 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERRY: Semantically Decoupled Evaluation of Multimodal Emotional and Role Consistencies of Role-Playing Agents
Feb 24, 2026Multimodal Role-Playing Agents (MRPAs) are attracting increasing attention due to their ability to deliver more immersive multimodal emotional interactions. However, existing studies still rely on pure textual benchmarks to evaluate the text responses of MRPAs, while delegating the assessment of their multimodal expressions solely to modality-synthesis metrics. This evaluation paradigm, on the one hand, entangles semantic assessment with modality generation, leading to ambiguous error attribution, and on the other hand remains constrained by the heavy reliance on human judgment. To this end, we propose MERRY, a semantically decoupled evaluation framework for assessing Multimodal Emotional and Role consistencies of Role-playing agents. This framework introduce five refined metrics for EC and three for RC. Notably, we transform the traditional subjective scoring approach into a novel bidirectional-evidence-finding task, significantly improving the human agreement of LLM-as-Judge evaluations. Based on MERRY, we conduct extensive evaluations. Our empirical results primarily reveal that: (1) Training on synthetic datasets tends to reduce emotional consistency, whereas training on real-world datasets improves it; (2) Existing models suffer from emotional templatization and simplification, exhibiting positive-bias and performance bottleneck in fine-grained negative emotions; (3) Simple prompting method strengthens the weak models but constrains the strong ones, while simple fine-tuning method suffers from poor role generalization. Codes and dataset are available.
Profit Mirage: Revisiting Information Leakage in LLM-based Financial Agents
Oct 09, 2025LLM-based financial agents have attracted widespread excitement for their ability to trade like human experts. However, most systems exhibit a "profit mirage": dazzling back-tested returns evaporate once the model's knowledge window ends, because of the inherent information leakage in LLMs. In this paper, we systematically quantify this leakage issue across four dimensions and release FinLake-Bench, a leakage-robust evaluation benchmark. Furthermore, to mitigate this issue, we introduce FactFin, a framework that applies counterfactual perturbations to compel LLM-based agents to learn causal drivers instead of memorized outcomes. FactFin integrates four core components: Strategy Code Generator, Retrieval-Augmented Generation, Monte Carlo Tree Search, and Counterfactual Simulator. Extensive experiments show that our method surpasses all baselines in out-of-sample generalization, delivering superior risk-adjusted performance.
QuantAgents: Towards Multi-agent Financial System via Simulated Trading
Oct 06, 2025In this paper, our objective is to develop a multi-agent financial system that incorporates simulated trading, a technique extensively utilized by financial professionals. While current LLM-based agent models demonstrate competitive performance, they still exhibit significant deviations from real-world fund companies. A critical distinction lies in the agents' reliance on ``post-reflection'', particularly in response to adverse outcomes, but lack a distinctly human capability: long-term prediction of future trends. Therefore, we introduce QuantAgents, a multi-agent system integrating simulated trading, to comprehensively evaluate various investment strategies and market scenarios without assuming actual risks. Specifically, QuantAgents comprises four agents: a simulated trading analyst, a risk control analyst, a market news analyst, and a manager, who collaborate through several meetings. Moreover, our system incentivizes agents to receive feedback on two fronts: performance in real-world markets and predictive accuracy in simulated trading. Extensive experiments demonstrate that our framework excels across all metrics, yielding an overall return of nearly 300% over the three years (https://quantagents.github.io/).
