 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Oriented Edge-Assisted Cross-System Design for Real-Time Human-Robot Interaction in Industrial Metaverse
Aug 28, 2025Real-time human-device interaction in industrial Metaverse faces challenges such as high computational load, limited bandwidth, and strict latency. This paper proposes a task-oriented edge-assisted cross-system framework using digital twins (DTs) to enable responsive interactions. By predicting operator motions, the system supports: 1) proactive Metaverse rendering for visual feedback, and 2) preemptive control of remote devices. The DTs are decoupled into two virtual functions-visual display and robotic control-optimizing both performance and adaptability. To enhance generalizability, we introduce the Human-In-The-Loop Model-Agnostic Meta-Learning (HITL-MAML) algorithm, which dynamically adjusts prediction horizons. Evaluation on two tasks demonstrates the framework's effectiveness: in a Trajectory-Based Drawing Control task, it reduces weighted RMSE from 0.0712 m to 0.0101 m; in a real-time 3D scene representation task for nuclear decommissioning, it achieves a PSNR of 22.11, SSIM of 0.8729, and LPIPS of 0.1298. These results show the framework's capability to ensure spatial precision and visual fidelity in real-time, high-risk industrial environments.
Comprehend, Divide, and Conquer: Feature Subspace Exploration via Multi-Agent Hierarchical Reinforcement Learning
Apr 24, 2025



Feature selection aims to preprocess the target dataset, find an optimal and most streamlined feature subset, and enhance the downstream machine learning task. Among filter, wrapper, and embedded-based approaches, the reinforcement learning (RL)-based subspace exploration strategy provides a novel objective optimization-directed perspective and promising performance. Nevertheless, even with improved performance, current reinforcement learning approaches face challenges similar to conventional methods when dealing with complex datasets. These challenges stem from the inefficient paradigm of using one agent per feature and the inherent complexities present in the datasets. This observation motivates us to investigate and address the above issue and propose a novel approach, namely HRLFS. Our methodology initially employs a Large Language Model (LLM)-based hybrid state extractor to capture each feature's mathematical and semantic characteristics. Based on this information, features are clustered, facilitating the construction of hierarchical agents for each cluster and sub-cluster. Extensive experiments demonstrate the efficiency, scalability, and robustness of our approach. Compared to contemporary or the one-feature-one-agent RL-based approaches, HRLFS improves the downstream ML performance with iterative feature subspace exploration while accelerating total run time by reducing the number of agents involved.
Preference-Driven Active 3D Scene Representation for Robotic Inspection in Nuclear Decommissioning
Apr 02, 2025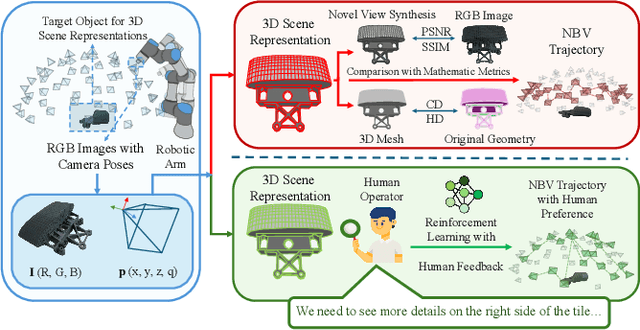
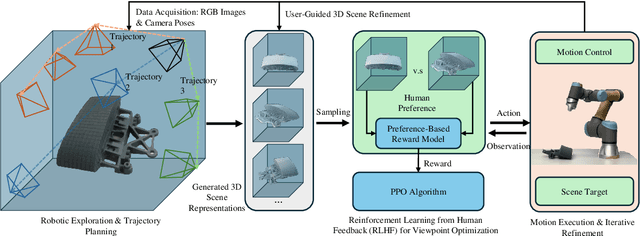
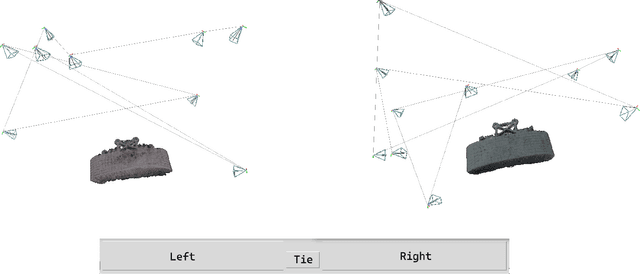
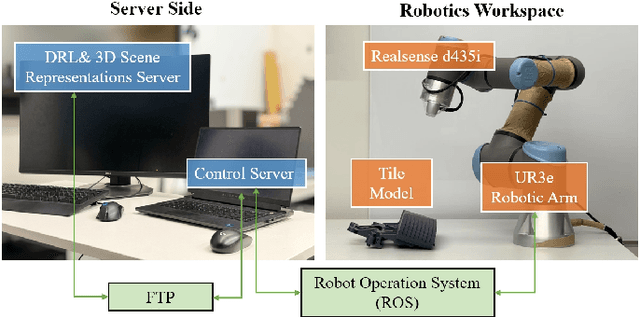
Active 3D scene representation is pivotal in modern robotics applications, including remote inspection, manipulation, and telepresence. Traditional methods primarily optimize geometric fidelity or rendering accuracy, but often overlook operator-specific objectives, such as safety-critical coverage or task-driven viewpoints. This limitation leads to suboptimal viewpoint selection, particularly in constrained environments such as nuclear decommissioning. To bridge this gap, we introduce a novel framework that integrates expert operator preferences into the active 3D