 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Object Navigation in real environments using hybrid policies
Jan 24, 2024Navigation has been classically solved in robotics through the combination of SLAM and planning. More recently, beyond waypoint planning, problems involving significant components of (visual) high-level reasoning have been explored in simulated environments, mostly addressed with large-scale machine learning, in particular RL, offline-RL or imitation learning. These methods require the agent to learn various skills like local planning, mapping objects and querying the learned spatial representations. In contrast to simpler tasks like waypoint planning (PointGoal), for these more complex tasks the current state-of-the-art models have been thoroughly evaluated in simulation but, to our best knowledge, not yet in real environments. In this work we focus on sim2real transfer. We target the challenging Multi-Object Navigation (Multi-ON) task and port it to a physical environment containing real replicas of the originally virtual Multi-ON objects. We introduce a hybrid navigation method, which decomposes the problem into two different skills: (1) waypoint navigation is addressed with classical SLAM combined with a symbolic planner, whereas (2) exploration, semantic mapping and goal retrieval are dealt with deep neural networks trained with a combination of supervised learning and RL. We show the advantages of this approach compared to end-to-end methods both in simulation and a real environment and outperform the SOTA for this task.
Learning whom to trust in navigation: dynamically switching between classical and neural planning
Jul 31, 2023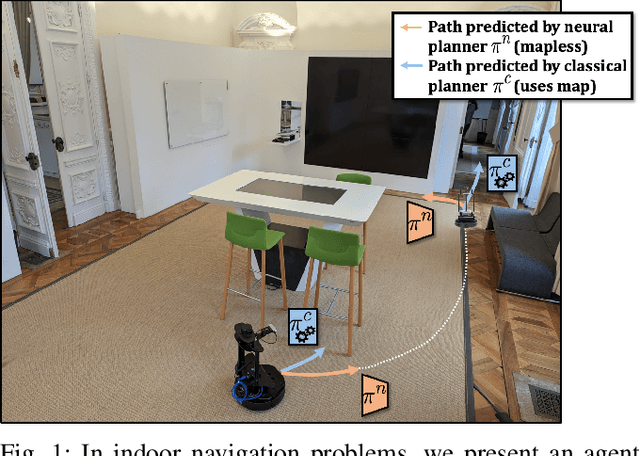
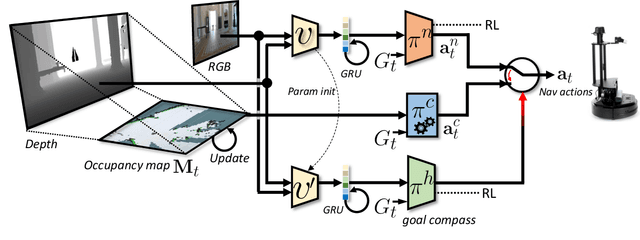
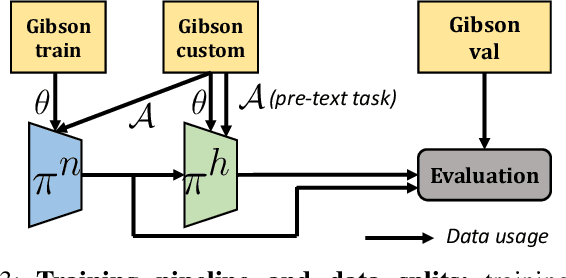
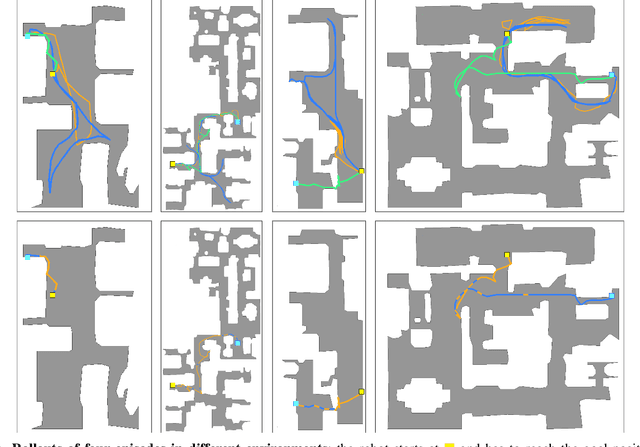
Navigation of terrestrial robots is typically addressed either with localization and mapping (SLAM) followed by classical planning on the dynamically created maps, or by machine learning (ML), often through end-to-end training with reinforcement learning (RL) or imitation learning (IL). Recently, modular designs have achieved promising results, and hybrid algorithms that combine ML with classical planning have been proposed. Existing methods implement these combinations with hand-crafted functions, which cannot fully exploit the complementary nature of the policies and the complex regularities between scene structure and planning performance. Our work builds on the hypothesis that the strengths and weaknesses of neural planners and classical planners follow some regularities, which can be learned from training data, in particular from interactions. This is grounded on the assumption that, both, trained planners and the mapping algorithms underlying classical planning are subject to failure cases depending on the semantics of the scene and that this dependence is learnable: for instance, certain areas, objects or scene structures can be reconstructed easier than others. We propose a hierarchical method composed of a high-level planner dynamically switching between a classical and a neural planner. We fully train all neural policies in simulation and evaluate the method in both simulation and real experiments with a LoCoBot robot, showing significant gains in performance, in particular in the real environment. We also qualitatively conjecture on the nature of data regularities exploited by the high-level planner.
