 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Aware-Predictive Control Barrier Functions: Safer Human Robot Interaction through Probabilistic Motion Forecasting
Aug 28, 2025To enable flexible, high-throughput automation in settings where people and robots share workspaces, collaborative robotic cells must reconcile stringent safety guarantees with the need for responsive and effective behavior. A dynamic obstacle is the stochastic, task-dependent variability of human motion: when robots fall back on purely reactive or worst-case envelopes, they brake unnecessarily, stall task progress, and tamper with the fluidity that true Human-Robot Interaction demands. In recent years, learning-based human-motion prediction has rapidly advanced, although most approaches produce worst-case scenario forecasts that often do not treat prediction uncertainty in a well-structured way, resulting in over-conservative planning algorithms, limiting their flexibility. We introduce Uncertainty-Aware Predictive Control Barrier Functions (UA-PCBFs), a unified framework that fuses probabilistic human hand motion forecasting with the formal safety guarantees of Control Barrier Functions. In contrast to other variants, our framework allows for dynamic adjustment of the safety margin thanks to the human motion uncertainty estimation provided by a forecasting module. Thanks to uncertainty estimation, UA-PCBFs empower collaborative robots with a deeper understanding of future human states, facilitating more fluid and intelligent interactions through informed motion planning. We validate UA-PCBFs through comprehensive real-world experiments with an increasing level of realism, including automated setups (to perform exactly repeatable motions) with a robotic hand and direct human-robot interactions (to validate promptness, usability, and human confidence). Relative to state-of-the-art HRI architectures, UA-PCBFs show better performance in task-critical metrics, significantly reducing the number of violations of the robot's safe space during interaction with respect to the state-of-the-art.
Material synthesis through simulations guided by machine learning: a position paper
Nov 21, 2024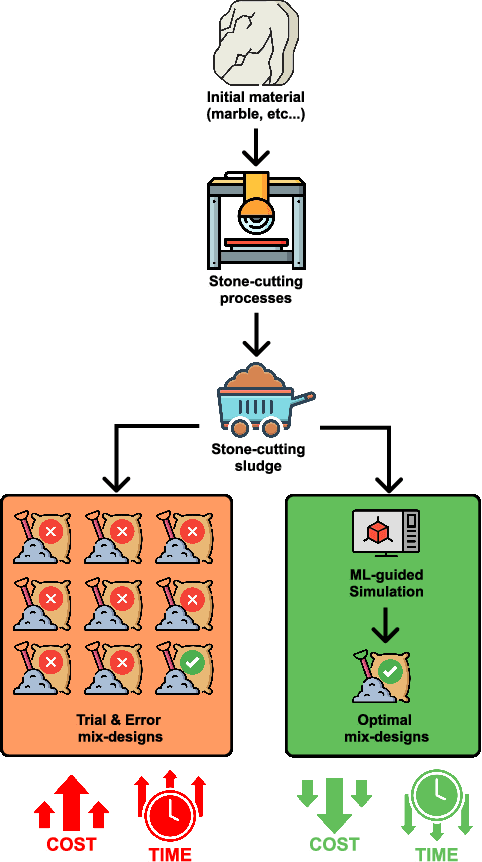
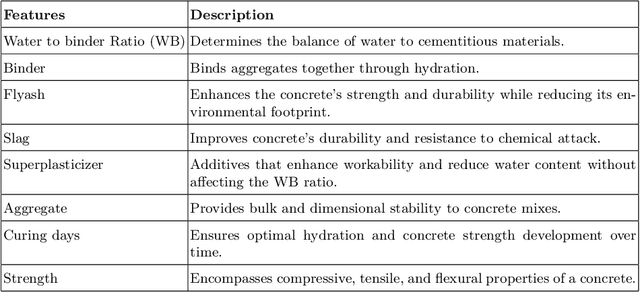
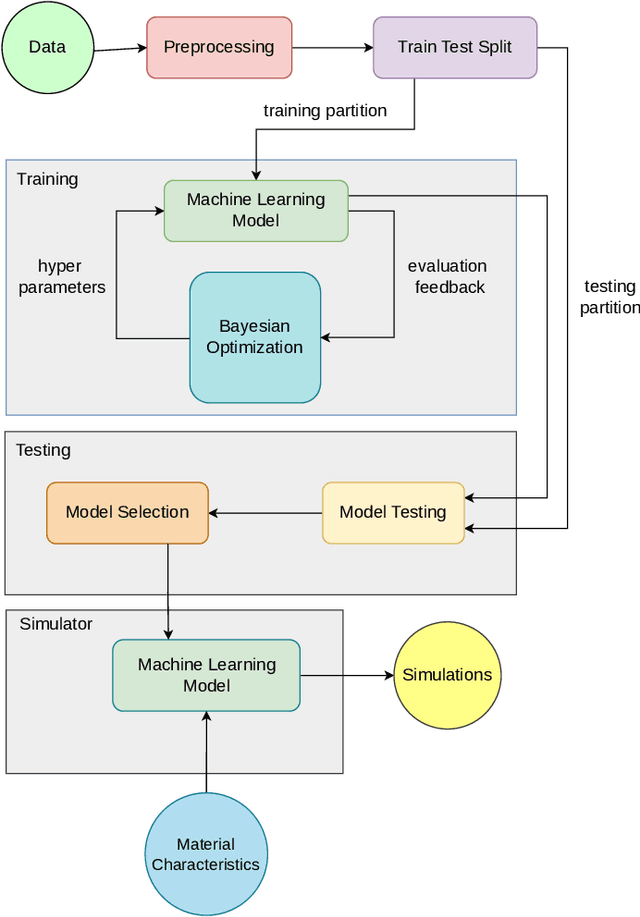