scene representation pipeline. Specifically, we employ Reinforcement Learning from Human Feedback (RLHF) to guide robotic path planning, reshaping the reward function based on expert input. To capture operator-specific priorities, we conduct interactive choice experiments that evaluate user preferences in 3D scene representation. We validate our framework using a UR3e robotic arm for reactor tile inspection in a nuclear decommissioning scenario. Compared to baseline methods, our approach enhances scene representation while optimizing trajectory efficiency. The RLHF-based policy consistently outperforms random selection, prioritizing task-critical details. By unifying explicit 3D geometric modeling with implicit human-in-the-loop optimization, this work establishes a foundation for adaptive, safety-critical robotic perception systems, paving the way for enhanced automation in nuclear decommissioning, remote maintenance, and other high-risk environments.
Task-Oriented Edge-Assisted Cooperative Data Compression, Communications and Computing for UGV-Enhanced Warehouse Logistics
Oct 02, 2024



Only the chairs can edit This paper explores the growing need for task-oriented communications in warehouse logistics, where traditional communication Key Performance Indicators (KPIs)-such as latency, reliability, and throughput-often do not fully meet task requirements. As the complexity of data flow management in large-scale device networks increases, there is also a pressing need for innovative cross-system designs that balance data compression, communication, and computation. To address these challenges, we propose a task-oriented, edge-assisted framework for cooperative data compression, communication, and computing in Unmanned Ground Vehicle (UGV)-enhanced warehouse logistics. In this framework, two UGVs collaborate to transport cargo, with control functions-navigation for the front UGV and following/conveyance for the rear UGV-offloaded to the edge server to accommodate their limited on-board computing resources. We develop a Deep Reinforcement Learning (DRL)-based two-stage point cloud data compression algorithm that dynamically and collaboratively adjusts compression ratios according to task requirements, significantly reducing communication overhead. System-level simulations of our UGV logistics prototype demonstrate the framework's effectiveness and its potential for swift real-world implementation.
BioRAG: A RAG-LLM Framework for Biological Question Reasoning
Aug 02, 2024



The question-answering system for Life science research, which is characterized by the rapid pace of discovery, evolving insights, and complex interactions among knowledge entities, presents unique challenges in maintaining a comprehensive knowledge warehouse and accurate information retrieval. To address these issues, we introduce BioRAG, a novel Retrieval-Augmented Generation (RAG) with the Large Language Models (LLMs) framework. Our approach starts with parsing, indexing, and segmenting an extensive collection of 22 million scientific papers as the basic knowledge, followed by training a specialized embedding model tailored to this domain. Additionally, we enhance the vector retrieval process by incorporating a domain-specific knowledge hierarchy, which aids in modeling the intricate interrelationships among each query and context. For queries requiring the most current information, BioRAG deconstructs the question and employs an iterative retrieval process incorporated with the search engine for step-by-step reasoning. Rigorous experiments have demonstrated that our model outperforms fine-tuned LLM, LLM with search engines, and other scientific RAG frameworks across multiple life science question-answering tasks.