Task-Oriented Edge-Assisted Cross-System Design for Real-Time Human-Robot Interaction in Industrial Metaverse
Aug 28, 2025Real-time human-device interaction in industrial Metaverse faces challenges such as high computational load, limited bandwidth, and strict latency. This paper proposes a task-oriented edge-assisted cross-system framework using digital twins (DTs) to enable responsive interactions. By predicting operator motions, the system supports: 1) proactive Metaverse rendering for visual feedback, and 2) preemptive control of remote devices. The DTs are decoupled into two virtual functions-visual display and robotic control-optimizing both performance and adaptability. To enhance generalizability, we introduce the Human-In-The-Loop Model-Agnostic Meta-Learning (HITL-MAML) algorithm, which dynamically adjusts prediction horizons. Evaluation on two tasks demonstrates the framework's effectiveness: in a Trajectory-Based Drawing Control task, it reduces weighted RMSE from 0.0712 m to 0.0101 m; in a real-time 3D scene representation task for nuclear decommissioning, it achieves a PSNR of 22.11, SSIM of 0.8729, and LPIPS of 0.1298. These results show the framework's capability to ensure spatial precision and visual fidelity in real-time, high-risk industrial environments.
Long-Context Speech Synthesis with Context-Aware Memory
Aug 20, 2025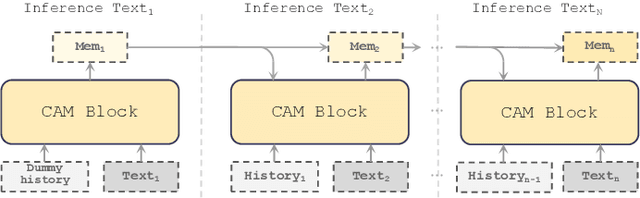
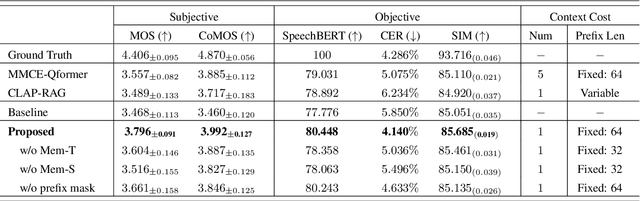
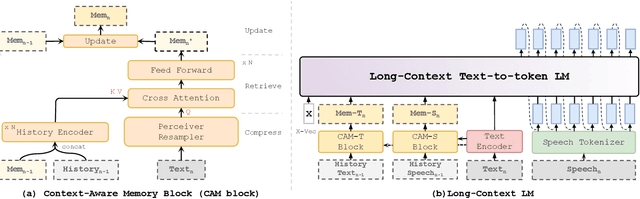
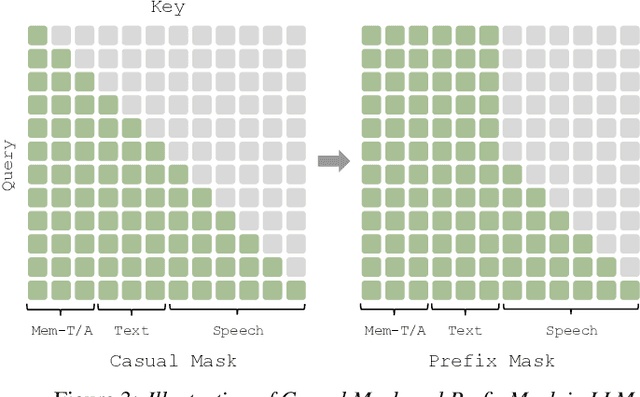
In long-text speech synthesis, current approaches typically convert text to speech at the sentence-level and concatenate the results to form pseudo-paragraph-level speech. These methods overlook the contextual coherence of paragraphs, leading to reduced naturalness and inconsistencies in style and timbre across the long-form speech. To address these issues, we propose a Context-Aware Memory (CAM)-based long-context Text-to-Speech (TTS) model. The CAM block integrates and retrieves both long-term memory and local context details, enabling dynamic memory updates and transfers within long paragraphs to guide sentence-level speech synthesis. Furthermore, the prefix mask enhances the in-context learning ability by enabling bidirectional attention on prefix tokens while maintaining unidirectional generation. Experimental results demonstrate that the proposed method outperforms baseline and state-of-the-art long-context methods in terms of prosody expressiveness, coherence and context inference cost across paragraph-level speech.
