 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRANa: Retrieval-Augmented Navigation
Apr 04, 2025Methods for navigation based on large-scale learning typically treat each episode as a new problem, where the agent is spawned with a clean memory in an unknown environment. While these generalization capabilities to an unknown environment are extremely important, we claim that, in a realistic setting, an agent should have the capacity of exploiting information collected during earlier robot operations. We address this by introducing a new retrieval-augmented agent, trained with RL, capable of querying a database collected from previous episodes in the same environment and learning how to integrate this additional context information. We introduce a unique agent architecture for the general navigation task, evaluated on ObjectNav, ImageNav and Instance-ImageNav. Our retrieval and context encoding methods are data-driven and heavily employ vision foundation models (FM) for both semantic and geometric understanding. We propose new benchmarks for these settings and we show that retrieval allows zero-shot transfer across tasks and environments while significantly improving performance.
Reasoning in visual navigation of end-to-end trained agents: a dynamical systems approach
Mar 12, 2025Progress in Embodied AI has made it possible for end-to-end-trained agents to navigate in photo-realistic environments with high-level reasoning and zero-shot or language-conditioned behavior, but benchmarks are still dominated by simulation. In this work, we focus on the fine-grained behavior of fast-moving real robots and present a large-scale experimental study involving \numepisodes{} navigation episodes in a real environment with a physical robot, where we analyze the type of reasoning emerging from end-to-end training. In particular, we study the presence of realistic dynamics which the agent learned for open-loop forecasting, and their interplay with sensing. We analyze the way the agent uses latent memory to hold elements of the scene structure and information gathered during exploration. We probe the planning capabilities of the agent, and find in its memory evidence for somewhat precise plans over a limited horizon. Furthermore, we show in a post-hoc analysis that the value function learned by the agent relates to long-term planning. Put together, our experiments paint a new picture on how using tools from computer vision and sequential decision making have led to new capabilities in robotics and control. An interactive tool is available at europe.naverlabs.com/research/publications/reasoning-in-visual-navigation-of-end-to-end-trained-agents.
Learning to navigate efficiently and precisely in real environments
Jan 25, 2024In the context of autonomous navigation of terrestrial robots, the creation of realistic models for agent dynamics and sensing is a widespread habit in the robotics literature and in commercial applications, where they are used for model based control and/or for localization and mapping. The more recent Embodied AI literature, on the other hand, focuses on modular or end-to-end agents trained in simulators like Habitat or AI-Thor, where the emphasis is put on photo-realistic rendering and scene diversity, but high-fidelity robot motion is assigned a less privileged role. The resulting sim2real gap significantly impacts transfer of the trained models to real robotic platforms. In this work we explore end-to-end training of agents in simulation in settings which minimize the sim2real gap both, in sensing and in actuation. Our agent directly predicts (discretized) velocity commands, which are maintained through closed-loop control in the real robot. The behavior of the real robot (including the underlying low-level controller) is identified and simulated in a modified Habitat simulator. Noise models for odometry and localization further contribute in lowering the sim2real gap. We evaluate on real navigation scenarios, explore different localization and point goal calculation methods and report significant gains in performance and robustness compared to prior work.
Multi-Object Navigation in real environments using hybrid policies
Jan 24, 2024Navigation has been classically solved in robotics through the combination of SLAM and planning. More recently, beyond waypoint planning, problems involving significant components of (visual) high-level reasoning have been explored in simulated environments, mostly addressed with large-scale machine learning, in particular RL, offline-RL or imitation learning. These methods require the agent to learn various skills like local planning, mapping objects and querying the learned spatial representations. In contrast to simpler tasks like waypoint planning (PointGoal), for these more complex tasks the current state-of-the-art models have been thoroughly evaluated in simulation but, to our best knowledge, not yet in real environments. In this work we focus on sim2real transfer. We target the challenging Multi-Object Navigation (Multi-ON) task and port it to a physical environment containing real replicas of the originally virtual Multi-ON objects. We introduce a hybrid navigation method, which decomposes the problem into two different skills: (1) waypoint navigation is addressed with classical SLAM combined with a symbolic planner, whereas (2) exploration, semantic mapping and goal retrieval are dealt with deep neural networks trained with a combination of supervised learning and RL. We show the advantages of this approach compared to end-to-end methods both in simulation and a real environment and outperform the SOTA for this task.