In this position paper, we propose an approach for sustainable data collection in the field of optimal mix design for marble sludge reuse. Marble sludge, a calcium-rich residual from stone-cutting processes, can be repurposed by mixing it with various ingredients. However, determining the optimal mix design is challenging due to the variability in sludge composition and the costly, time-consuming nature of experimental data collection. Also, we investigate the possibility of using machine learning models using meta-learning as an optimization tool to estimate the correct quantity of stone-cutting sludge to be used in aggregates to obtain a mix design with specific mechanical properties that can be used successfully in the building industry. Our approach offers two key advantages: (i) through simulations, a large dataset can be generated, saving time and money during the data collection phase, and (ii) Utilizing machine learning models, with performance enhancement through hyper-parameter optimization via meta-learning, to estimate optimal mix designs reducing the need for extensive manual experimentation, lowering costs, minimizing environmental impact, and accelerating the processing of quarry sludge. Our idea promises to streamline the marble sludge reuse process by leveraging collective data and advanced machine learning, promoting sustainability and efficiency in the stonecutting sector.
Learning based Ge'ez character handwritten recognition
Nov 20, 2024Ge'ez, an ancient Ethiopic script of cultural and historical significance, has been largely neglected in handwriting recognition research, hindering the digitization of valuable manuscripts. Our study addresses this gap by developing a state-of-the-art Ge'ez handwriting recognition system using Convolutional Neural Networks (CNNs) and Long Short-Term Memory (LSTM) networks. Our approach uses a two-stage recognition process. First, a CNN is trained to recognize individual characters, which then acts as a feature extractor for an LSTM-based system for word recognition. Our dual-stage recognition approach achieves new top scores in Ge'ez handwriting recognition, outperforming eight state-of-the-art methods, which are SVTR, ASTER, and others as well as human performance, as measured in the HHD-Ethiopic dataset work. This research significantly advances the preservation and accessibility of Ge'ez cultural heritage, with implications for historical document digitization, educational tools, and cultural preservation. The code will be released upon acceptance.
Multi-Camera Industrial Open-Set Person Re-Identification and Tracking
Sep 05, 2024In recent years, the development of deep learning approaches for the task of person re-identification led to impressive results. However, this comes with a limitation for industrial and practical real-world applications. Firstly, most of the existing works operate on closed-world scenarios, in which the people to re-identify (probes) are compared to a closed-set (gallery). Real-world scenarios often are open-set problems in which the gallery is not known a priori, but the number of open-set approaches in the literature is significantly lower. Secondly, challenges such as multi-camera setups, occlusions, real-time requirements, etc., further constrain the applicability of off-the-shelf methods. This work presents MICRO-TRACK, a Modular Industrial multi-Camera Re_identification and Open-set Tracking system that is real-time, scalable, and easy to integrate into existing industrial surveillance scenarios. Furthermore, we release a novel Re-ID and tracking dataset acquired in an industrial manufacturing facility, dubbed Facility-ReID, consisting of 18-minute videos captured by 8 surveillance cameras.
Exploring 3D Human Pose Estimation and Forecasting from the Robot's Perspective: The HARPER Dataset
Mar 23, 2024



We introduce HARPER, a novel dataset for 3D body pose estimation and forecast in dyadic interactions between users and Spot, the quadruped robot manufactured by Boston Dynamics. The key-novelty is the focus on the robot's perspective, i.e., on the data captured by the robot's sensors. These make 3D body pose analysis challenging because being close to the ground captures humans only partially. The scenario underlying HARPER includes 15 actions, of which 10 involve physical contact between the robot and users. The Corpus contains not only the recordings of the built-in stereo cameras of Spot, but also those of a 6-camera OptiTrack system (all recordings are synchronized). This leads to ground-truth skeletal representations with a precision lower than a millimeter. In addition, the Corpus includes reproducible benchmarks on 3D Human Pose Estimation, Human Pose Forecasting, and Collision Prediction, all based on publicly available baseline approaches. This enables future HARPER users to rigorously compare their results with those we provide in this work.
A Machine Learning-oriented Survey on Tiny Machine Learning
Sep 26, 2023

