 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring Operator Emotions from a Motion-Controlled Robotic Arm
Dec 09, 2025A remote robot operator's affective state can significantly impact the resulting robot's motions leading to unexpected consequences, even when the user follows protocol and performs permitted tasks. The recognition of a user operator's affective states in remote robot control scenarios is, however, underexplored. Current emotion recognition methods rely on reading the user's vital signs or body language, but the devices and user participation these measures require would add limitations to remote robot control. We demonstrate that the functional movements of a remote-controlled robotic avatar, which was not designed for emotional expression, can be used to infer the emotional state of the human operator via a machine-learning system. Specifically, our system achieved 83.3$\%$ accuracy in recognizing the user's emotional state expressed by robot movements, as a result of their hand motions. We discuss the implications of this system on prominent current and future remote robot operation and affective robotic contexts.
Task-Oriented Edge-Assisted Cross-System Design for Real-Time Human-Robot Interaction in Industrial Metaverse
Aug 28, 2025Real-time human-device interaction in industrial Metaverse faces challenges such as high computational load, limited bandwidth, and strict latency. This paper proposes a task-oriented edge-assisted cross-system framework using digital twins (DTs) to enable responsive interactions. By predicting operator motions, the system supports: 1) proactive Metaverse rendering for visual feedback, and 2) preemptive control of remote devices. The DTs are decoupled into two virtual functions-visual display and robotic control-optimizing both performance and adaptability. To enhance generalizability, we introduce the Human-In-The-Loop Model-Agnostic Meta-Learning (HITL-MAML) algorithm, which dynamically adjusts prediction horizons. Evaluation on two tasks demonstrates the framework's effectiveness: in a Trajectory-Based Drawing Control task, it reduces weighted RMSE from 0.0712 m to 0.0101 m; in a real-time 3D scene representation task for nuclear decommissioning, it achieves a PSNR of 22.11, SSIM of 0.8729, and LPIPS of 0.1298. These results show the framework's capability to ensure spatial precision and visual fidelity in real-time, high-risk industrial environments.
Preference-Driven Active 3D Scene Representation for Robotic Inspection in Nuclear Decommissioning
Apr 02, 2025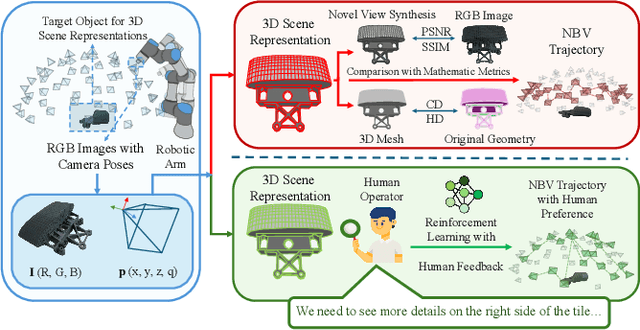
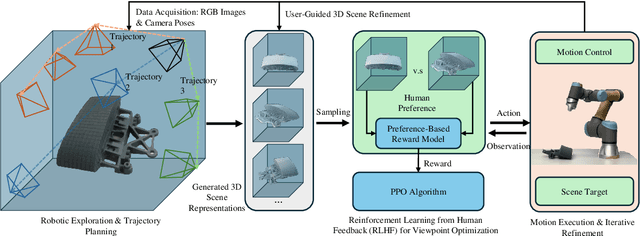
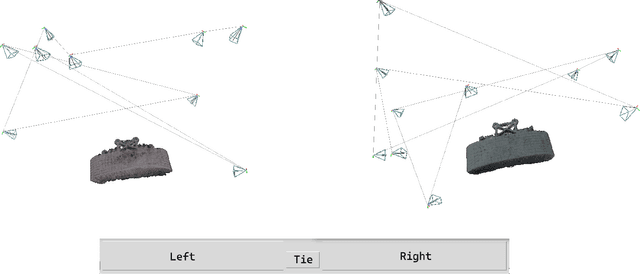
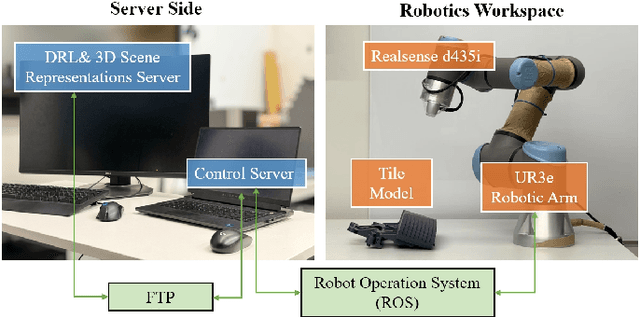
Active 3D scene representation is pivotal in modern robotics applications, including remote inspection, manipulation, and telepresence. Traditional methods primarily optimize geometric fidelity or rendering accuracy, but often overlook operator-specific objectives, such as safety-critical coverage or task-driven viewpoints. This limitation leads to suboptimal viewpoint selection, particularly in constrained environments such as nuclear decommissioning. To bridge this gap, we introduce a novel framework that integrates expert operator preferences into the active 3D scene representation pipeline. Specifically, we employ Reinforcement Learning from Human Feedback (RLHF) to guide robotic path planning, reshaping the reward function based on expert input. To capture operator-specific priorities, we conduct interactive choice experiments that evaluate user preferences in 3D scene representation. We validate our framework using a UR3e robotic arm for reactor tile inspection in a nuclear decommissioning scenario. Compared to baseline methods, our approach enhances scene representation while optimizing trajectory efficiency. The RLHF-based policy consistently outperforms random selection, prioritizing task-critical details. By unifying explicit 3D geometric modeling with implicit human-in-the-loop optimization, this work establishes a foundation for adaptive, safety-critical robotic perception systems, paving the way for enhanced automation in nuclear decommissioning, remote maintenance, and other high-risk environments.
