 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning in visual navigation of end-to-end trained agents: a dynamical systems approach
Mar 12, 2025Progress in Embodied AI has made it possible for end-to-end-trained agents to navigate in photo-realistic environments with high-level reasoning and zero-shot or language-conditioned behavior, but benchmarks are still dominated by simulation. In this work, we focus on the fine-grained behavior of fast-moving real robots and present a large-scale experimental study involving \numepisodes{} navigation episodes in a real environment with a physical robot, where we analyze the type of reasoning emerging from end-to-end training. In particular, we study the presence of realistic dynamics which the agent learned for open-loop forecasting, and their interplay with sensing. We analyze the way the agent uses latent memory to hold elements of the scene structure and information gathered during exploration. We probe the planning capabilities of the agent, and find in its memory evidence for somewhat precise plans over a limited horizon. Furthermore, we show in a post-hoc analysis that the value function learned by the agent relates to long-term planning. Put together, our experiments paint a new picture on how using tools from computer vision and sequential decision making have led to new capabilities in robotics and control. An interactive tool is available at europe.naverlabs.com/research/publications/reasoning-in-visual-navigation-of-end-to-end-trained-agents.
Eagle: Large-Scale Learning of Turbulent Fluid Dynamics with Mesh Transformers
Feb 16, 2023Estimating fluid dynamics is classically done through the simulation and integration of numerical models solving the Navier-Stokes equations, which is computationally complex and time-consuming even on high-end hardware. This is a notoriously hard problem to solve, which has recently been addressed with machine learning, in particular graph neural networks (GNN) and variants trained and evaluated on datasets of static objects in static scenes with fixed geometry. We attempt to go beyond existing work in complexity and introduce a new model, method and benchmark. We propose EAGLE, a large-scale dataset of 1.1 million 2D meshes resulting from simulations of unsteady fluid dynamics caused by a moving flow source interacting with nonlinear scene structure, comprised of 600 different scenes of three different types. To perform future forecasting of pressure and velocity on the challenging EAGLE dataset, we introduce a new mesh transformer. It leverages node clustering, graph pooling and global attention to learn long-range dependencies between spatially distant data points without needing a large number of iterations, as existing GNN methods do. We show that our transformer outperforms state-of-the-art performance on, both, existing synthetic and real datasets and on EAGLE. Finally, we highlight that our approach learns to attend to airflow, integrating complex information in a single iteration.
* Published as a conference paper at ICLR 2023
Learning to estimate UAV created turbulence from scene structure observed by onboard cameras
Mar 28, 2022


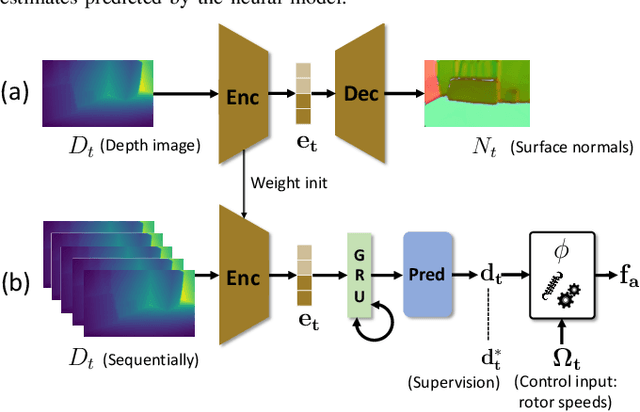
Controlling UAV flights precisely requires a realistic dynamic model and accurate state estimates from onboard sensors like UAV, GPS and visual observations. Obtaining a precise dynamic model is extremely difficult, as important aerodynamic effects are hard to model, in particular ground effect and other turbulences. While machine learning has been used in the past to estimate UAV created turbulence, this was restricted to flat grounds or diffuse in-flight air turbulences, both without taking into account obstacles. In this work we address the complex problem of estimating in-flight turbulences caused by obstacles, in particular the complex structures in cluttered environments. We learn a mapping from control input and images captured by onboard cameras to turbulence. In a large-scale setting, we train a model over a large number of different simulated photo-realistic environments loaded into the Habitat.AI simulator augmented with a dynamic UAV model and an analytic ground effect model. We transfer the model from simulation to a real environment and evaluate on real UAV flights from the EuRoC-MAV dataset, showing that the model is capable of good sim2real generalization performance. The dataset will be made publicly available upon acceptance.