Timeliness-Fidelity Tradeoff in 3D Scene Representations
Jul 23, 2024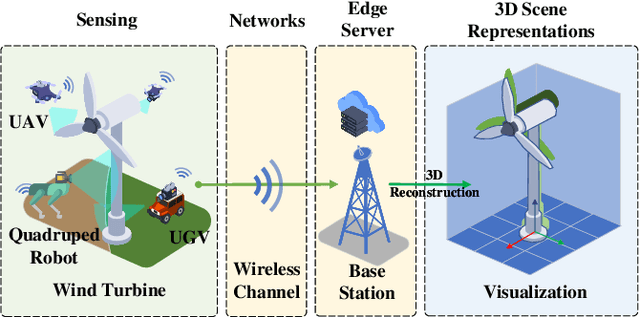
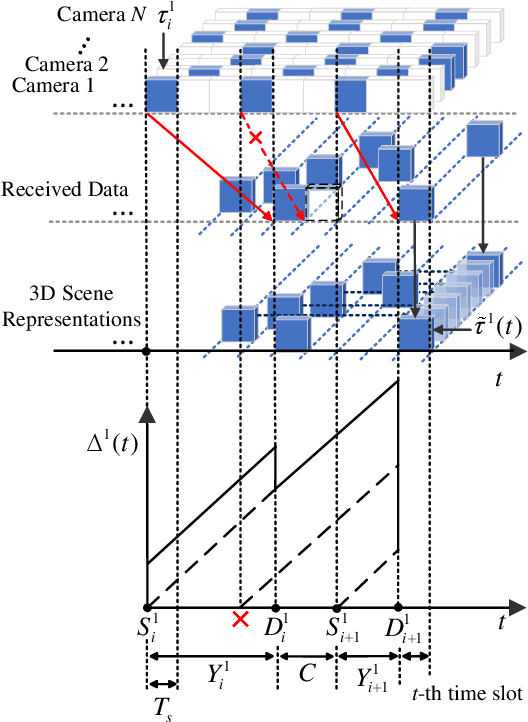
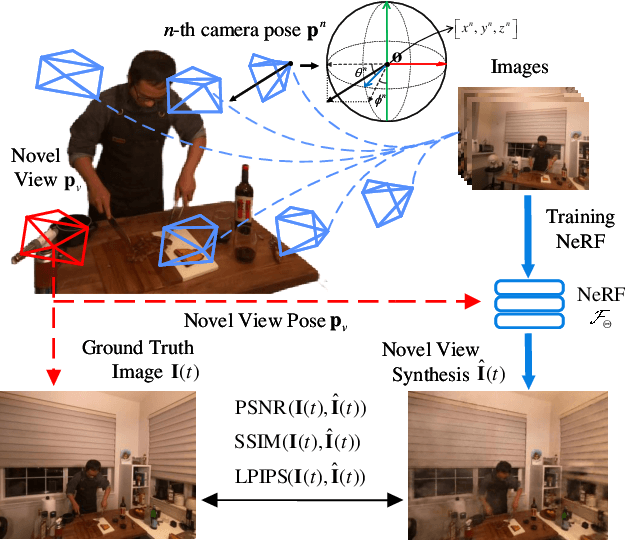
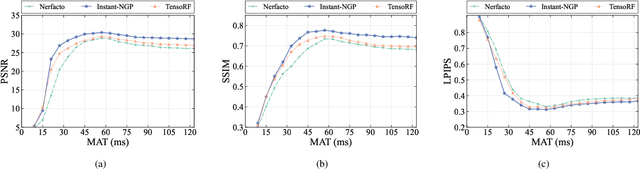
Real-time three-dimensional (3D) scene representations serve as one of the building blocks that bolster various innovative applications, e.g., digital manufacturing, Virtual/Augmented/Extended/Mixed Reality (VR/AR/XR/MR), and the metaverse. Despite substantial efforts that have been made to real-time communications and computing, real-time 3D scene representations remain a challenging task. This paper investigates the tradeoff between timeliness and fidelity in real-time 3D scene representations. Specifically, we establish a framework to evaluate the impact of communication delay on the tradeoff, where the real-world scenario is monitored by multiple cameras that communicate with an edge server. To improve fidelity for 3D scene representations, we propose to use a single-step Proximal Policy Optimization (PPO) method that leverages the Age of Information (AoI) to decide if the received image needs to be involved in 3D scene representations and rendering. We test our framework and the proposed approach with different well-known 3D scene representation methods. Simulation results reveal that real-time 3D scene representation can be sensitively affected by communication delay, and our proposed method can achieve optimal 3D scene representation results.
