 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Interaction, Beyond Policy: a Reproducible Benchmark for Collaborative Instance Object Navigation
Mar 31, 2026We propose Question-Asking Navigation (QAsk-Nav), the first reproducible benchmark for Collaborative Instance Object Navigation (CoIN) that enables an explicit, separate assessment of embodied navigation and collaborative question asking. CoIN tasks an embodied agent with reaching a target specified in free-form natural language under partial observability, using only egocentric visual observations and interactive natural-language dialogue with a human, where the dialogue can help to resolve ambiguity among visually similar object instances. Existing CoIN benchmarks are primarily focused on navigation success and offer no support for consistent evaluation of collaborative interaction. To address this limitation, QAsk-Nav provides (i) a lightweight question-asking protocol scored independently of navigation, (ii) an enhanced navigation protocol with realistic, diverse, high-quality target descriptions, and (iii) an open-source dataset, that includes 28,000 quality-checked reasoning and question-asking traces for training and analysis of interactive capabilities of CoIN models. Using the proposed QAsk-Nav benchmark, we develop Light-CoNav, a lightweight unified model for collaborative navigation that is 3x smaller and 70x faster than existing modular methods, while outperforming state-of-the-art CoIN approaches in generalization to unseen objects and environments. Project page at https://benchmarking-interaction.github.io/
StruXLIP: Enhancing Vision-language Models with Multimodal Structural Cues
Feb 25, 2026Edge-based representations are fundamental cues for visual understanding, a principle rooted in early vision research and still central today. We extend this principle to vision-language alignment, showing that isolating and aligning structural cues across modalities can greatly benefit fine-tuning on long, detail-rich captions, with a specific focus on improving cross-modal retrieval. We introduce StruXLIP, a fine-tuning alignment paradigm that extracts edge maps (e.g., Canny), treating them as proxies for the visual structure of an image, and filters the corresponding captions to emphasize structural cues, making them "structure-centric". Fine-tuning augments the standard alignment loss with three structure-centric losses: (i) aligning edge maps with structural text, (ii) matching local edge regions to textual chunks, and (iii) connecting edge maps to color images to prevent representation drift. From a theoretical standpoint, while standard CLIP maximizes the mutual information between visual and textual embeddings, StruXLIP additionally maximizes the mutual information between multimodal structural representations. This auxiliary optimization is intrinsically harder, guiding the model toward more robust and semantically stable minima, enhancing vision-language alignment. Beyond outperforming current competitors on cross-modal retrieval in both general and specialized domains, our method serves as a general boosting recipe that can be integrated into future approaches in a plug-and-play manner. Code and pretrained models are publicly available at: https://github.com/intelligolabs/StruXLIP.
VISOR: VIsual Spatial Object Reasoning for Language-driven Object Navigation
Feb 07, 2026Language-driven object navigation requires agents to interpret natural language descriptions of target objects, which combine intrinsic and extrinsic attributes for instance recognition and commonsense navigation. Existing methods either (i) use end-to-end trained models with vision-language embeddings, which struggle to generalize beyond training data and lack action-level explainability, or (ii) rely on modular zero-shot pipelines with large language models (LLMs) and open-set object detectors, which suffer from error propagation, high computational cost, and difficulty integrating their reasoning back into the navigation policy. To this end, we propose a compact 3B-parameter Vision-Language-Action (VLA) agent that performs human-like embodied reasoning for both object recognition and action selection, removing the need for stitched multi-model pipelines. Instead of raw embedding matching, our agent employs explicit image-grounded reasoning to directly answer "Is this the target object?" and "Why should I take this action?" The reasoning process unfolds in three stages: "think", "think summary", and "action", yielding improved explainability, stronger generalization, and more efficient navigation. Code and dataset available upon acceptance.
Uncertainty Aware-Predictive Control Barrier Functions: Safer Human Robot Interaction through Probabilistic Motion Forecasting
Aug 28, 2025To enable flexible, high-throughput automation in settings where people and robots share workspaces, collaborative robotic cells must reconcile stringent safety guarantees with the need for responsive and effective behavior. A dynamic obstacle is the stochastic, task-dependent variability of human motion: when robots fall back on purely reactive or worst-case envelopes, they brake unnecessarily, stall task progress, and tamper with the fluidity that true Human-Robot Interaction demands. In recent years, learning-based human-motion prediction has rapidly advanced, although most approaches produce worst-case scenario forecasts that often do not treat prediction uncertainty in a well-structured way, resulting in over-conservative planning algorithms, limiting their flexibility. We introduce Uncertainty-Aware Predictive Control Barrier Functions (UA-PCBFs), a unified framework that fuses probabilistic human hand motion forecasting with the formal safety guarantees of Control Barrier Functions. In contrast to other variants, our framework allows for dynamic adjustment of the safety margin thanks to the human motion uncertainty estimation provided by a forecasting module. Thanks to uncertainty estimation, UA-PCBFs empower collaborative robots with a deeper understanding of future human states, facilitating more fluid and intelligent interactions through informed motion planning. We validate UA-PCBFs through comprehensive real-world experiments with an increasing level of realism, including automated setups (to perform exactly repeatable motions) with a robotic hand and direct human-robot interactions (to validate promptness, usability, and human confidence). Relative to state-of-the-art HRI architectures, UA-PCBFs show better performance in task-critical metrics, significantly reducing the number of violations of the robot's safe space during interaction with respect to the state-of-the-art.