End-to-End -Image Goal Navigation through Correspondence as an Emergent Phenomenon
Sep 28, 2023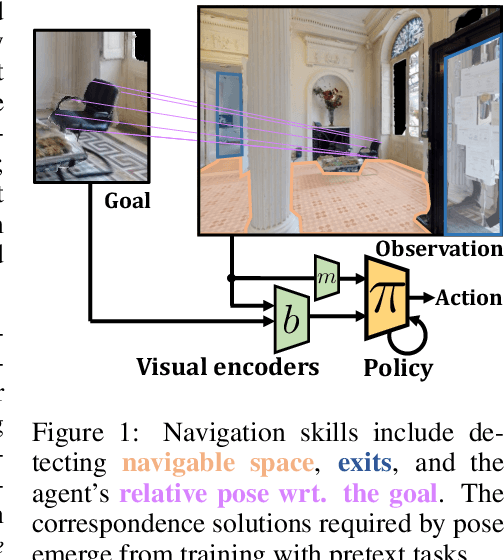


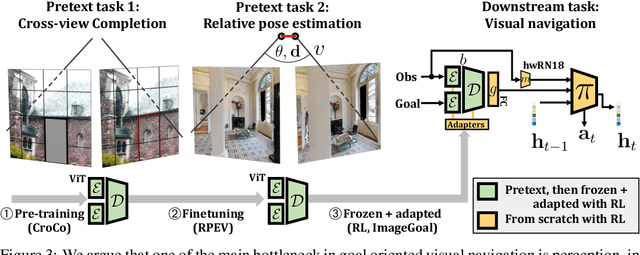
Most recent work in goal oriented visual navigation resorts to large-scale machine learning in simulated environments. The main challenge lies in learning compact representations generalizable to unseen environments and in learning high-capacity perception modules capable of reasoning on high-dimensional input. The latter is particularly difficult when the goal is not given as a category ("ObjectNav") but as an exemplar image ("ImageNav"), as the perception module needs to learn a comparison strategy requiring to solve an underlying visual correspondence problem. This has been shown to be difficult from reward alone or with standard auxiliary tasks. We address this problem through a sequence of two pretext tasks, which serve as a prior for what we argue is one of the main bottleneck in perception, extremely wide-baseline relative pose estimation and visibility prediction in complex scenes. The first pretext task, cross-view completion is a proxy for the underlying visual correspondence problem, while the second task addresses goal detection and finding directly. We propose a new dual encoder with a large-capacity binocular ViT model and show that correspondence solutions naturally emerge from the training signals. Experiments show significant improvements and SOTA performance on the two benchmarks, ImageNav and the Instance-ImageNav variant, where camera intrinsics and height differ between observation and goal.
