 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree-form language-based robotic reasoning and grasping
Mar 17, 2025
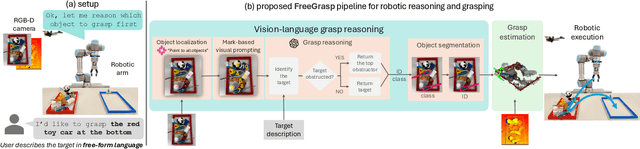


Performing robotic grasping from a cluttered bin based on human instructions is a challenging task, as it requires understanding both the nuances of free-form language and the spatial relationships between objects. Vision-Language Models (VLMs) trained on web-scale data, such as GPT-4o, have demonstrated remarkable reasoning capabilities across both text and images. But can they truly be used for this task in a zero-shot setting? And what are their limitations? In this paper, we explore these research questions via the free-form language-based robotic grasping task, and propose a novel method, FreeGrasp, leveraging the pre-trained VLMs' world knowledge to reason about human instructions and object spatial arrangements. Our method detects all objects as keypoints and uses these keypoints to annotate marks on images, aiming to facilitate GPT-4o's zero-shot spatial reasoning. This allows our method to determine whether a requested object is directly graspable or if other objects must be grasped and removed first. Since no existing dataset is specifically designed for this task, we introduce a synthetic dataset FreeGraspData by extending the MetaGraspNetV2 dataset with human-annotated instructions and ground-truth grasping sequences. We conduct extensive analyses with both FreeGraspData and real-world validation with a gripper-equipped robotic arm, demonstrating state-of-the-art performance in grasp reasoning and execution. Project website: https://tev-fbk.github.io/FreeGrasp/.
Reasoning in visual navigation of end-to-end trained agents: a dynamical systems approach
Mar 12, 2025Progress in Embodied AI has made it possible for end-to-end-trained agents to navigate in photo-realistic environments with high-level reasoning and zero-shot or language-conditioned behavior, but benchmarks are still dominated by simulation. In this work, we focus on the fine-grained behavior of fast-moving real robots and present a large-scale experimental study involving \numepisodes{} navigation episodes in a real environment with a physical robot, where we analyze the type of reasoning emerging from end-to-end training. In particular, we study the presence of realistic dynamics which the agent learned for open-loop forecasting, and their interplay with sensing. We analyze the way the agent uses latent memory to hold elements of the scene structure and information gathered during exploration. We probe the planning capabilities of the agent, and find in its memory evidence for somewhat precise plans over a limited horizon. Furthermore, we show in a post-hoc analysis that the value function learned by the agent relates to long-term planning. Put together, our experiments paint a new picture on how using tools from computer vision and sequential decision making have led to new capabilities in robotics and control. An interactive tool is available at europe.naverlabs.com/research/publications/reasoning-in-visual-navigation-of-end-to-end-trained-agents.
Functionality understanding and segmentation in 3D scenes
Nov 26, 2024Understanding functionalities in 3D scenes involves interpreting natural language descriptions to locate functional interactive objects, such as handles and buttons, in a 3D environment. Functionality understanding is highly challenging, as it requires both world knowledge to interpret language and spatial perception to identify fine-grained objects. For example, given a task like 'turn on the ceiling light', an embodied AI agent must infer that it needs to locate the light switch, even though the switch is not explicitly mentioned in the task description. To date, no dedicated methods have been developed for this problem. In this paper, we introduce Fun3DU, the first approach designed for functionality understanding in 3D scenes. Fun3DU uses a language model to parse the task description through Chain-of-Thought reasoning in order to identify the object of interest. The identified object is segmented across multiple views of the captured scene by using a vision and language model. The segmentation results from each view are lifted in 3D and aggregated into the point cloud using geometric information. Fun3DU is training-free, relying entirely on pre-trained models. We evaluate Fun3DU on SceneFun3D, the most recent and only dataset to benchmark this task, which comprises over 3000 task descriptions on 230 scenes. Our method significantly outperforms state-of-the-art open-vocabulary 3D segmentation approaches. Project page: https://jcorsetti.github.io/fun3du
High-resolution open-vocabulary object 6D pose estimation
Jun 24, 2024



The generalisation to unseen objects in the 6D pose estimation task is very challenging. While Vision-Language Models (VLMs) enable using natural language descriptions to support 6D pose estimation of unseen objects, these solutions underperform compared to model-based methods. In this work we present Horyon, an open-vocabulary VLM-based architecture that addresses relative pose estimation between two scenes of an unseen object, described by a textual prompt only. We use the textual prompt to identify the unseen object in the scenes and then obtain high-resolution multi-scale features. These features are used to extract cross-scene matches for registration. We evaluate our model on a benchmark with a large variety of unseen objects across four datasets, namely REAL275, Toyota-Light, Linemod, and YCB-Video. Our method achieves state-of-the-art performance on all datasets, outperforming by 12.6 in Average Recall the previous best-performing approach.
DiffAssemble: A Unified Graph-Diffusion Model for 2D and 3D Reassembly
Feb 29, 2024