Parallel GPT: Harmonizing the Independence and Interdependence of Acoustic and Semantic Information for Zero-Shot Text-to-Speech
Aug 06, 2025Advances in speech representation and large language models have enhanced zero-shot text-to-speech (TTS) performance. However, existing zero-shot TTS models face challenges in capturing the complex correlations between acoustic and semantic features, resulting in a lack of expressiveness and similarity. The primary reason lies in the complex relationship between semantic and acoustic features, which manifests independent and interdependent aspects.This paper introduces a TTS framework that combines both autoregressive (AR) and non-autoregressive (NAR) modules to harmonize the independence and interdependence of acoustic and semantic information. The AR model leverages the proposed Parallel Tokenizer to synthesize the top semantic and acoustic tokens simultaneously. In contrast, considering the interdependence, the Coupled NAR model predicts detailed tokens based on the general AR model's output. Parallel GPT, built on this architecture, is designed to improve zero-shot text-to-speech synthesis through its parallel structure. Experiments on English and Chinese datasets demonstrate that the proposed model significantly outperforms the quality and efficiency of the synthesis of existing zero-shot TTS models. Speech demos are available at https://t1235-ch.github.io/pgpt/.
Bilateral Collaboration with Large Vision-Language Models for Open Vocabulary Human-Object Interaction Detection
Jul 09, 2025Open vocabulary Human-Object Interaction (HOI) detection is a challenging task that detects all <human, verb, object> triplets of interest in an image, even those that are not pre-defined in the training set. Existing approaches typically rely on output features generated by large Vision-Language Models (VLMs) to enhance the generalization ability of interaction representations. However, the visual features produced by VLMs are holistic and coarse-grained, which contradicts the nature of detection tasks. To address this issue, we propose a novel Bilateral Collaboration framework for open vocabulary HOI detection (BC-HOI). This framework includes an Attention Bias Guidance (ABG) component, which guides the VLM to produce fine-grained instance-level interaction features according to the attention bias provided by the HOI detector. It also includes a Large Language Model (LLM)-based Supervision Guidance (LSG) component, which provides fine-grained token-level supervision for the HOI detector by the LLM component of the VLM. LSG enhances the ability of ABG to generate high-quality attention bias. We conduct extensive experiments on two popular benchmarks: HICO-DET and V-COCO, consistently achieving superior performance in the open vocabulary and closed settings. The code will be released in Github.
AhaKV: Adaptive Holistic Attention-Driven KV Cache Eviction for Efficient Inference of Large Language Models
Jun 04, 2025


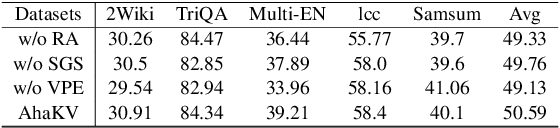
Large Language Models (LLMs) have significantly advanced the field of Artificial Intelligence. However, their deployment is resource-intensive, not only due to the large number of model parameters but also because the (Key-Value) KV cache consumes a lot of memory during inference. While several works propose reducing the KV cache by evicting the unnecessary tokens, these approaches rely on accumulated attention score as eviction score to quantify the importance of the token. We identify the accumulated attention score is biased and it decreases with the position of the tokens in the mathematical expectation. As a result, the retained tokens concentrate on the initial positions, limiting model's access to global contextual information. To address this issue, we propose Adaptive holistic attention KV (AhaKV), it addresses the bias of the accumulated attention score by adaptively tuning the scale of softmax according the expectation of information entropy of attention scores. To make use of the holistic attention information in self-attention mechanism, AhaKV utilize the information of value vectors, which is overlooked in previous works, to refine the adaptive score. We show theoretically that our method is well suited for bias reduction. We deployed AhaKV on different models with a fixed cache budget. Experiments show that AhaKV successfully mitigates bias and retains crucial tokens across global context and achieve state-of-the-art results against other related work on several benchmark tasks.