Real-Time Interactions Between Human Controllers and Remote Devices in Metaverse
Jul 23, 2024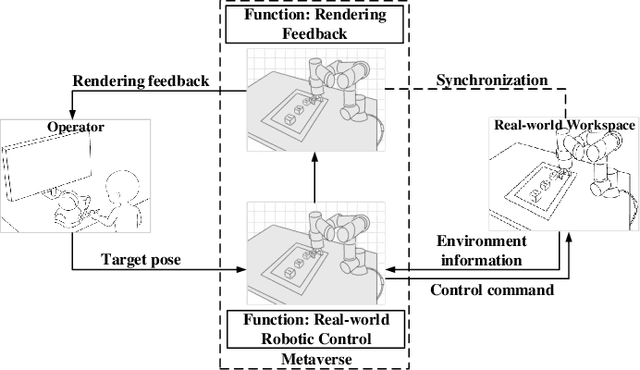
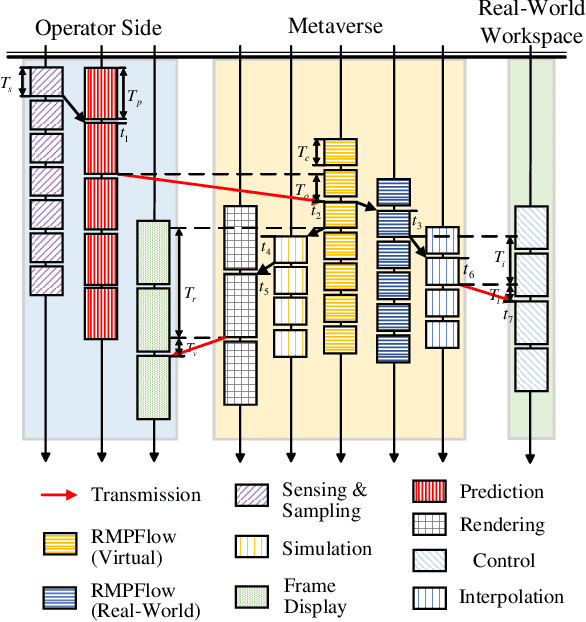
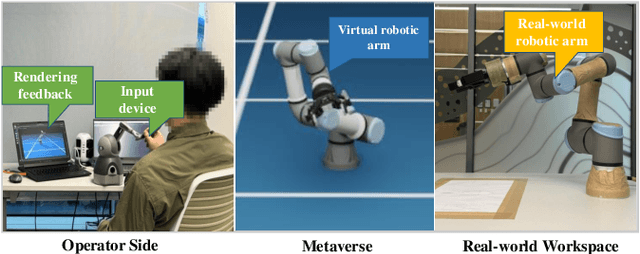
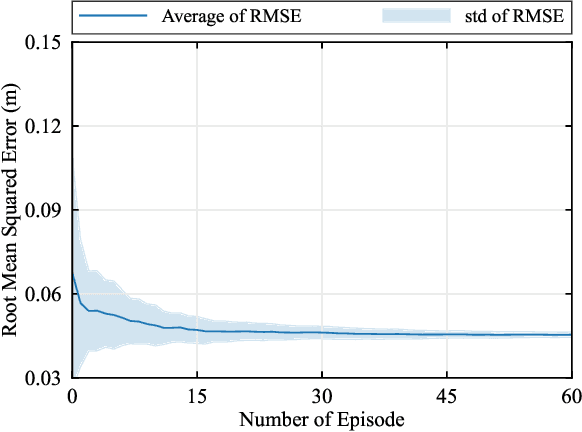
Supporting real-time interactions between human controllers and remote devices remains a challenging goal in the Metaverse due to the stringent requirements on computing workload, communication throughput, and round-trip latency. In this paper, we establish a novel framework for real-time interactions through the virtual models in the Metaverse. Specifically, we jointly predict the motion of the human controller for 1) proactive rendering in the Metaverse and 2) generating control commands to the real-world remote device in advance. The virtual model is decoupled into two components for rendering and control, respectively. To dynamically adjust the prediction horizons for rendering and control, we develop a two-step human-in-the-loop continuous reinforcement learning approach and use an expert policy to improve the training efficiency. An experimental prototype is built to verify our algorithm with different communication latencies. Compared with the baseline policy without prediction, our proposed method can reduce 1) the Motion-To-Photon (MTP) latency between human motion and rendering feedback and 2) the root mean squared error (RMSE) between human motion and real-world remote devices significantly.