Real-Time Interactions Between Human Controllers and Remote Devices in Metaverse
Jul 23, 2024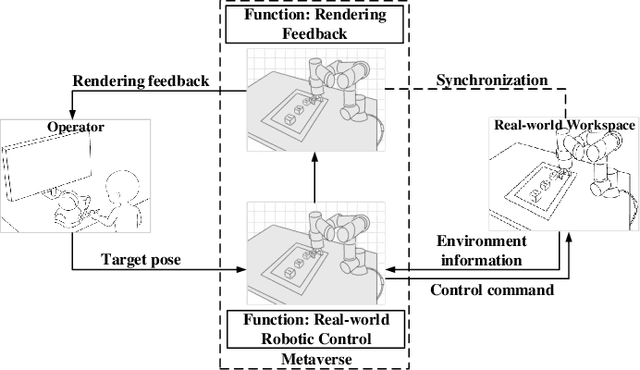
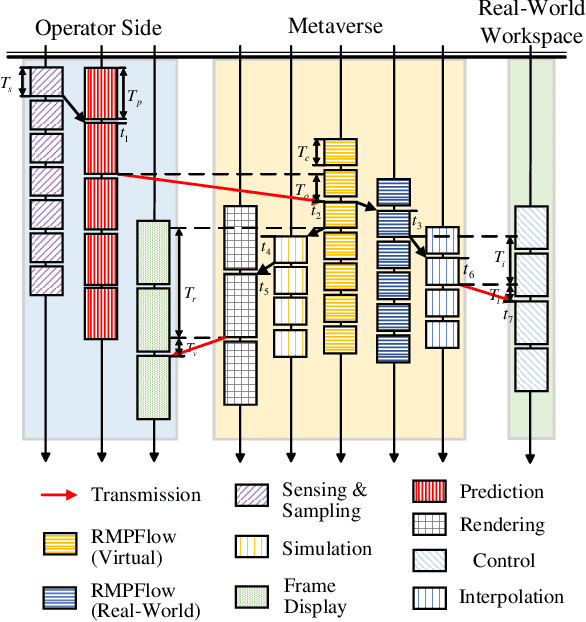
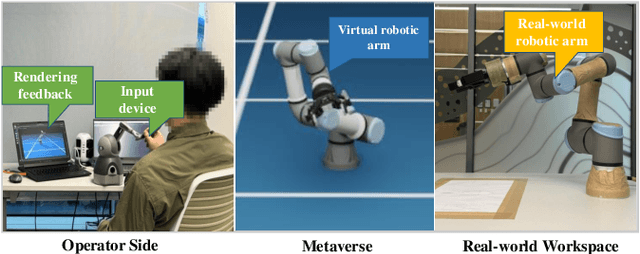
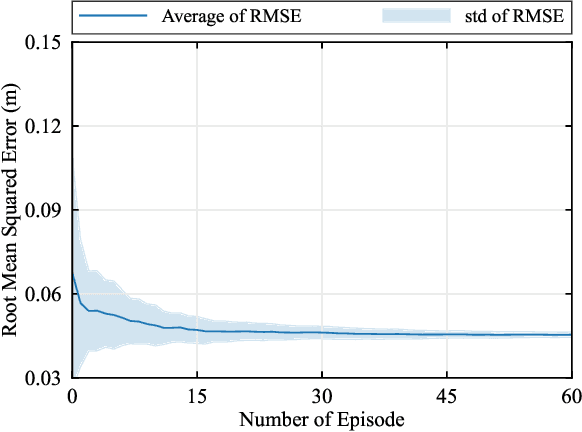
Supporting real-time interactions between human controllers and remote devices remains a challenging goal in the Metaverse due to the stringent requirements on computing workload, communication throughput, and round-trip latency. In this paper, we establish a novel framework for real-time interactions through the virtual models in the Metaverse. Specifically, we jointly predict the motion of the human controller for 1) proactive rendering in the Metaverse and 2) generating control commands to the real-world remote device in advance. The virtual model is decoupled into two components for rendering and control, respectively. To dynamically adjust the prediction horizons for rendering and control, we develop a two-step human-in-the-loop continuous reinforcement learning approach and use an expert policy to improve the training efficiency. An experimental prototype is built to verify our algorithm with different communication latencies. Compared with the baseline policy without prediction, our proposed method can reduce 1) the Motion-To-Photon (MTP) latency between human motion and rendering feedback and 2) the root mean squared error (RMSE) between human motion and real-world remote devices significantly.