S2SBench: A Benchmark for Quantifying Intelligence Degradation in Speech-to-Speech Large Language Models
May 20, 2025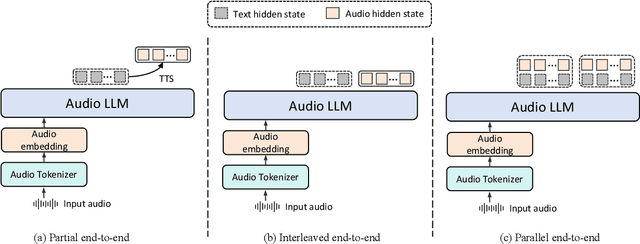
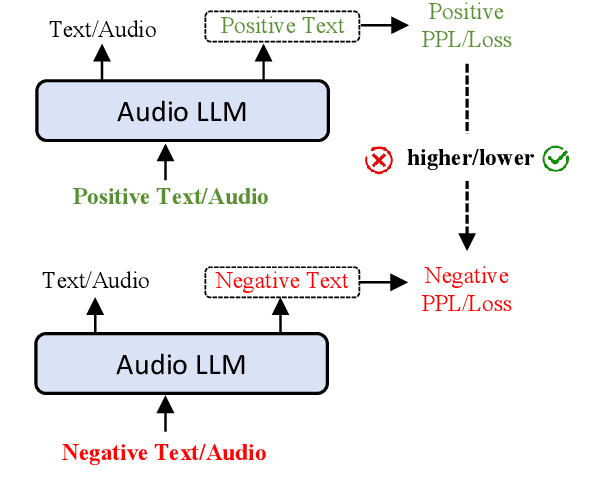
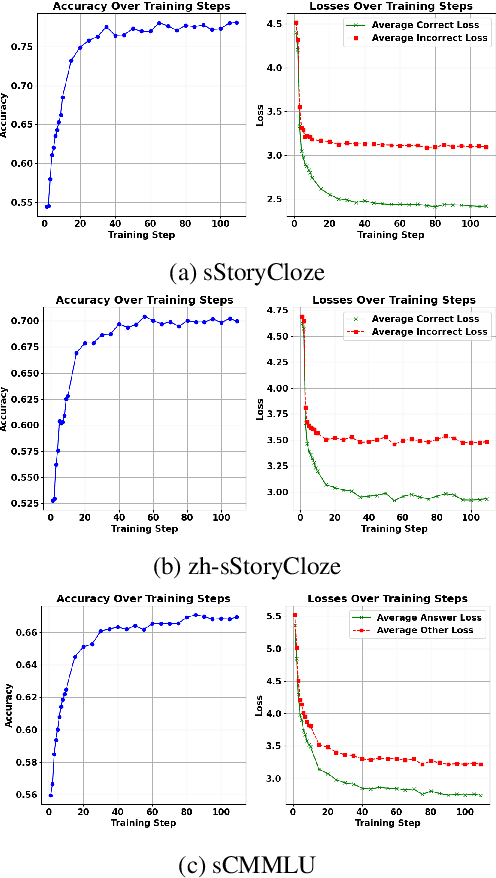
End-to-end speech large language models ((LLMs)) extend the capabilities of text-based models to directly process and generate audio tokens. However, this often leads to a decline in reasoning and generation performance compared to text input, a phenomenon referred to as intelligence degradation. To systematically evaluate this gap, we propose S2SBench, a benchmark designed to quantify performance degradation in Speech LLMs. It includes diagnostic datasets targeting sentence continuation and commonsense reasoning under audio input. We further introduce a pairwise evaluation protocol based on perplexity differences between plausible and implausible samples to measure degradation relative to text input. We apply S2SBench to analyze the training process of Baichuan-Audio, which further demonstrates the benchmark's effectiveness. All datasets and evaluation code are available at https://github.com/undobug/S2SBench.
