 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR-VLA: True Autoregressive Action Expert for Vision-Language-Action Models
Mar 10, 2026We propose a standalone autoregressive (AR) Action Expert that generates actions as a continuous causal sequence while conditioning on refreshable vision-language prefixes. In contrast to existing Vision-Language-Action (VLA) models and diffusion policies that reset temporal context with each new observation and predict actions reactively, our Action Expert maintains its own history through a long-lived memory and is inherently context-aware. This structure addresses the frequency mismatch between fast control and slow reasoning, enabling efficient independent pretraining of kinematic syntax and modular integration with heavy perception backbones, naturally ensuring spatio-temporally consistent action generation across frames. To synchronize these asynchronous hybrid V-L-A modalities, we utilize a re-anchoring mechanism that mathematically accounts for perception staleness during both training and inference. Experiments on simulated and real-robot manipulation tasks demonstrate that the proposed method can effectively replace traditional chunk-based action heads for both specialist and generalist policies. AR-VLA exhibits superior history awareness and substantially smoother action trajectories while maintaining or exceeding the task success rates of state-of-the-art reactive VLAs. Overall, our work introduces a scalable, context-aware action generation schema that provides a robust structural foundation for training effective robotic policies.
From Scan to Action: Leveraging Realistic Scans for Embodied Scene Understanding
Jul 23, 2025Real-world 3D scene-level scans offer realism and can enable better real-world generalizability for downstream applications. However, challenges such as data volume, diverse annotation formats, and tool compatibility limit their use. This paper demonstrates a methodology to effectively leverage these scans and their annotations. We propose a unified annotation integration using USD, with application-specific USD flavors. We identify challenges in utilizing holistic real-world scan datasets and present mitigation strategies. The efficacy of our approach is demonstrated through two downstream applications: LLM-based scene editing, enabling effective LLM understanding and adaptation of the data (80% success), and robotic simulation, achieving an 87% success rate in policy learning.
Fine-Grained Spatial and Verbal Losses for 3D Visual Grounding
Nov 05, 2024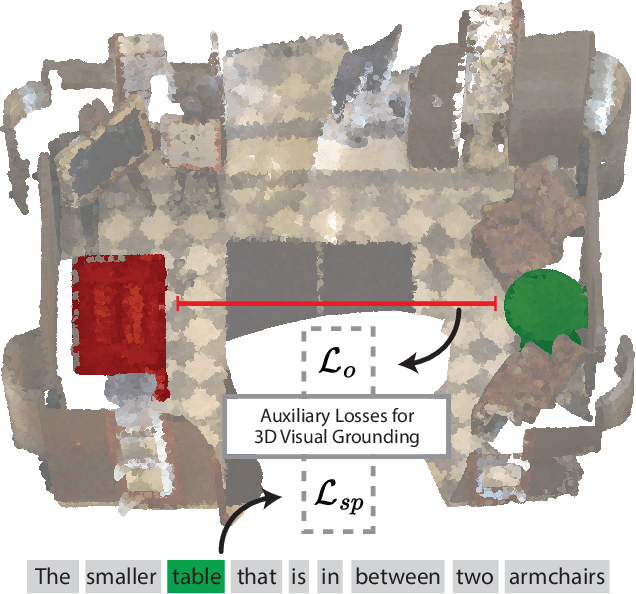
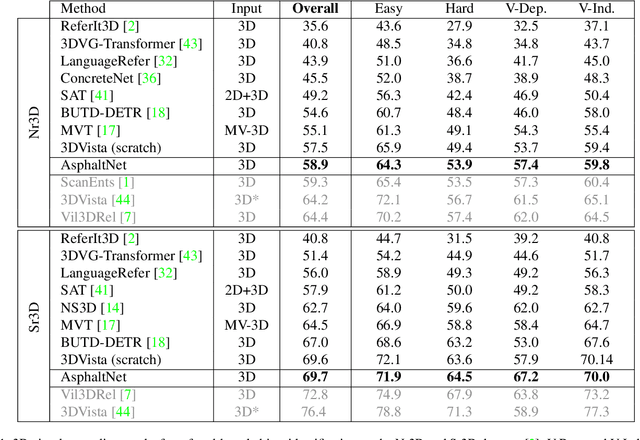
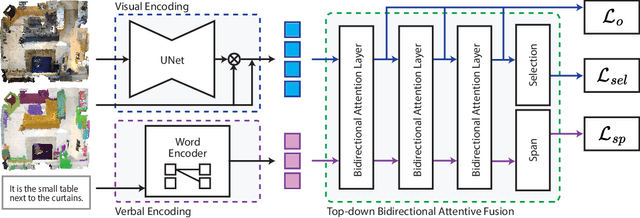
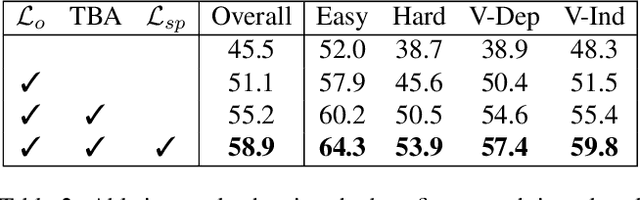
3D visual grounding consists of identifying the instance in a 3D scene which is referred by an accompanying language description. While several architectures have been proposed within the commonly employed grounding-by-selection framework, the utilized losses are comparatively under-explored. In particular, most methods rely on a basic supervised cross-entropy loss on the predicted distribution over candidate instances, which fails to model both spatial relations between instances and the internal fine-grained word-level structure of the verbal referral. Sparse attempts to additionally supervise verbal embeddings globally by learning the class of the referred instance from the description or employing verbo-visual contrast to better separate instance embeddings do not fundamentally lift the aforementioned limitations. Responding to these shortcomings, we introduce two novel losses for 3D visual grounding: a visual-level offset loss on regressed vector offsets from each instance to the ground-truth referred instance and a language-related span loss on predictions for the word-level span of the referred instance in the description. In addition, we equip the verbo-visual fusion module of our new 3D visual grounding architecture AsphaltNet with a top-down bidirectional attentive fusion block, which enables the supervisory signals from our two losses to propagate to the respective converse branches of the network and thus aid the latter to learn context-aware instance embeddings and grounding-aware verbal embeddings. AsphaltNet proposes novel auxiliary losses to aid 3D visual grounding with competitive results compared to the state-of-the-art on the ReferIt3D benchmark.