Learning with a Mole: Transferable latent spatial representations for navigation without reconstruction
Jun 06, 2023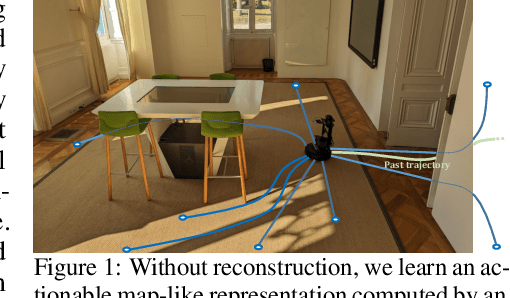
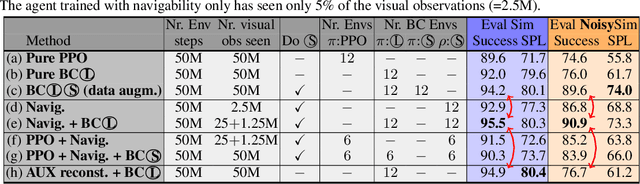
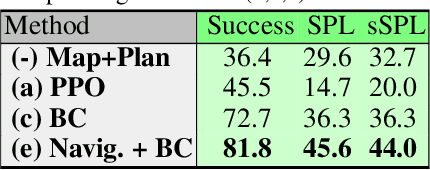
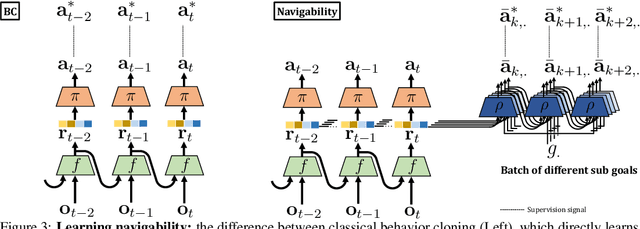
Agents navigating in 3D environments require some form of memory, which should hold a compact and actionable representation of the history of observations useful for decision taking and planning. In most end-to-end learning approaches the representation is latent and usually does not have a clearly defined interpretation, whereas classical robotics addresses this with scene reconstruction resulting in some form of map, usually estimated with geometry and sensor models and/or learning. In this work we propose to learn an actionable representation of the scene independently of the targeted downstream task and without explicitly optimizing reconstruction. The learned representation is optimized by a blind auxiliary agent trained to navigate with it on multiple short sub episodes branching out from a waypoint and, most importantly, without any direct visual observation. We argue and show that the blindness property is important and forces the (trained) latent representation to be the only means for planning. With probing experiments we show that the learned representation optimizes navigability and not reconstruction. On downstream tasks we show that it is robust to changes in distribution, in particular the sim2real gap, which we evaluate with a real physical robot in a real office building, significantly improving performance.
An in-depth experimental study of sensor usage and visual reasoning of robots navigating in real environments
Nov 29, 2021

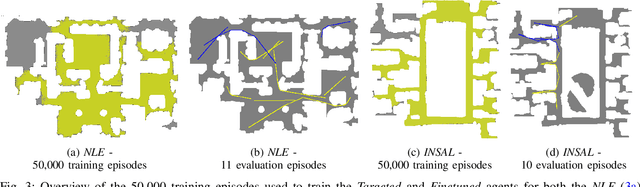

Visual navigation by mobile robots is classically tackled through SLAM plus optimal planning, and more recently through end-to-end training of policies implemented as deep networks. While the former are often limited to waypoint planning, but have proven their efficiency even on real physical environments, the latter solutions are most frequently employed in simulation, but have been shown to be able learn more complex visual reasoning, involving complex semantical regularities. Navigation by real robots in physical environments is still an open problem. End-to-end training approaches have been thoroughly tested in simulation only, with experiments involving real robots being restricted to rare performance evaluations in simplified laboratory conditions. In this work we present an in-depth study of the performance and reasoning capacities of real physical agents, trained in simulation and deployed to two different physical environments. Beyond benchmarking, we provide insights into the generalization capabilities of different agents training in different conditions. We visualize sensor usage and the importance of the different types of signals. We show, that for the PointGoal task, an agent pre-trained on wide variety of tasks and fine-tuned on a simulated version of the target environment can reach competitive performance without modelling any sim2real transfer, i.e. by deploying the trained agent directly from simulation to a real physical robot.
