 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Interaction, Beyond Policy: a Reproducible Benchmark for Collaborative Instance Object Navigation
Mar 31, 2026We propose Question-Asking Navigation (QAsk-Nav), the first reproducible benchmark for Collaborative Instance Object Navigation (CoIN) that enables an explicit, separate assessment of embodied navigation and collaborative question asking. CoIN tasks an embodied agent with reaching a target specified in free-form natural language under partial observability, using only egocentric visual observations and interactive natural-language dialogue with a human, where the dialogue can help to resolve ambiguity among visually similar object instances. Existing CoIN benchmarks are primarily focused on navigation success and offer no support for consistent evaluation of collaborative interaction. To address this limitation, QAsk-Nav provides (i) a lightweight question-asking protocol scored independently of navigation, (ii) an enhanced navigation protocol with realistic, diverse, high-quality target descriptions, and (iii) an open-source dataset, that includes 28,000 quality-checked reasoning and question-asking traces for training and analysis of interactive capabilities of CoIN models. Using the proposed QAsk-Nav benchmark, we develop Light-CoNav, a lightweight unified model for collaborative navigation that is 3x smaller and 70x faster than existing modular methods, while outperforming state-of-the-art CoIN approaches in generalization to unseen objects and environments. Project page at https://benchmarking-interaction.github.io/
VISOR: VIsual Spatial Object Reasoning for Language-driven Object Navigation
Feb 07, 2026Language-driven object navigation requires agents to interpret natural language descriptions of target objects, which combine intrinsic and extrinsic attributes for instance recognition and commonsense navigation. Existing methods either (i) use end-to-end trained models with vision-language embeddings, which struggle to generalize beyond training data and lack action-level explainability, or (ii) rely on modular zero-shot pipelines with large language models (LLMs) and open-set object detectors, which suffer from error propagation, high computational cost, and difficulty integrating their reasoning back into the navigation policy. To this end, we propose a compact 3B-parameter Vision-Language-Action (VLA) agent that performs human-like embodied reasoning for both object recognition and action selection, removing the need for stitched multi-model pipelines. Instead of raw embedding matching, our agent employs explicit image-grounded reasoning to directly answer "Is this the target object?" and "Why should I take this action?" The reasoning process unfolds in three stages: "think", "think summary", and "action", yielding improved explainability, stronger generalization, and more efficient navigation. Code and dataset available upon acceptance.
Collaborative Instance Navigation: Leveraging Agent Self-Dialogue to Minimize User Input
Dec 02, 2024Existing embodied instance goal navigation tasks, driven by natural language, assume human users to provide complete and nuanced instance descriptions prior to the navigation, which can be impractical in the real world as human instructions might be brief and ambiguous. To bridge this gap, we propose a new task, Collaborative Instance Navigation (CoIN), with dynamic agent-human interaction during navigation to actively resolve uncertainties about the target instance in natural, template-free, open-ended dialogues. To address CoIN, we propose a novel method, Agent-user Interaction with UncerTainty Awareness (AIUTA), leveraging the perception capability of Vision Language Models (VLMs) and the capability of Large Language Models (LLMs). First, upon object detection, a Self-Questioner model initiates a self-dialogue to obtain a complete and accurate observation description, while a novel uncertainty estimation technique mitigates inaccurate VLM perception. Then, an Interaction Trigger module determines whether to ask a question to the user, continue or halt navigation, minimizing user input. For evaluation, we introduce CoIN-Bench, a benchmark supporting both real and simulated humans. AIUTA achieves competitive performance in instance navigation against state-of-the-art methods, demonstrating great flexibility in handling user inputs.
I2EDL: Interactive Instruction Error Detection and Localization
Jun 07, 2024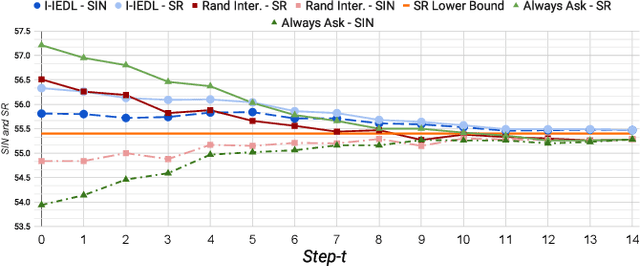