GUME: Graphs and User Modalities Enhancement for Long-Tail Multimodal Recommendation
Jul 17, 2024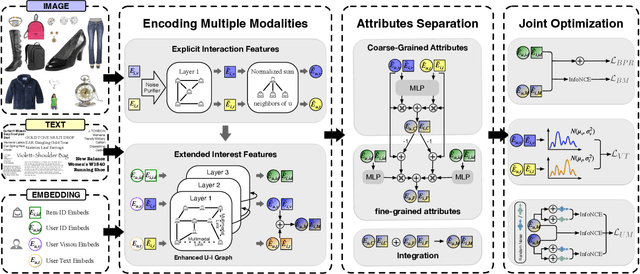
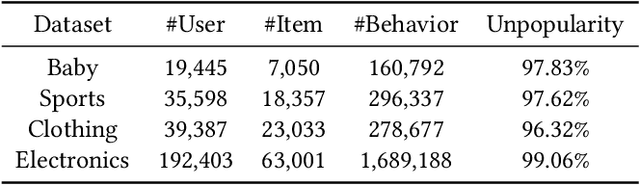
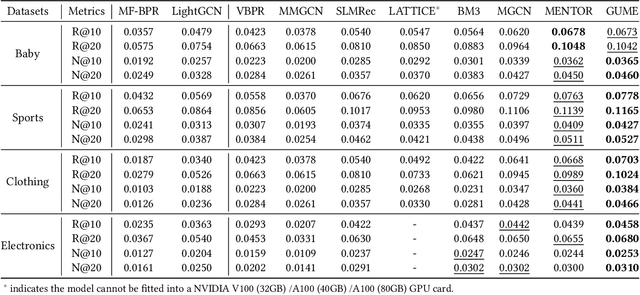
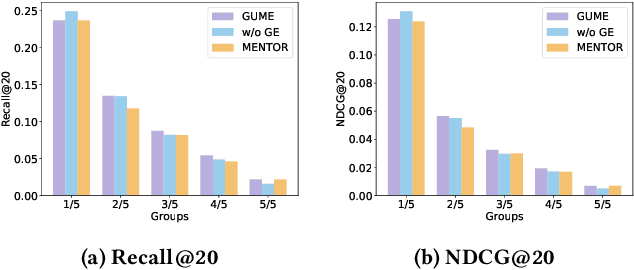
Multimodal recommendation systems (MMRS) have received considerable attention from the research community due to their ability to jointly utilize information from user behavior and product images and text. Previous research has two main issues. First, many long-tail items in recommendation systems have limited interaction data, making it difficult to learn comprehensive and informative representations. However, past MMRS studies have overlooked this issue. Secondly, users' modality preferences are crucial to their behavior. However, previous research has primarily focused on learning item modality representations, while user modality representations have remained relatively simplistic.To address these challenges, we propose a novel Graphs and User Modalities Enhancement (GUME) for long-tail multimodal recommendation. Specifically, we first enhance the user-item graph using multimodal similarity between items. This improves the connectivity of long-tail items and helps them learn high-quality representations through graph propagation. Then, we construct two types of user modalities: explicit interaction features and extended interest features. By using the user modality enhancement strategy to maximize mutual information between these two features, we improve the generalization ability of user modality representations. Additionally, we design an alignment strategy for modality data to remove noise from both internal and external perspectives. Extensive experiments on four publicly available datasets demonstrate the effectiveness of our approach.