MoCap-less Quantitative Evaluation of Ego-Pose Estimation Without Ground Truth Measurements
Feb 01, 2022
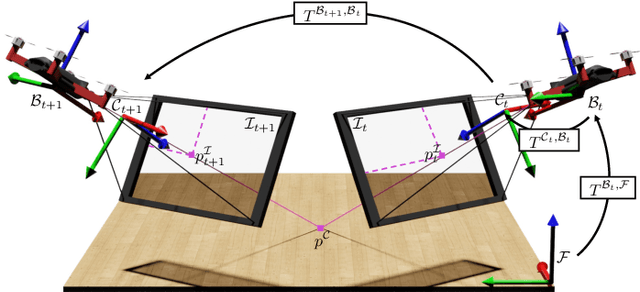

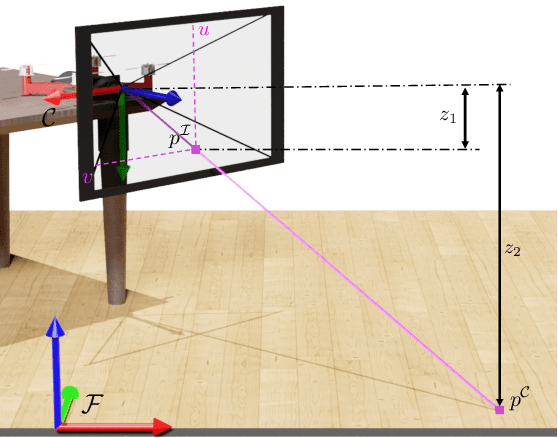
The emergence of data-driven approaches for control and planning in robotics have highlighted the need for developing experimental robotic platforms for data collection. However, their implementation is often complex and expensive, in particular for flying and terrestrial robots where the precise estimation of the position requires motion capture devices (MoCap) or Lidar. In order to simplify the use of a robotic platform dedicated to research on a wide range of indoor and outdoor environments, we present a data validation tool for ego-pose estimation that does not require any equipment other than the on-board camera. The method and tool allow a rapid, visual and quantitative evaluation of the quality of ego-pose sensors and are sensitive to different sources of flaws in the acquisition chain, ranging from desynchronization of the sensor flows to misevaluation of the geometric parameters of the robotic platform. Using computer vision, the information from the sensors is used to calculate the motion of a semantic scene point through its projection to the 2D image space of the on-board camera. The deviations of these keypoints from references created with a semi-automatic tool allow rapid and simple quality assessment of the data collected on the platform. To demonstrate the performance of our method, we evaluate it on two challenging standard UAV datasets as well as one dataset taken from a terrestrial robot.