Learning with a Mole: Transferable latent spatial representations for navigation without reconstruction
Jun 06, 2023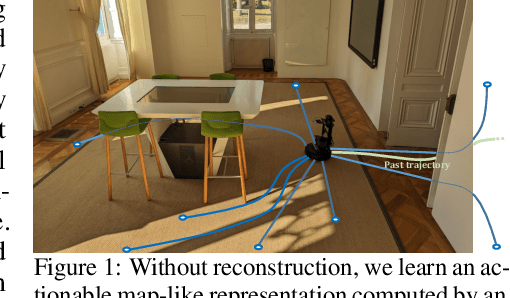
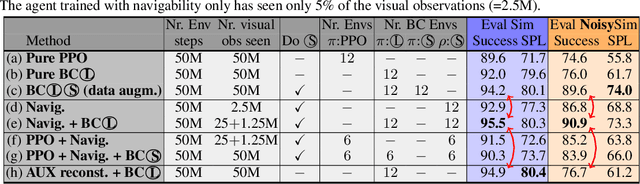
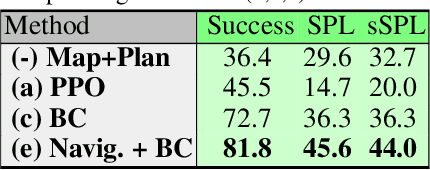
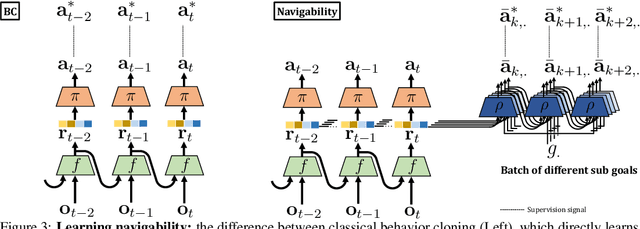
Agents navigating in 3D environments require some form of memory, which should hold a compact and actionable representation of the history of observations useful for decision taking and planning. In most end-to-end learning approaches the representation is latent and usually does not have a clearly defined interpretation, whereas classical robotics addresses this with scene reconstruction resulting in some form of map, usually estimated with geometry and sensor models and/or learning. In this work we propose to learn an actionable representation of the scene independently of the targeted downstream task and without explicitly optimizing reconstruction. The learned representation is optimized by a blind auxiliary agent trained to navigate with it on multiple short sub episodes branching out from a waypoint and, most importantly, without any direct visual observation. We argue and show that the blindness property is important and forces the (trained) latent representation to be the only means for planning. With probing experiments we show that the learned representation optimizes navigability and not reconstruction. On downstream tasks we show that it is robust to changes in distribution, in particular the sim2real gap, which we evaluate with a real physical robot in a real office building, significantly improving performance.
MoCap-less Quantitative Evaluation of Ego-Pose Estimation Without Ground Truth Measurements
Feb 01, 2022
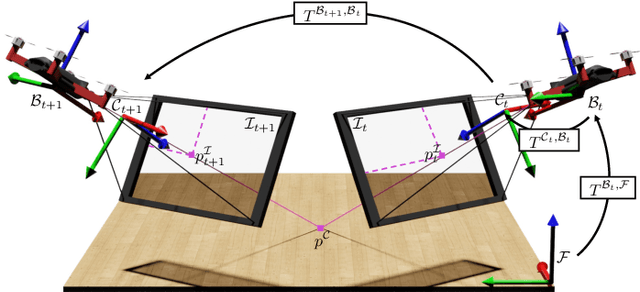

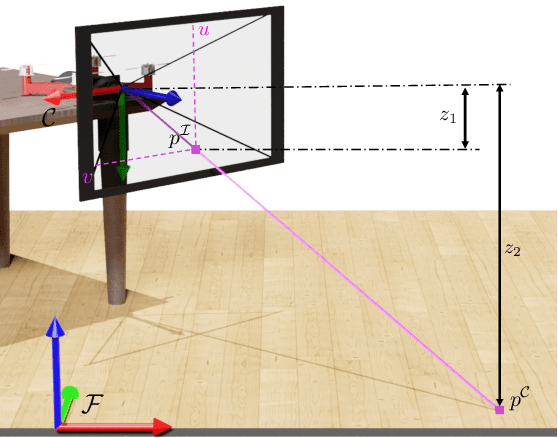
The emergence of data-driven approaches for control and planning in robotics have highlighted the need for developing experimental robotic platforms for data collection. However, their implementation is often complex and expensive, in particular for flying and terrestrial robots where the precise estimation of the position requires motion capture devices (MoCap) or Lidar. In order to simplify the use of a robotic platform dedicated to research on a wide range of indoor and outdoor environments, we present a data validation tool for ego-pose estimation that does not require any equipment other than the on-board camera. The method and tool allow a rapid, visual and quantitative evaluation of the quality of ego-pose sensors and are sensitive to different sources of flaws in the acquisition chain, ranging from desynchronization of the sensor flows to misevaluation of the geometric parameters of the robotic platform. Using computer vision, the information from the sensors is used to calculate the motion of a semantic scene point through its projection to the 2D image space of the on-board camera. The deviations of these keypoints from references created with a semi-automatic tool allow rapid and simple quality assessment of the data collected on the platform. To demonstrate the performance of our method, we evaluate it on two challenging standard UAV datasets as well as one dataset taken from a terrestrial robot.