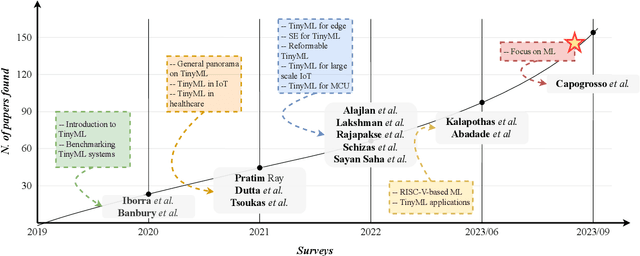

The emergence of Tiny Machine Learning (TinyML) has positively revolutionized the field of Artificial Intelligence by promoting the joint design of resource-constrained IoT hardware devices and their learning-based software architectures. TinyML carries an essential role within the fourth and fifth industrial revolutions in helping societies, economies, and individuals employ effective AI-infused computing technologies (e.g., smart cities, automotive, and medical robotics). Given its multidisciplinary nature, the field of TinyML has been approached from many different angles: this comprehensive survey wishes to provide an up-to-date overview focused on all the learning algorithms within TinyML-based solutions. The survey is based on the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) methodological flow, allowing for a systematic and complete literature survey. In particular, firstly we will examine the three different workflows for implementing a TinyML-based system, i.e., ML-oriented, HW-oriented, and co-design. Secondly, we propose a taxonomy that covers the learning panorama under the TinyML lens, examining in detail the different families of model optimization and design, as well as the state-of-the-art learning techniques. Thirdly, this survey will present the distinct features of hardware devices and software tools that represent the current state-of-the-art for TinyML intelligent edge applications. Finally, we discuss the challenges and future directions.
Language-enhanced RNR-Map: Querying Renderable Neural Radiance Field maps with natural language
Aug 17, 2023



We present Le-RNR-Map, a Language-enhanced Renderable Neural Radiance map for Visual Navigation with natural language query prompts. The recently proposed RNR-Map employs a grid structure comprising latent codes positioned at each pixel. These latent codes, which are derived from image observation, enable: i) image rendering given a camera pose, since they are converted to Neural Radiance Field; ii) image navigation and localization with astonishing accuracy. On top of this, we enhance RNR-Map with CLIP-based embedding latent codes, allowing natural language search without additional label data. We evaluate the effectiveness of this map in single and multi-object searches. We also investigate its compatibility with a Large Language Model as an "affordance query resolver". Code and videos are available at https://intelligolabs.github.io/Le-RNR-Map/
Markerless human pose estimation for biomedical applications: a survey
Aug 01, 2023Markerless Human Pose Estimation (HPE) proved its potential to support decision making and assessment in many fields of application. HPE is often preferred to traditional marker-based Motion Capture systems due to the ease of setup, portability, and affordable cost of the technology. However, the exploitation of HPE in biomedical applications is still under investigation. This review aims to provide an overview of current biomedical applications of HPE. In this paper, we examine the main features of HPE approaches and discuss whether or not those features are of interest to biomedical applications. We also identify those areas where HPE is already in use and present peculiarities and trends followed by researchers and practitioners. We include here 25 approaches to HPE and more than 40 studies of HPE applied to motor development assessment, neuromuscolar rehabilitation, and gait & posture analysis. We conclude that markerless HPE offers great potential for extending diagnosis and rehabilitation outside hospitals and clinics, toward the paradigm of remote medical care.
OO-dMVMT: A Deep Multi-view Multi-task Classification Framework for Real-time 3D Hand Gesture Classification and Segmentation
Apr 12, 2023Continuous mid-air hand gesture recognition based on captured hand pose streams is fundamental for human-computer interaction, particularly in AR / VR. However, many of the methods proposed to recognize heterogeneous hand gestures are tested only on the classification task, and the real-time low-latency gesture segmentation in a continuous stream is not well addressed in the literature. For this task, we propose the On-Off deep Multi-View Multi-Task paradigm (OO-dMVMT). The idea is to exploit multiple time-local views related to hand pose and movement to generate rich gesture descriptions, along with using heterogeneous tasks to achieve high accuracy. OO-dMVMT extends the classical MVMT paradigm, where all of the multiple tasks have to be active at each time, by allowing specific tasks to switch on/off depending on whether they can apply to the input. We show that OO-dMVMT defines the new SotA on continuous/online 3D skeleton-based gesture recognition in terms of gesture classification accuracy, segmentation accuracy, false positives, and decision latency while maintaining real-time operation.
Split-Et-Impera: A Framework for the Design of Distributed Deep Learning Applications
Mar 22, 2023Many recent pattern recognition applications rely on complex distributed architectures in which sensing and computational nodes interact together through a communication network. Deep neural networks (DNNs) play an important role in this scenario, furnishing powerful decision mechanisms, at the price of a high computational effort. Consequently, powerful state-of-the-art DNNs are frequently split over various computational nodes, e.g., a first part stays on an embedded device and the rest on a server. Deciding where to split a DNN is a challenge in itself, making the design of deep learning applications even more complicated. Therefore, we propose Split-Et-Impera, a novel and practical framework that i) determines the set of the best-split points of a neural network based on deep network interpretability principles without performing a tedious try-and-test approach, ii) performs a communication-aware simulation for the rapid evaluation of different neural network rearrangements, and iii) suggests the best match between the quality of service requirements of the application and the performance in terms of accuracy and latency time.