Filtered-CoPhy: Unsupervised Learning of Counterfactual Physics in Pixel Space
Feb 01, 2022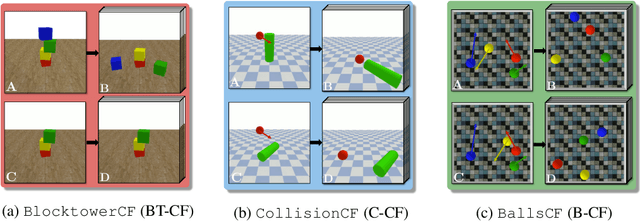
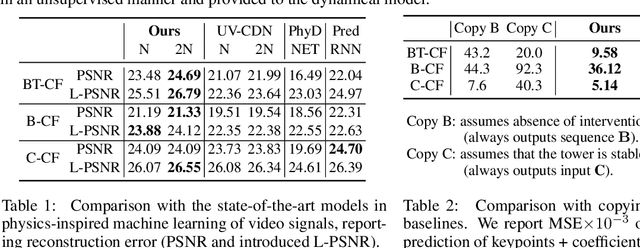
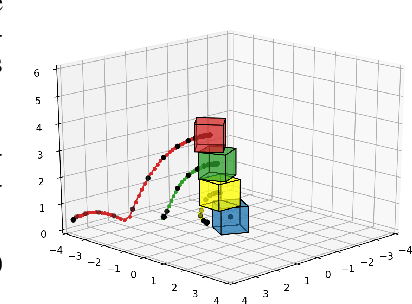
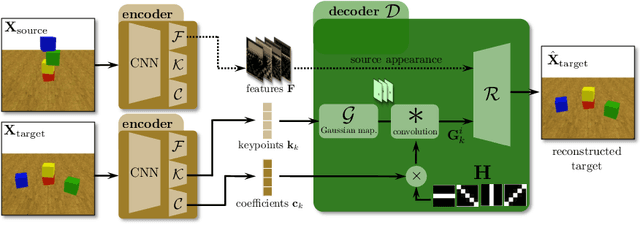
Learning causal relationships in high-dimensional data (images, videos) is a hard task, as they are often defined on low dimensional manifolds and must be extracted from complex signals dominated by appearance, lighting, textures and also spurious correlations in the data. We present a method for learning counterfactual reasoning of physical processes in pixel space, which requires the prediction of the impact of interventions on initial conditions. Going beyond the identification of structural relationships, we deal with the challenging problem of forecasting raw video over long horizons. Our method does not require the knowledge or supervision of any ground truth positions or other object or scene properties. Our model learns and acts on a suitable hybrid latent representation based on a combination of dense features, sets of 2D keypoints and an additional latent vector per keypoint. We show that this better captures the dynamics of physical processes than purely dense or sparse representations. We introduce a new challenging and carefully designed counterfactual benchmark for predictions in pixel space and outperform strong baselines in physics-inspired ML and video prediction.
Deep KKL: Data-driven Output Prediction for Non-Linear Systems
Mar 23, 2021
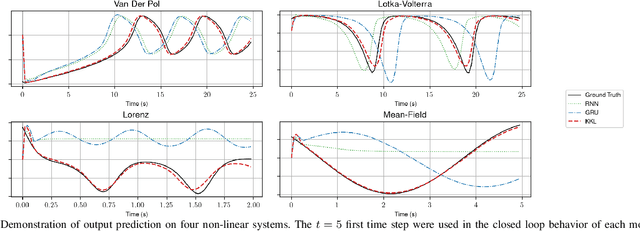
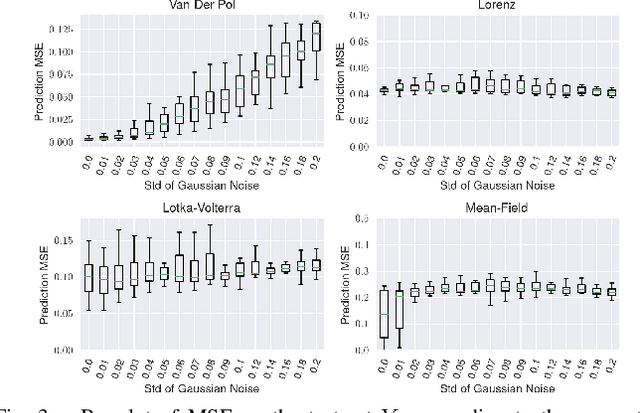

We address the problem of output prediction, ie. designing a model for autonomous nonlinear systems capable of forecasting their future observations. We first define a general framework bringing together the necessary properties for the development of such an output predictor. In particular, we look at this problem from two different viewpoints, control theory and data-driven techniques (machine learning), and try to formulate it in a consistent way, reducing the gap between the two fields. Building on this formulation and problem definition, we propose a predictor structure based on the Kazantzis-Kravaris/Luenberger (KKL) observer and we show that KKL fits well into our general framework. Finally, we propose a constructive solution for this predictor that solely relies on a small set of trajectories measured from the system. Our experiments show that our solution allows to obtain an efficient predictor over a subset of the observation space.