Learning whom to trust in navigation: dynamically switching between classical and neural planning
Jul 31, 2023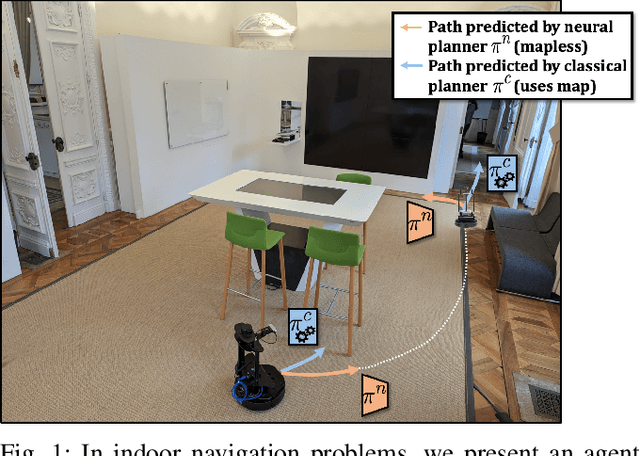
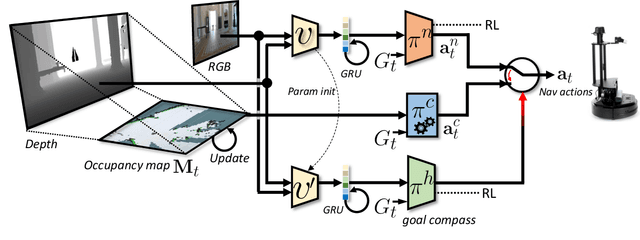
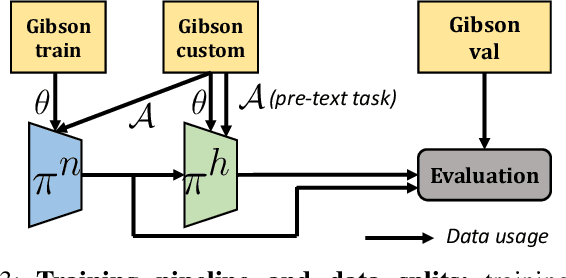
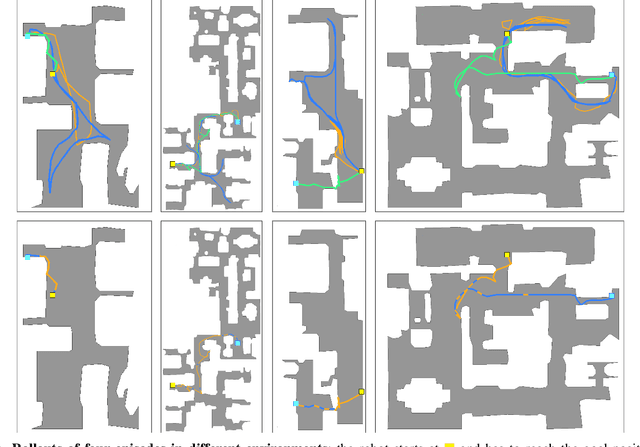
Navigation of terrestrial robots is typically addressed either with localization and mapping (SLAM) followed by classical planning on the dynamically created maps, or by machine learning (ML), often through end-to-end training with reinforcement learning (RL) or imitation learning (IL). Recently, modular designs have achieved promising results, and hybrid algorithms that combine ML with classical planning have been proposed. Existing methods implement these combinations with hand-crafted functions, which cannot fully exploit the complementary nature of the policies and the complex regularities between scene structure and planning performance. Our work builds on the hypothesis that the strengths and weaknesses of neural planners and classical planners follow some regularities, which can be learned from training data, in particular from interactions. This is grounded on the assumption that, both, trained planners and the mapping algorithms underlying classical planning are subject to failure cases depending on the semantics of the scene and that this dependence is learnable: for instance, certain areas, objects or scene structures can be reconstructed easier than others. We propose a hierarchical method composed of a high-level planner dynamically switching between a classical and a neural planner. We fully train all neural policies in simulation and evaluate the method in both simulation and real experiments with a LoCoBot robot, showing significant gains in performance, in particular in the real environment. We also qualitatively conjecture on the nature of data regularities exploited by the high-level planner.