Universal Domain Adaptation in Ordinal Regression
Jun 22, 2021
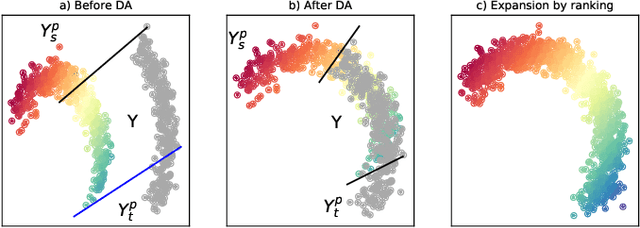
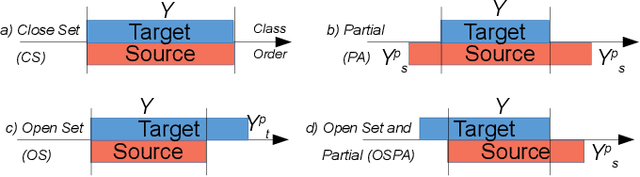
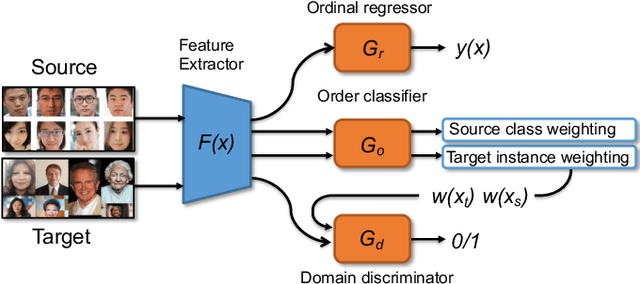
We address the problem of universal domain adaptation (UDA) in ordinal regression (OR), which attempts to solve classification problems in which labels are not independent, but follow a natural order. We show that the UDA techniques developed for classification and based on the clustering assumption, under-perform in OR settings. We propose a method that complements the OR classifier with an auxiliary task of order learning, which plays the double role of discriminating between common and private instances, and expanding class labels to the private target images via ranking. Combined with adversarial domain discrimination, our model is able to address the closed set, partial and open set configurations. We evaluate our method on three face age estimation datasets, and show that it outperforms the baseline methods.
Self-Supervised Attention Learning for Depth and Ego-motion Estimation
Apr 27, 2020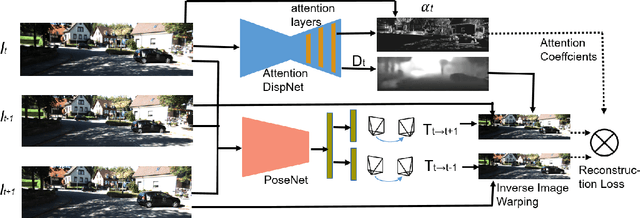
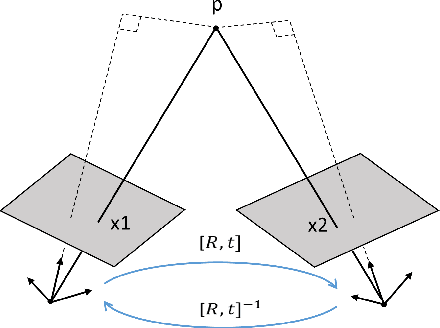
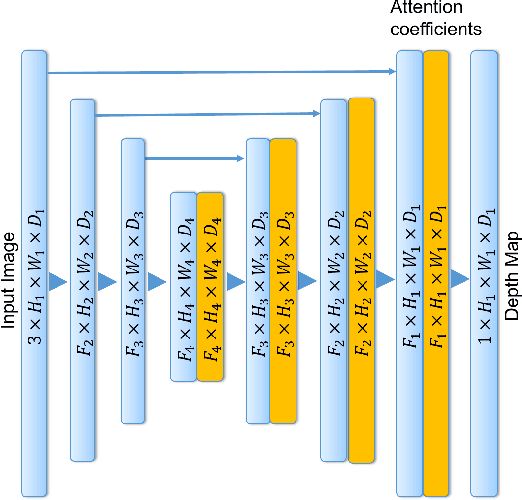

We address the problem of depth and ego-motion estimation from image sequences. Recent advances in the domain propose to train a deep learning model for both tasks using image reconstruction in a self-supervised manner. We revise the assumptions and the limitations of the current approaches and propose two improvements to boost the performance of the depth and ego-motion estimation. We first use Lie group properties to enforce the geometric consistency between images in the sequence and their reconstructions. We then propose a mechanism to pay an attention to image regions where the image reconstruction get corrupted. We show how to integrate the attention mechanism in the form of attention gates in the pipeline and use attention coefficients as a mask. We evaluate the new architecture on the KITTI datasets and compare it to the previous techniques. We show that our approach improves the state-of-the-art results for ego-motion estimation and achieve comparable results for depth estimation.