Preference-Driven Active 3D Scene Representation for Robotic Inspection in Nuclear Decommissioning
Apr 02, 2025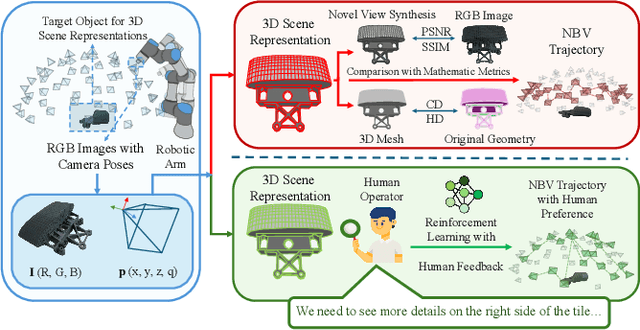
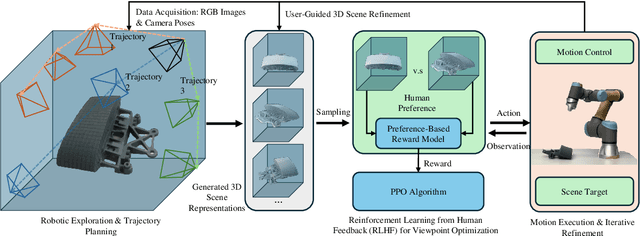
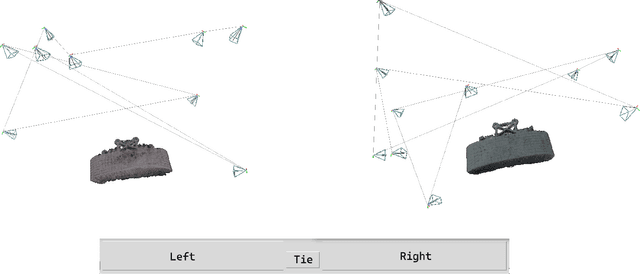
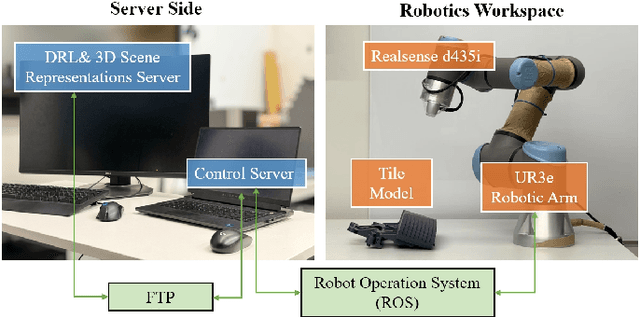
Active 3D scene representation is pivotal in modern robotics applications, including remote inspection, manipulation, and telepresence. Traditional methods primarily optimize geometric fidelity or rendering accuracy, but often overlook operator-specific objectives, such as safety-critical coverage or task-driven viewpoints. This limitation leads to suboptimal viewpoint selection, particularly in constrained environments such as nuclear decommissioning. To bridge this gap, we introduce a novel framework that integrates expert operator preferences into the active 3D scene representation pipeline. Specifically, we employ Reinforcement Learning from Human Feedback (RLHF) to guide robotic path planning, reshaping the reward function based on expert input. To capture operator-specific priorities, we conduct interactive choice experiments that evaluate user preferences in 3D scene representation. We validate our framework using a UR3e robotic arm for reactor tile inspection in a nuclear decommissioning scenario. Compared to baseline methods, our approach enhances scene representation while optimizing trajectory efficiency. The RLHF-based policy consistently outperforms random selection, prioritizing task-critical details. By unifying explicit 3D geometric modeling with implicit human-in-the-loop optimization, this work establishes a foundation for adaptive, safety-critical robotic perception systems, paving the way for enhanced automation in nuclear decommissioning, remote maintenance, and other high-risk environments.