An in-depth experimental study of sensor usage and visual reasoning of robots navigating in real environments
Nov 29, 2021

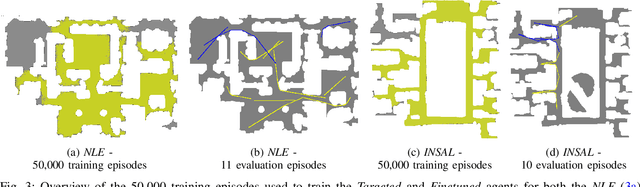

Visual navigation by mobile robots is classically tackled through SLAM plus optimal planning, and more recently through end-to-end training of policies implemented as deep networks. While the former are often limited to waypoint planning, but have proven their efficiency even on real physical environments, the latter solutions are most frequently employed in simulation, but have been shown to be able learn more complex visual reasoning, involving complex semantical regularities. Navigation by real robots in physical environments is still an open problem. End-to-end training approaches have been thoroughly tested in simulation only, with experiments involving real robots being restricted to rare performance evaluations in simplified laboratory conditions. In this work we present an in-depth study of the performance and reasoning capacities of real physical agents, trained in simulation and deployed to two different physical environments. Beyond benchmarking, we provide insights into the generalization capabilities of different agents training in different conditions. We visualize sensor usage and the importance of the different types of signals. We show, that for the PointGoal task, an agent pre-trained on wide variety of tasks and fine-tuned on a simulated version of the target environment can reach competitive performance without modelling any sim2real transfer, i.e. by deploying the trained agent directly from simulation to a real physical robot.
SIM2REALVIZ: Visualizing the Sim2Real Gap in Robot Ego-Pose Estimation
Sep 24, 2021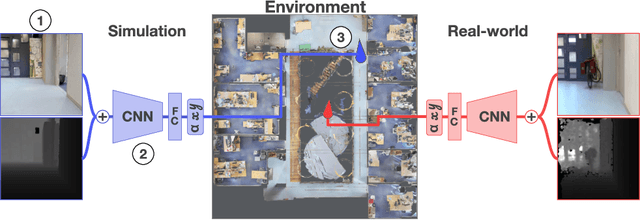
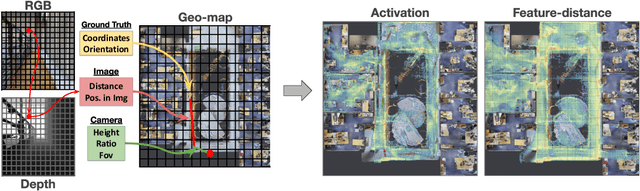


The Robotics community has started to heavily rely on increasingly realistic 3D simulators for large-scale training of robots on massive amounts of data. But once robots are deployed in the real world, the simulation gap, as well as changes in the real world (e.g. lights, objects displacements) lead to errors. In this paper, we introduce Sim2RealViz, a visual analytics tool to assist experts in understanding and reducing this gap for robot ego-pose estimation tasks, i.e. the estimation of a robot's position using trained models. Sim2RealViz displays details of a given model and the performance of its instances in both simulation and real-world. Experts can identify environment differences that impact model predictions at a given location and explore through direct interactions with the model hypothesis to fix it. We detail the design of the tool, and case studies related to the exploit of the regression to the mean bias and how it can be addressed, and how models are perturbed by the vanish of landmarks such as bikes.