In the Vision-and-Language Navigation in Continuous Environments (VLN-CE) task, the human user guides an autonomous agent to reach a target goal via a series of low-level actions following a textual instruction in natural language. However, most existing methods do not address the likely case where users may make mistakes when providing such instruction (e.g. "turn left" instead of "turn right"). In this work, we address a novel task of Interactive VLN in Continuous Environments (IVLN-CE), which allows the agent to interact with the user during the VLN-CE navigation to verify any doubts regarding the instruction errors. We propose an Interactive Instruction Error Detector and Localizer (I2EDL) that triggers the user-agent interaction upon the detection of instruction errors during the navigation. We leverage a pre-trained module to detect instruction errors and pinpoint them in the instruction by cross-referencing the textual input and past observations. In such way, the agent is able to query the user for a timely correction, without demanding the user's cognitive load, as we locate the probable errors to a precise part of the instruction. We evaluate the proposed I2EDL on a dataset of instructions containing errors, and further devise a novel metric, the Success weighted by Interaction Number (SIN), to reflect both the navigation performance and the interaction effectiveness. We show how the proposed method can ask focused requests for corrections to the user, which in turn increases the navigation success, while minimizing the interactions.
Diffusion-based Image Generation for In-distribution Data Augmentation in Surface Defect Detection
Jun 01, 2024In this study, we show that diffusion models can be used in industrial scenarios to improve the data augmentation procedure in the context of surface defect detection. In general, defect detection classifiers are trained on ground-truth data formed by normal samples (negative data) and samples with defects (positive data), where the latter are consistently fewer than normal samples. For these reasons, state-of-the-art data augmentation procedures add synthetic defect data by superimposing artifacts to normal samples. This leads to out-of-distribution augmented data so that the classification system learns what is not a normal sample but does not know what a defect really is. We show that diffusion models overcome this situation, providing more realistic in-distribution defects so that the model can learn the defect's genuine appearance. We propose a novel approach for data augmentation that mixes out-of-distribution with in-distribution samples, which we call In&Out. The approach can deal with two data augmentation setups: i) when no defects are available (zero-shot data augmentation) and ii) when defects are available, which can be in a small number (few-shot) or a large one (full-shot). We focus the experimental part on the most challenging benchmark in the state-of-the-art, i.e., the Kolektor Surface-Defect Dataset 2, defining the new state-of-the-art classification AP score under weak supervision of .782. The code is available at https://github.com/intelligolabs/in_and_out.
Mind the Error! Detection and Localization of Instruction Errors in Vision-and-Language Navigation
Mar 15, 2024



Vision-and-Language Navigation in Continuous Environments (VLN-CE) is one of the most intuitive yet challenging embodied AI tasks. Agents are tasked to navigate towards a target goal by executing a set of low-level actions, following a series of natural language instructions. All VLN-CE methods in the literature assume that language instructions are exact. However, in practice, instructions given by humans can contain errors when describing a spatial environment due to inaccurate memory or confusion. Current VLN-CE benchmarks do not address this scenario, making the state-of-the-art methods in VLN-CE fragile in the presence of erroneous instructions from human users. For the first time, we propose a novel benchmark dataset that introduces various types of instruction errors considering potential human causes. This benchmark provides valuable insight into the robustness of VLN systems in continuous environments. We observe a noticeable performance drop (up to -25%) in Success Rate when evaluating the state-of-the-art VLN-CE methods on our benchmark. Moreover, we formally define the task of Instruction Error Detection and Localization, and establish an evaluation protocol on top of our benchmark dataset. We also propose an effective method, based on a cross-modal transformer architecture, that achieves the best performance in error detection and localization, compared to baselines. Surprisingly, our proposed method has revealed errors in the validation set of the two commonly used datasets for VLN-CE, i.e., R2R-CE and RxR-CE, demonstrating the utility of our technique in other tasks. Code and dataset will be made available upon acceptance at https://intelligolabs.github.io/R2RIE-CE
Language-enhanced RNR-Map: Querying Renderable Neural Radiance Field maps with natural language
Aug 17, 2023



We present Le-RNR-Map, a Language-enhanced Renderable Neural Radiance map for Visual Navigation with natural language query prompts. The recently proposed RNR-Map employs a grid structure comprising latent codes positioned at each pixel. These latent codes, which are derived from image observation, enable: i) image rendering given a camera pose, since they are converted to Neural Radiance Field; ii) image navigation and localization with astonishing accuracy. On top of this, we enhance RNR-Map with CLIP-based embedding latent codes, allowing natural language search without additional label data. We evaluate the effectiveness of this map in single and multi-object searches. We also investigate its compatibility with a Large Language Model as an "affordance query resolver". Code and videos are available at https://intelligolabs.github.io/Le-RNR-Map/
Unsupervised Active Visual Search with Monte Carlo planning under Uncertain Detections
Mar 06, 2023



We propose a solution for Active Visual Search of objects in an environment, whose 2D floor map is the only known information. Our solution has three key features that make it more plausible and robust to detector failures compared to state-of-the-art methods: (i) it is unsupervised as it does not need any training sessions. (ii) During the exploration, a probability distribution on the 2D floor map is updated according to an intuitive mechanism, while an improved belief update increases the effectiveness of the agent's exploration. (iii) We incorporate the awareness that an object detector may fail into the aforementioned probability modelling by exploiting the success statistics of a specific detector. Our solution is dubbed POMP-BE-PD (Pomcp-based Online Motion Planning with Belief by Exploration and Probabilistic Detection). It uses the current pose of an agent and an RGB-D observation to learn an optimal search policy, exploiting a POMDP solved by a Monte-Carlo planning approach. On the Active Vision Database benchmark, we increase the average success rate over all the environments by a significant 35% while decreasing the average path length by 4% with respect to competing methods. Thus, our results are state-of-the-art, even without using any training procedure.