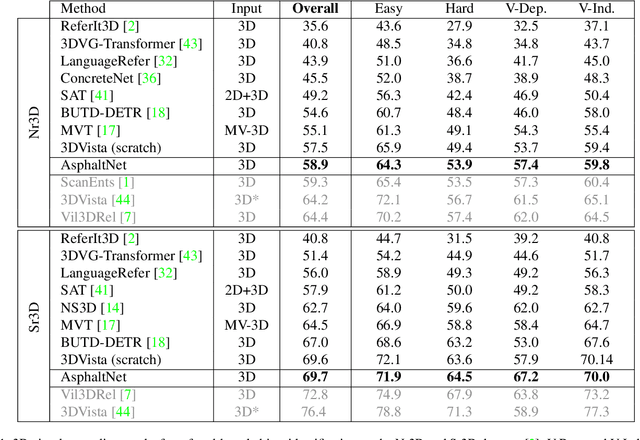
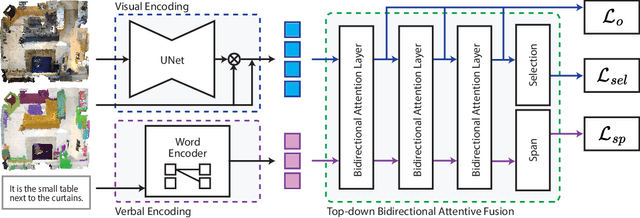
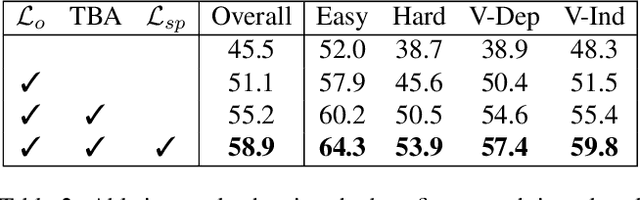
3D visual grounding consists of identifying the instance in a 3D scene which is referred by an accompanying language description. While several architectures have been proposed within the commonly employed grounding-by-selection framework, the utilized losses are comparatively under-explored. In particular, most methods rely on a basic supervised cross-entropy loss on the predicted distribution over candidate instances, which fails to model both spatial relations between instances and the internal fine-grained word-level structure of the verbal referral. Sparse attempts to additionally supervise verbal embeddings globally by learning the class of the referred instance from the description or employing verbo-visual contrast to better separate instance embeddings do not fundamentally lift the aforementioned limitations. Responding to these shortcomings, we introduce two novel losses for 3D visual grounding: a visual-level offset loss on regressed vector offsets from each instance to the ground-truth referred instance and a language-related span loss on predictions for the word-level span of the referred instance in the description. In addition, we equip the verbo-visual fusion module of our new 3D visual grounding architecture AsphaltNet with a top-down bidirectional attentive fusion block, which enables the supervisory signals from our two losses to propagate to the respective converse branches of the network and thus aid the latter to learn context-aware instance embeddings and grounding-aware verbal embeddings. AsphaltNet proposes novel auxiliary losses to aid 3D visual grounding with competitive results compared to the state-of-the-art on the ReferIt3D benchmark.
Condition-Aware Multimodal Fusion for Robust Semantic Perception of Driving Scenes
Oct 14, 2024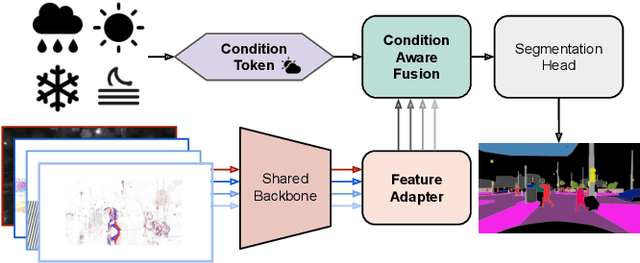
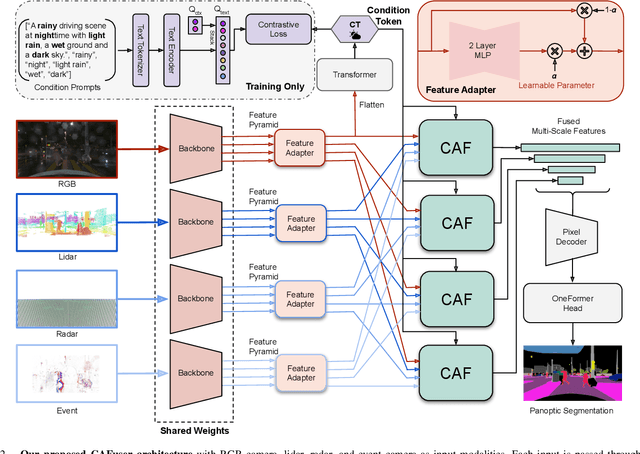
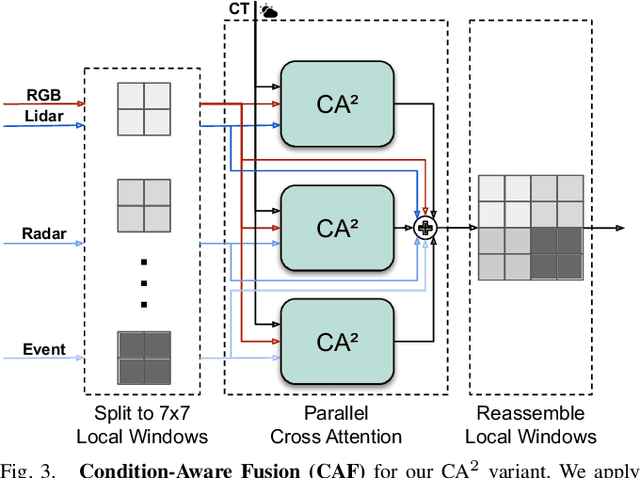
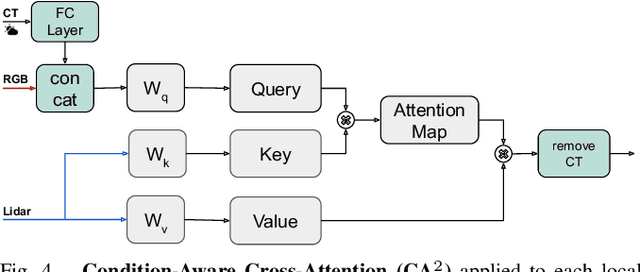
