 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Task-Oriented Edge-Assisted Cross-System Design for Real-Time Human-Robot Interaction in Industrial Metaverse
Aug 28, 2025Real-time human-device interaction in industrial Metaverse faces challenges such as high computational load, limited bandwidth, and strict latency. This paper proposes a task-oriented edge-assisted cross-system framework using digital twins (DTs) to enable responsive interactions. By predicting operator motions, the system supports: 1) proactive Metaverse rendering for visual feedback, and 2) preemptive control of remote devices. The DTs are decoupled into two virtual functions-visual display and robotic control-optimizing both performance and adaptability. To enhance generalizability, we introduce the Human-In-The-Loop Model-Agnostic Meta-Learning (HITL-MAML) algorithm, which dynamically adjusts prediction horizons. Evaluation on two tasks demonstrates the framework's effectiveness: in a Trajectory-Based Drawing Control task, it reduces weighted RMSE from 0.0712 m to 0.0101 m; in a real-time 3D scene representation task for nuclear decommissioning, it achieves a PSNR of 22.11, SSIM of 0.8729, and LPIPS of 0.1298. These results show the framework's capability to ensure spatial precision and visual fidelity in real-time, high-risk industrial environments.
Preference-Driven Active 3D Scene Representation for Robotic Inspection in Nuclear Decommissioning
Apr 02, 2025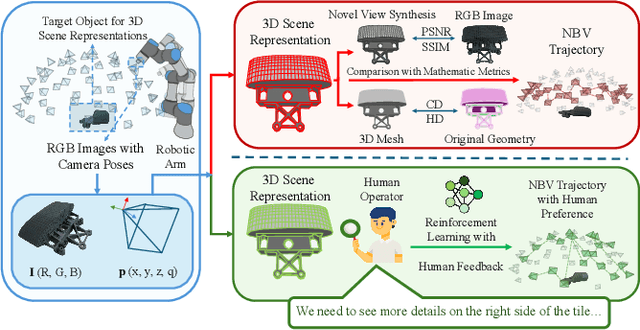
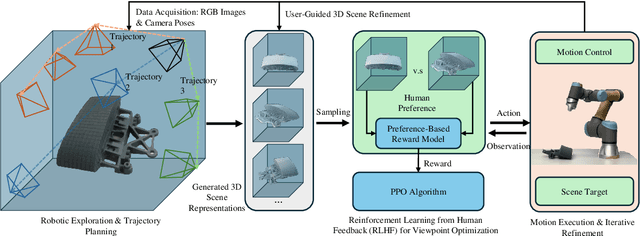
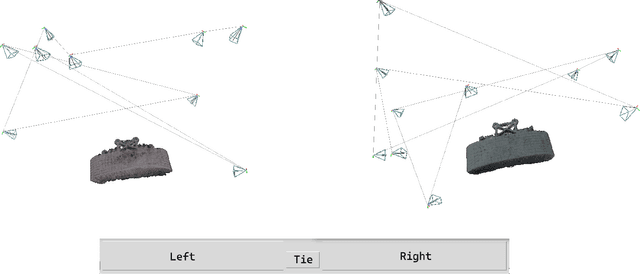
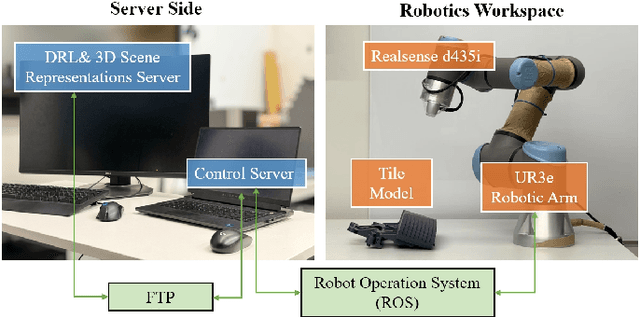
Active 3D scene representation is pivotal in modern robotics applications, including remote inspection, manipulation, and telepresence. Traditional methods primarily optimize geometric fidelity or rendering accuracy, but often overlook operator-specific objectives, such as safety-critical coverage or task-driven viewpoints. This limitation leads to suboptimal viewpoint selection, particularly in constrained environments such as nuclear decommissioning. To bridge this gap, we introduce a novel framework that integrates expert operator preferences into the active 3D scene representation pipeline. Specifically, we employ Reinforcement Learning from Human Feedback (RLHF) to guide robotic path planning, reshaping the reward function based on expert input. To capture operator-specific priorities, we conduct interactive choice experiments that evaluate user preferences in 3D scene representation. We validate our framework using a UR3e robotic arm for reactor tile inspection in a nuclear decommissioning scenario. Compared to baseline methods, our approach enhances scene representation while optimizing trajectory efficiency. The RLHF-based policy consistently outperforms random selection, prioritizing task-critical details. By unifying explicit 3D geometric modeling with implicit human-in-the-loop optimization, this work establishes a foundation for adaptive, safety-critical robotic perception systems, paving the way for enhanced automation in nuclear decommissioning, remote maintenance, and other high-risk environments.
Active Listener: Continuous Generation of Listener's Head Motion Response in Dyadic Interactions
Sep 30, 2024



A key component of dyadic spoken interactions is the contextually relevant non-verbal gestures, such as head movements that reflect a listener's response to the interlocutor's speech. Although significant progress has been made in the context of generating co-speech gestures, generating listener's response has remained a challenge. We introduce the task of generating continuous head motion response of a listener in response to the speaker's speech in real time. To this end, we propose a graph-based end-to-end crossmodal model that takes interlocutor's speech audio as input and directly generates head pose angles (roll, pitch, yaw) of the listener in real time. Different from previous work, our approach is completely data-driven, does not require manual annotations or oversimplify head motion to merely nods and shakes. Extensive evaluation on the dyadic interaction sessions on the IEMOCAP dataset shows that our model produces a low overall error (4.5 degrees) and a high frame rate, thereby indicating its deployability in real-world human-robot interaction systems. Our code is available at - https://github.com/bigzen/Active-Listener
Exploring 3D Human Pose Estimation and Forecasting from the Robot's Perspective: The HARPER Dataset
Mar 23, 2024



We introduce HARPER, a novel dataset for 3D body pose estimation and forecast in dyadic interactions between users and Spot, the quadruped robot manufactured by Boston Dynamics. The key-novelty is the focus on the robot's perspective, i.e., on the data captured by the robot's sensors. These make 3D body pose analysis challenging because being close to the ground captures humans only partially. The scenario underlying HARPER includes 15 actions, of which 10 involve physical contact between the robot and users. The Corpus contains not only the recordings of the built-in stereo cameras of Spot, but also those of a 6-camera OptiTrack system (all recordings are synchronized). This leads to ground-truth skeletal representations with a precision lower than a millimeter. In addition, the Corpus includes reproducible benchmarks on 3D Human Pose Estimation, Human Pose Forecasting, and Collision Prediction, all based on publicly available baseline approaches. This enables future HARPER users to rigorously compare their results with those we provide in this work.