Reassembly tasks play a fundamental role in many fields and multiple approaches exist to solve specific reassembly problems. In this context, we posit that a general unified model can effectively address them all, irrespective of the input data type (images, 3D, etc.). We introduce DiffAssemble, a Graph Neural Network (GNN)-based architecture that learns to solve reassembly tasks using a diffusion model formulation. Our method treats the elements of a set, whether pieces of 2D patch or 3D object fragments, as nodes of a spatial graph. Training is performed by introducing noise into the position and rotation of the elements and iteratively denoising them to reconstruct the coherent initial pose. DiffAssemble achieves state-of-the-art (SOTA) results in most 2D and 3D reassembly tasks and is the first learning-based approach that solves 2D puzzles for both rotation and translation. Furthermore, we highlight its remarkable reduction in run-time, performing 11 times faster than the quickest optimization-based method for puzzle solving. Code available at https://github.com/IIT-PAVIS/DiffAssemble
Positional Diffusion: Ordering Unordered Sets with Diffusion Probabilistic Models
Mar 20, 2023



Positional reasoning is the process of ordering unsorted parts contained in a set into a consistent structure. We present Positional Diffusion, a plug-and-play graph formulation with Diffusion Probabilistic Models to address positional reasoning. We use the forward process to map elements' positions in a set to random positions in a continuous space. Positional Diffusion learns to reverse the noising process and recover the original positions through an Attention-based Graph Neural Network. We conduct extensive experiments with benchmark datasets including two puzzle datasets, three sentence ordering datasets, and one visual storytelling dataset, demonstrating that our method outperforms long-lasting research on puzzle solving with up to +18% compared to the second-best deep learning method, and performs on par against the state-of-the-art methods on sentence ordering and visual storytelling. Our work highlights the suitability of diffusion models for ordering problems and proposes a novel formulation and method for solving various ordering tasks. Project website at https://iit-pavis.github.io/Positional_Diffusion/
Unsupervised Active Visual Search with Monte Carlo planning under Uncertain Detections
Mar 06, 2023



We propose a solution for Active Visual Search of objects in an environment, whose 2D floor map is the only known information. Our solution has three key features that make it more plausible and robust to detector failures compared to state-of-the-art methods: (i) it is unsupervised as it does not need any training sessions. (ii) During the exploration, a probability distribution on the 2D floor map is updated according to an intuitive mechanism, while an improved belief update increases the effectiveness of the agent's exploration. (iii) We incorporate the awareness that an object detector may fail into the aforementioned probability modelling by exploiting the success statistics of a specific detector. Our solution is dubbed POMP-BE-PD (Pomcp-based Online Motion Planning with Belief by Exploration and Probabilistic Detection). It uses the current pose of an agent and an RGB-D observation to learn an optimal search policy, exploiting a POMDP solved by a Monte-Carlo planning approach. On the Active Vision Database benchmark, we increase the average success rate over all the environments by a significant 35% while decreasing the average path length by 4% with respect to competing methods. Thus, our results are state-of-the-art, even without using any training procedure.
Leveraging commonsense for object localisation in partial scenes
Nov 01, 2022