Leveraging multiple sensors is crucial for robust semantic perception in autonomous driving, as each sensor type has complementary strengths and weaknesses. However, existing sensor fusion methods often treat sensors uniformly across all conditions, leading to suboptimal performance. By contrast, we propose a novel, condition-aware multimodal fusion approach for robust semantic perception of driving scenes. Our method, CAFuser uses an RGB camera input to classify environmental conditions and generate a Condition Token that guides the fusion of multiple sensor modalities. We further newly introduce modality-specific feature adapters to align diverse sensor inputs into a shared latent space, enabling efficient integration with a single and shared pre-trained backbone. By dynamically adapting sensor fusion based on the actual condition, our model significantly improves robustness and accuracy, especially in adverse-condition scenarios. We set the new state of the art with CAFuser on the MUSES dataset with 59.7 PQ for multimodal panoptic segmentation and 78.2 mIoU for semantic segmentation, ranking first on the public benchmarks.
Bayesian Self-Training for Semi-Supervised 3D Segmentation
Sep 12, 2024
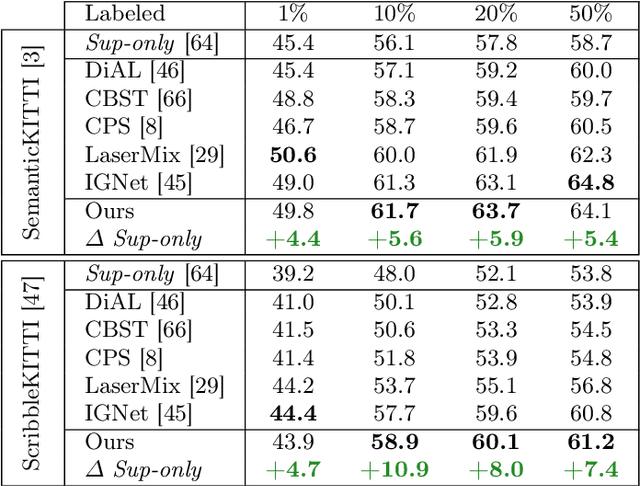


3D segmentation is a core problem in computer vision and, similarly to many other dense prediction tasks, it requires large amounts of annotated data for adequate training. However, densely labeling 3D point clouds to employ fully-supervised training remains too labor intensive and expensive. Semi-supervised training provides a more practical alternative, where only a small set of labeled data is given, accompanied by a larger unlabeled set. This area thus studies the effective use of unlabeled data to reduce the performance gap that arises due to the lack of annotations. In this work, inspired by Bayesian deep learning, we first propose a Bayesian self-training framework for semi-supervised 3D semantic segmentation. Employing stochastic inference, we generate an initial set of pseudo-labels and then filter these based on estimated point-wise uncertainty. By constructing a heuristic $n$-partite matching algorithm, we extend the method to semi-supervised 3D instance segmentation, and finally, with the same building blocks, to dense 3D visual grounding. We demonstrate state-of-the-art results for our semi-supervised method on SemanticKITTI and ScribbleKITTI for 3D semantic segmentation and on ScanNet and S3DIS for 3D instance segmentation. We further achieve substantial improvements in dense 3D visual grounding over supervised-only baselines on ScanRefer. Our project page is available at ouenal.github.io/bst/.