Timeliness-Fidelity Tradeoff in 3D Scene Representations
Jul 23, 2024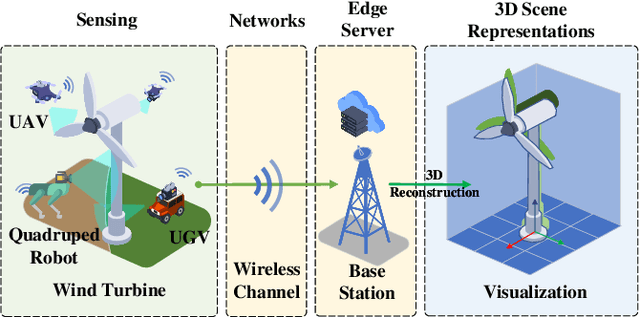
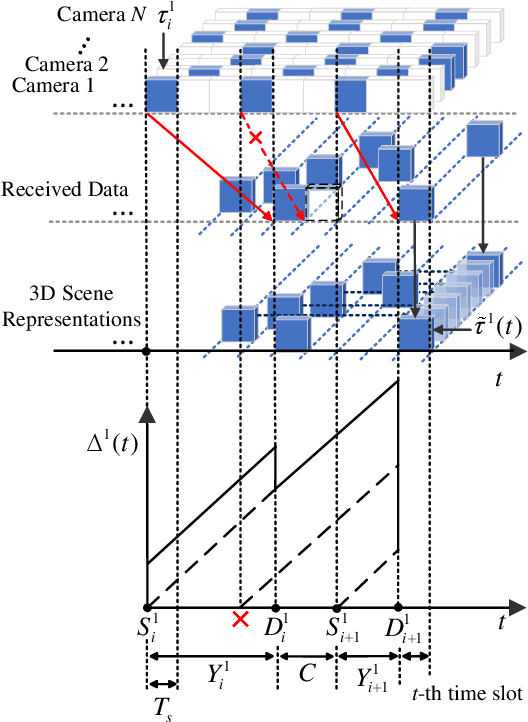
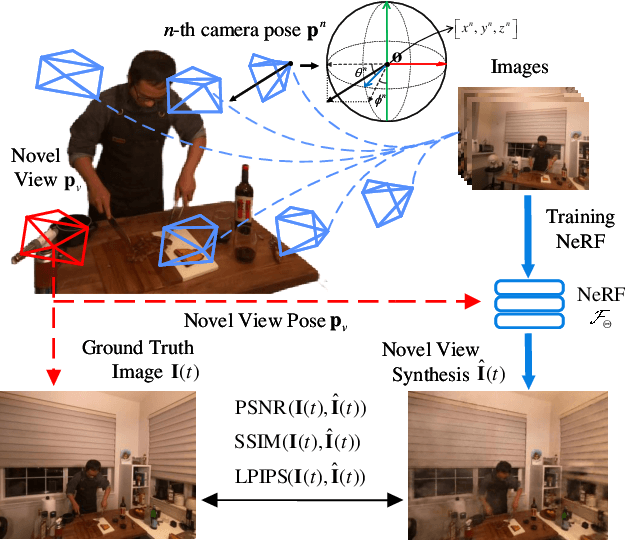
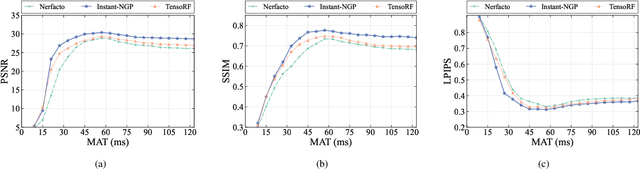
Real-time three-dimensional (3D) scene representations serve as one of the building blocks that bolster various innovative applications, e.g., digital manufacturing, Virtual/Augmented/Extended/Mixed Reality (VR/AR/XR/MR), and the metaverse. Despite substantial efforts that have been made to real-time communications and computing, real-time 3D scene representations remain a challenging task. This paper investigates the tradeoff between timeliness and fidelity in real-time 3D scene representations. Specifically, we establish a framework to evaluate the impact of communication delay on the tradeoff, where the real-world scenario is monitored by multiple cameras that communicate with an edge server. To improve fidelity for 3D scene representations, we propose to use a single-step Proximal Policy Optimization (PPO) method that leverages the Age of Information (AoI) to decide if the received image needs to be involved in 3D scene representations and rendering. We test our framework and the proposed approach with different well-known 3D scene representation methods. Simulation results reveal that real-time 3D scene representation can be sensitively affected by communication delay, and our proposed method can achieve optimal 3D scene representation results.