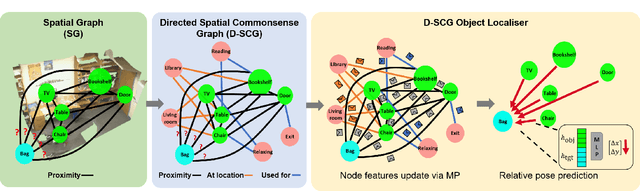

We propose an end-to-end solution to address the problem of object localisation in partial scenes, where we aim to estimate the position of an object in an unknown area given only a partial 3D scan of the scene. We propose a novel scene representation to facilitate the geometric reasoning, Directed Spatial Commonsense Graph (D-SCG), a spatial scene graph that is enriched with additional concept nodes from a commonsense knowledge base. Specifically, the nodes of D-SCG represent the scene objects and the edges are their relative positions. Each object node is then connected via different commonsense relationships to a set of concept nodes. With the proposed graph-based scene representation, we estimate the unknown position of the target object using a Graph Neural Network that implements a novel attentional message passing mechanism. The network first predicts the relative positions between the target object and each visible object by learning a rich representation of the objects via aggregating both the object nodes and the concept nodes in D-SCG. These relative positions then are merged to obtain the final position. We evaluate our method using Partial ScanNet, improving the state-of-the-art by 5.9% in terms of the localisation accuracy at a 8x faster training speed.
Under the Hood of Transformer Networks for Trajectory Forecasting
Mar 22, 2022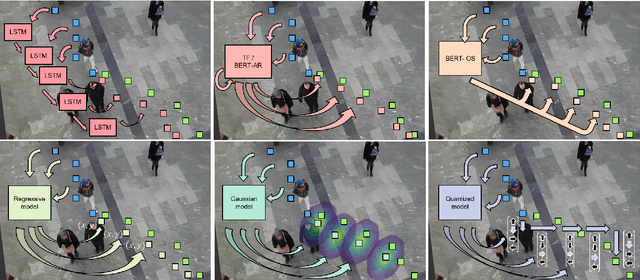
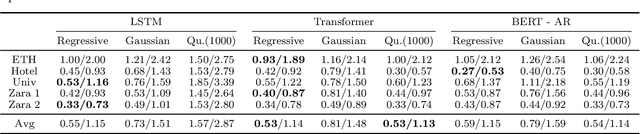
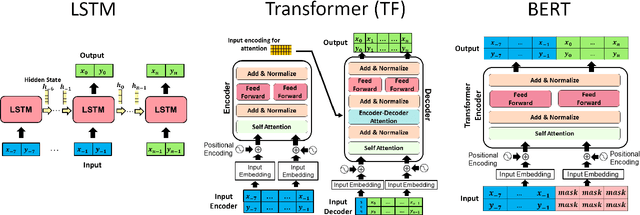
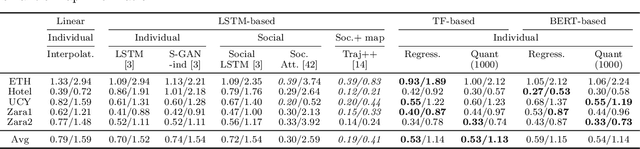
Transformer Networks have established themselves as the de-facto state-of-the-art for trajectory forecasting but there is currently no systematic study on their capability to model the motion patterns of people, without interactions with other individuals nor the social context. This paper proposes the first in-depth study of Transformer Networks (TF) and Bidirectional Transformers (BERT) for the forecasting of the individual motion of people, without bells and whistles. We conduct an exhaustive evaluation of input/output representations, problem formulations and sequence modeling, including a novel analysis of their capability to predict multi-modal futures. Out of comparative evaluation on the ETH+UCY benchmark, both TF and BERT are top performers in predicting individual motions, definitely overcoming RNNs and LSTMs. Furthermore, they remain within a narrow margin wrt more complex techniques, which include both social interactions and scene contexts. Source code will be released for all conducted experiments.
Spatial Commonsense Graph for Object Localisation in Partial Scenes
Mar 14, 2022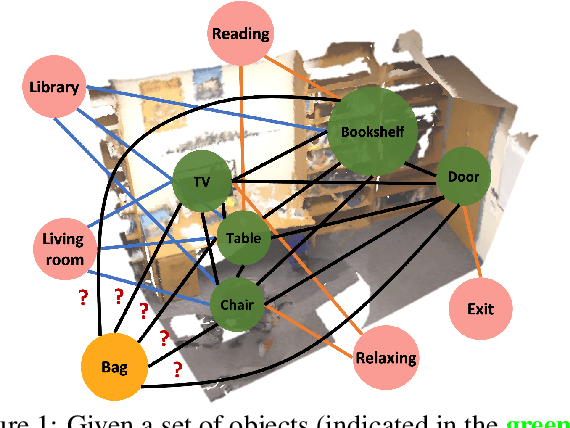
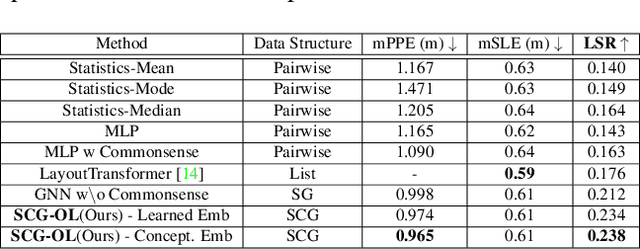
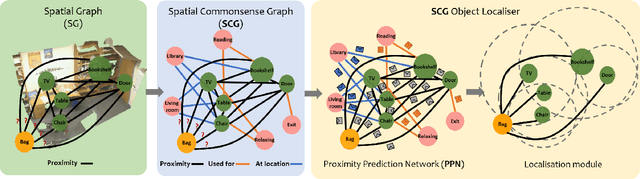
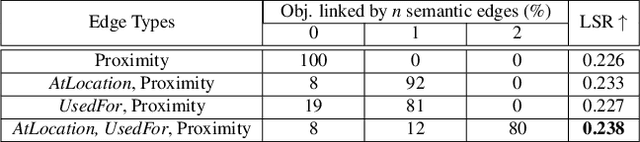
We solve object localisation in partial scenes, a new problem of estimating the unknown position of an object (e.g. where is the bag?) given a partial 3D scan of a scene. The proposed solution is based on a novel scene graph model, the Spatial Commonsense Graph (SCG), where objects are the nodes and edges define pairwise distances between them, enriched by concept nodes and relationships from a commonsense knowledge base. This allows SCG to better generalise its spatial inference over unknown 3D scenes. The SCG is used to estimate the unknown position of the target object in two steps: first, we feed the SCG into a novel Proximity Prediction Network, a graph neural network that uses attention to perform distance prediction between the node representing the target object and the nodes representing the observed objects in the SCG; second, we propose a Localisation Module based on circular intersection to estimate the object position using all the predicted pairwise distances in order to be independent of any reference system. We create a new dataset of partially reconstructed scenes to benchmark our method and baselines for object localisation in partial scenes, where our proposed method achieves the best localisation performance.