 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Interactions Between Human Controllers and Remote Devices in Metaverse
Paper and Code
Jul 23, 2024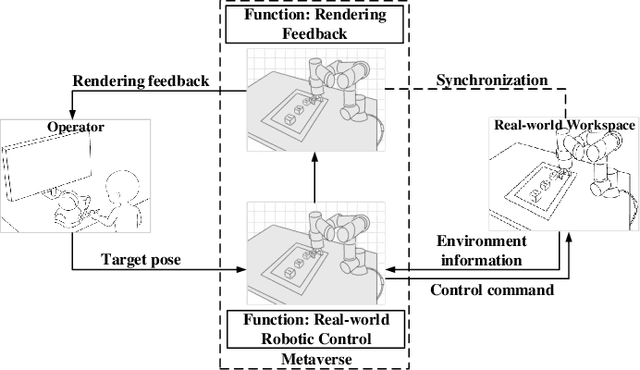
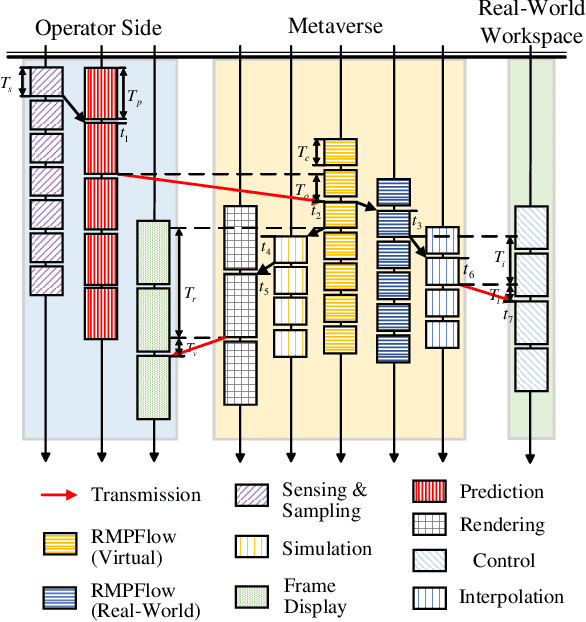
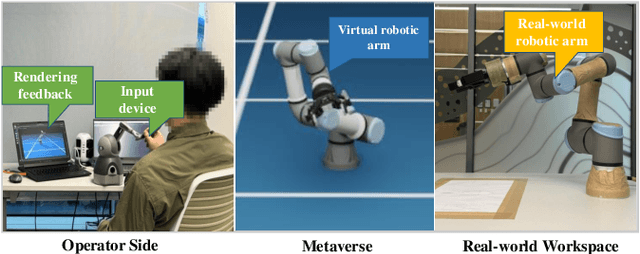
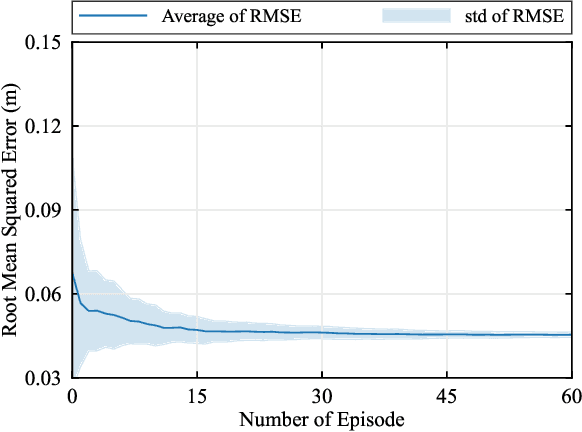
Supporting real-time interactions between human controllers and remote devices remains a challenging goal in the Metaverse due to the stringent requirements on computing workload, communication throughput, and round-trip latency. In this paper, we establish a novel framework for real-time interactions through the virtual models in the Metaverse. Specifically, we jointly predict the motion of the human controller for 1) proactive rendering in the Metaverse and 2) generating control commands to the real-world remote device in advance. The virtual model is decoupled into two components for rendering and control, respectively. To dynamically adjust the prediction horizons for rendering and control, we develop a two-step human-in-the-loop continuous reinforcement learning approach and use an expert policy to improve the training efficiency. An experimental prototype is built to verify our algorithm with different communication latencies. Compared with the baseline policy without prediction, our proposed method can reduce 1) the Motion-To-Photon (MTP) latency between human motion and rendering feedback and 2) the root mean squared error (RMSE) between human motion and real-world remote devices significantly.