A New Loss Function for Temperature Scaling to have Better Calibrated Deep Networks
Oct 27, 2018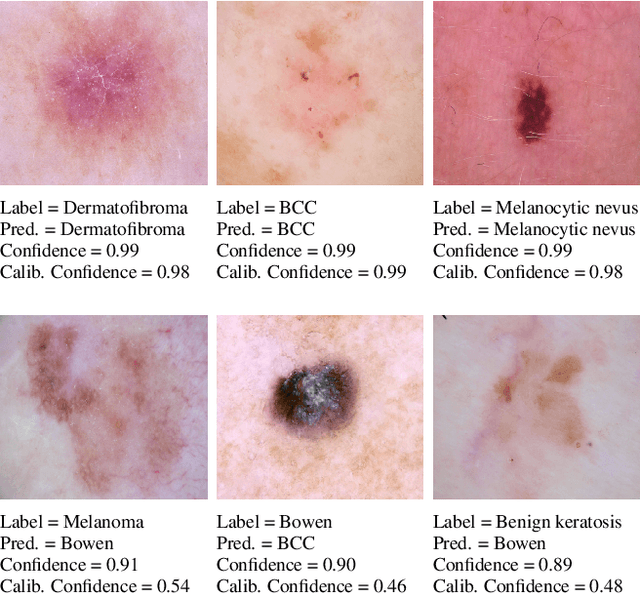
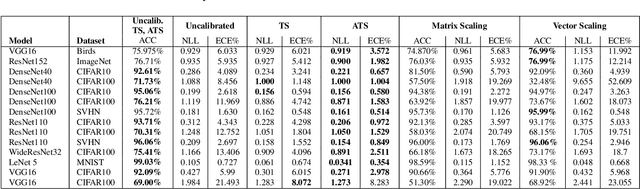
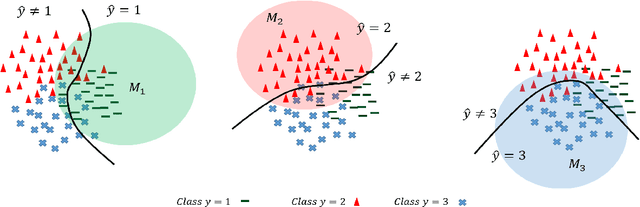
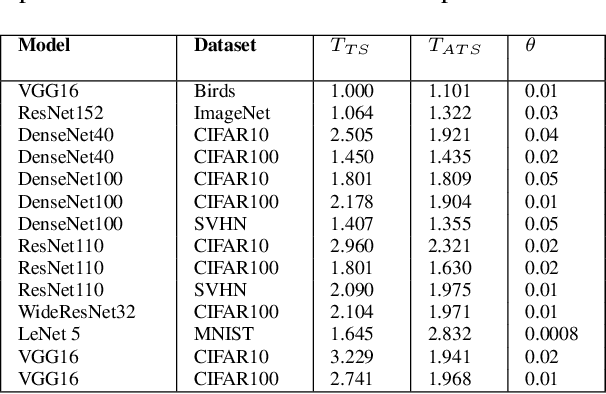
However Deep neural networks recently have achieved impressive results for different tasks, they suffer from poor uncertainty prediction. Temperature Scaling(TS) is an efficient post-processing method for calibrating DNNs toward to have more accurate uncertainty prediction. TS relies on a single parameter T which softens the logit layer of a DNN and the optimal value of it is found by minimizing on Negative Log Likelihood (NLL) loss function. In this paper, we discuss about weakness of NLL loss function, especially for DNNs with high accuracy and propose a new loss function called Attended-NLL which can improve TS calibration ability significantly