Robust Anomaly Detection in Industrial Environments via Meta-Learning
Aug 25, 2025Anomaly detection is fundamental for ensuring quality control and operational efficiency in industrial environments, yet conventional approaches face significant challenges when training data contains mislabeled samples-a common occurrence in real-world scenarios. This paper presents RAD, a robust anomaly detection framework that integrates Normalizing Flows with Model-Agnostic Meta-Learning to address the critical challenge of label noise in industrial settings. Our approach employs a bi-level optimization strategy where meta-learning enables rapid adaptation to varying noise conditions, while uncertainty quantification guides adaptive L2 regularization to maintain model stability. The framework incorporates multiscale feature processing through pretrained feature extractors and leverages the precise likelihood estimation capabilities of Normalizing Flows for robust anomaly scoring. Comprehensive evaluation on MVTec-AD and KSDD2 datasets demonstrates superior performance, achieving I-AUROC scores of 95.4% and 94.6% respectively under clean conditions, while maintaining robust detection capabilities above 86.8% and 92.1% even when 50% of training samples are mislabeled. The results highlight RAD's exceptional resilience to noisy training conditions and its ability to detect subtle anomalies across diverse industrial scenarios, making it a practical solution for real-world anomaly detection applications where perfect data curation is challenging.
A Contrastive Learning-Guided Confident Meta-learning for Zero Shot Anomaly Detection
Aug 25, 2025Industrial and medical anomaly detection faces critical challenges from data scarcity and prohibitive annotation costs, particularly in evolving manufacturing and healthcare settings. To address this, we propose CoZAD, a novel zero-shot anomaly detection framework that integrates soft confident learning with meta-learning and contrastive feature representation. Unlike traditional confident learning that discards uncertain samples, our method assigns confidence-based weights to all training data, preserving boundary information while emphasizing prototypical normal patterns. The framework quantifies data uncertainty through IQR-based thresholding and model uncertainty via covariance based regularization within a Model-Agnostic Meta-Learning. Contrastive learning creates discriminative feature spaces where normal patterns form compact clusters, enabling rapid domain adaptation. Comprehensive evaluation across 10 datasets spanning industrial and medical domains demonstrates state-of-the-art performance, outperforming existing methods on 6 out of 7 industrial benchmarks with notable improvements on texture-rich datasets (99.2% I-AUROC on DTD-Synthetic, 97.2% on BTAD) and pixellevel localization (96.3% P-AUROC on MVTec-AD). The framework eliminates dependence on vision-language alignments or model ensembles, making it valuable for resourceconstrained environments requiring rapid deployment.
LOTS of Fashion! Multi-Conditioning for Image Generation via Sketch-Text Pairing
Jul 30, 2025



Fashion design is a complex creative process that blends visual and textual expressions. Designers convey ideas through sketches, which define spatial structure and design elements, and textual descriptions, capturing material, texture, and stylistic details. In this paper, we present LOcalized Text and Sketch for fashion image generation (LOTS), an approach for compositional sketch-text based generation of complete fashion outlooks. LOTS leverages a global description with paired localized sketch + text information for conditioning and introduces a novel step-based merging strategy for diffusion adaptation. First, a Modularized Pair-Centric representation encodes sketches and text into a shared latent space while preserving independent localized features; then, a Diffusion Pair Guidance phase integrates both local and global conditioning via attention-based guidance within the diffusion model's multi-step denoising process. To validate our method, we build on Fashionpedia to release Sketchy, the first fashion dataset where multiple text-sketch pairs are provided per image. Quantitative results show LOTS achieves state-of-the-art image generation performance on both global and localized metrics, while qualitative examples and a human evaluation study highlight its unprecedented level of design customization.