Enhanced Gene Selection in Single-Cell Genomics: Pre-Filtering Synergy and Reinforced Optimization
Jun 11, 2024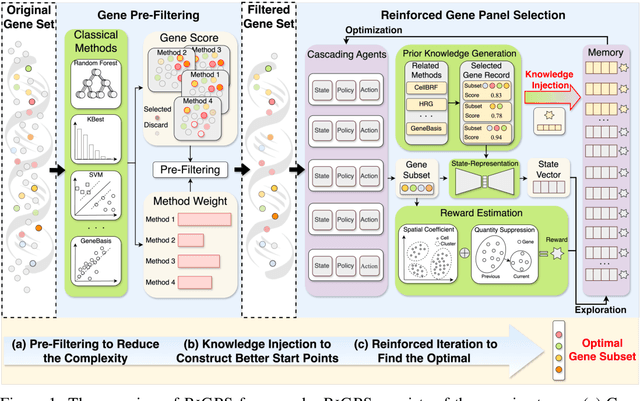
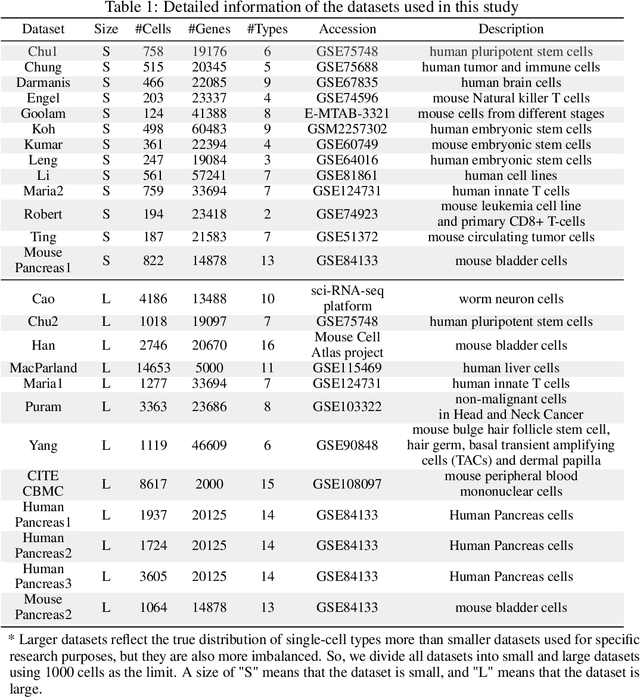
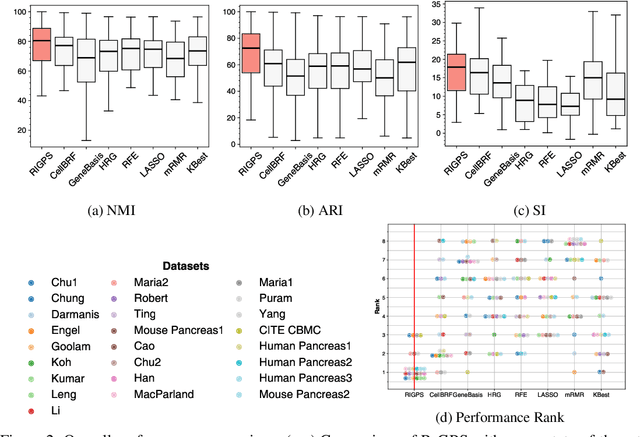
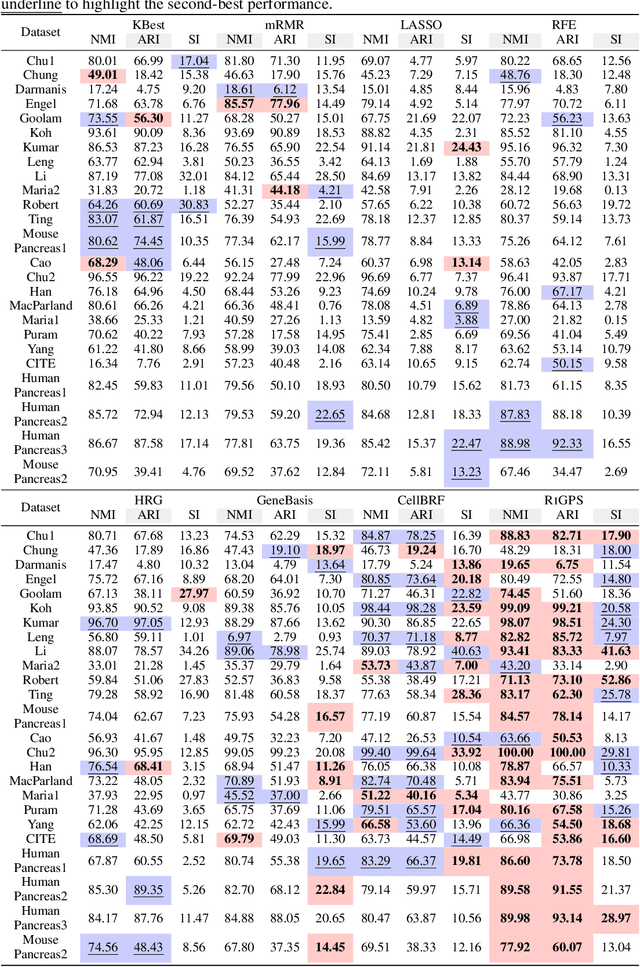
Recent advancements in single-cell genomics necessitate precision in gene panel selection to interpret complex biological data effectively. Those methods aim to streamline the analysis of scRNA-seq data by focusing on the most informative genes that contribute significantly to the specific analysis task. Traditional selection methods, which often rely on expert domain knowledge, embedded machine learning models, or heuristic-based iterative optimization, are prone to biases and inefficiencies that may obscure critical genomic signals. Recognizing the limitations of traditional methods, we aim to transcend these constraints with a refined strategy. In this study, we introduce an iterative gene panel selection strategy that is applicable to clustering tasks in single-cell genomics. Our method uniquely integrates results from other gene selection algorithms, providing valuable preliminary boundaries or prior knowledge as initial guides in the search space to enhance the efficiency of our framework. Furthermore, we incorporate the stochastic nature of the exploration process in reinforcement learning (RL) and its capability for continuous optimization through reward-based feedback. This combination mitigates the biases inherent in the initial boundaries and harnesses RL's adaptability to refine and target gene panel selection dynamically. To illustrate the effectiveness of our method, we conducted detailed comparative experiments, case studies, and visualization analysis.
COMAE: COMprehensive Attribute Exploration for Zero-shot Hashing
Feb 26, 2024



Zero-shot hashing (ZSH) has shown excellent success owing to its efficiency and generalization in large-scale retrieval scenarios. While considerable success has been achieved, there still exist urgent limitations. Existing works ignore the locality relationships of representations and attributes, which have effective transferability between seeable classes and unseeable classes. Also, the continuous-value attributes are not fully harnessed. In response, we conduct a COMprehensive Attribute Exploration for ZSH, named COMAE, which depicts the relationships from seen classes to unseen ones through three meticulously designed explorations, i.e., point-wise, pair-wise and class-wise consistency constraints. By regressing attributes from the proposed attribute prototype network, COMAE learns the local features that are relevant to the visual attributes. Then COMAE utilizes contrastive learning to comprehensively depict the context of attributes, rather than instance-independent optimization. Finally, the class-wise constraint is designed to cohesively learn the hash code, image representation, and visual attributes more effectively. Experimental results on the popular ZSH datasets demonstrate that COMAE outperforms state-of-the-art hashing techniques, especially in scenarios with a larger number of unseen label classes.