 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Spatial and Verbal Losses for 3D Visual Grounding
Paper and Code
Nov 05, 2024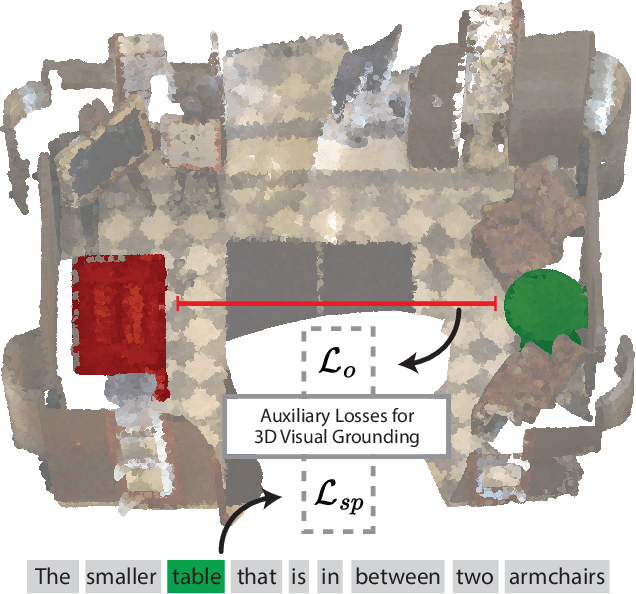
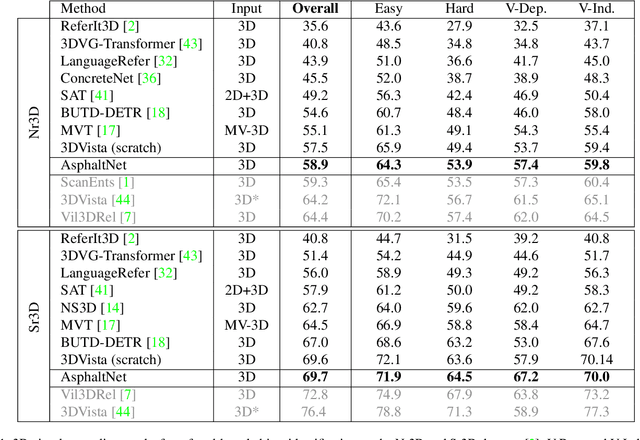
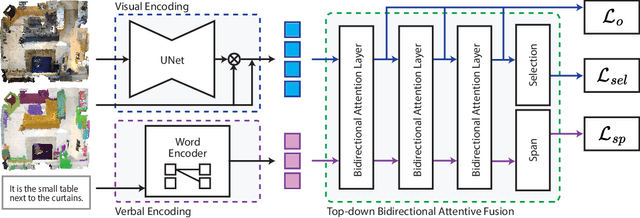
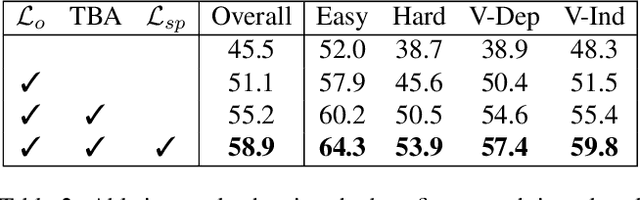
3D visual grounding consists of identifying the instance in a 3D scene which is referred by an accompanying language description. While several architectures have been proposed within the commonly employed grounding-by-selection framework, the utilized losses are comparatively under-explored. In particular, most methods rely on a basic supervised cross-entropy loss on the predicted distribution over candidate instances, which fails to model both spatial relations between instances and the internal fine-grained word-level structure of the verbal referral. Sparse attempts to additionally supervise verbal embeddings globally by learning the class of the referred instance from the description or employing verbo-visual contrast to better separate instance embeddings do not fundamentally lift the aforementioned limitations. Responding to these shortcomings, we introduce two novel losses for 3D visual grounding: a visual-level offset loss on regressed vector offsets from each instance to the ground-truth referred instance and a language-related span loss on predictions for the word-level span of the referred instance in the description. In addition, we equip the verbo-visual fusion module of our new 3D visual grounding architecture AsphaltNet with a top-down bidirectional attentive fusion block, which enables the supervisory signals from our two losses to propagate to the respective converse branches of the network and thus aid the latter to learn context-aware instance embeddings and grounding-aware verbal embeddings. AsphaltNet proposes novel auxiliary losses to aid 3D visual grounding with competitive results compared to the state-of-the-art on the ReferIt3D benchmark.