Seeing the Abstract: Translating the Abstract Language for Vision Language Models
May 06, 2025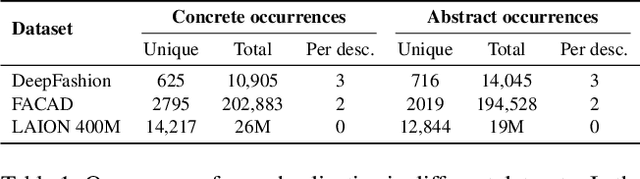


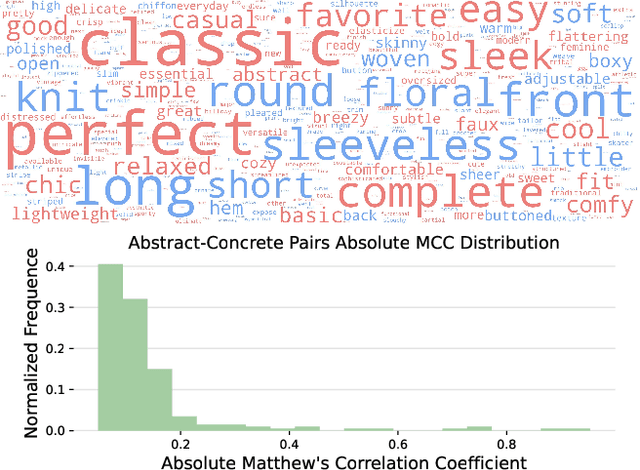
Natural language goes beyond dryly describing visual content. It contains rich abstract concepts to express feeling, creativity and properties that cannot be directly perceived. Yet, current research in Vision Language Models (VLMs) has not shed light on abstract-oriented language. Our research breaks new ground by uncovering its wide presence and under-estimated value, with extensive analysis. Particularly, we focus our investigation on the fashion domain, a highly-representative field with abstract expressions. By analyzing recent large-scale multimodal fashion datasets, we find that abstract terms have a dominant presence, rivaling the concrete ones, providing novel information, and being useful in the retrieval task. However, a critical challenge emerges: current general-purpose or fashion-specific VLMs are pre-trained with databases that lack sufficient abstract words in their text corpora, thus hindering their ability to effectively represent abstract-oriented language. We propose a training-free and model-agnostic method, Abstract-to-Concrete Translator (ACT), to shift abstract representations towards well-represented concrete ones in the VLM latent space, using pre-trained models and existing multimodal databases. On the text-to-image retrieval task, despite being training-free, ACT outperforms the fine-tuned VLMs in both same- and cross-dataset settings, exhibiting its effectiveness with a strong generalization capability. Moreover, the improvement introduced by ACT is consistent with various VLMs, making it a plug-and-play solution.
Meta Learning-Driven Iterative Refinement for Robust Anomaly Detection in Industrial Inspection
Mar 03, 2025



This study investigates the performance of robust anomaly detection models in industrial inspection, focusing particularly on their ability to handle noisy data. We propose to leverage the adaptation ability of meta learning approaches to identify and reject noisy training data to improve the learning process. In our model, we employ Model Agnostic Meta Learning (MAML) and an iterative refinement process through an Inter-Quartile Range rejection scheme to enhance their adaptability and robustness. This approach significantly improves the models capability to distinguish between normal and defective conditions. Our results of experiments conducted on well known MVTec and KSDD2 datasets demonstrate that the proposed method not only excels in environments with substantial noise but can also contribute in case of a clear training set, isolating those samples that are relatively out of distribution, thus offering significant improvements over traditional models.
A Mutual Information Perspective on Multiple Latent Variable Generative Models for Positive View Generation
Jan 23, 2025



In image generation, Multiple Latent Variable Generative Models (MLVGMs) employ multiple latent variables to gradually shape the final images, from global characteristics to finer and local details (e.g., StyleGAN, NVAE), emerging as powerful tools for diverse applications. Yet their generative dynamics and latent variable utilization remain only empirically observed. In this work, we propose a novel framework to systematically quantify the impact of each latent variable in MLVGMs, using Mutual Information (MI) as a guiding metric. Our analysis reveals underutilized variables and can guide the use of MLVGMs in downstream applications. With this foundation, we introduce a method for generating synthetic data for Self-Supervised Contrastive Representation Learning (SSCRL). By leveraging the hierarchical and disentangled variables of MLVGMs, and guided by the previous analysis, we apply tailored latent perturbations to produce diverse views for SSCRL, without relying on real data altogether. Additionally, we introduce a Continuous Sampling (CS) strategy, where the generator dynamically creates new samples during SSCRL training, greatly increasing data variability. Our comprehensive experiments demonstrate the effectiveness of these contributions, showing that MLVGMs' generated views compete on par with or even surpass views generated from real data. This work establishes a principled approach to understanding and exploiting MLVGMs, advancing both generative modeling and self-supervised learning.