 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Thousands of Human Annotators for Generalizable Text-to-Image Person Re-identification
Mar 13, 2025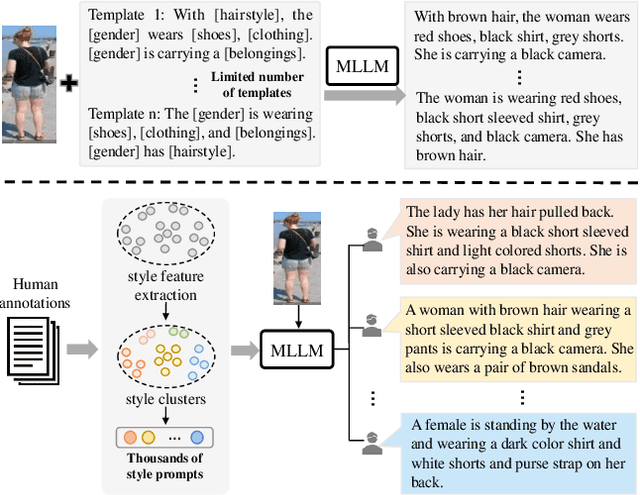
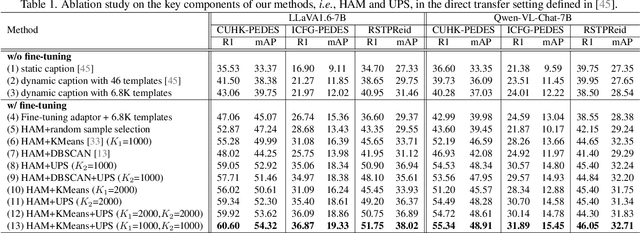
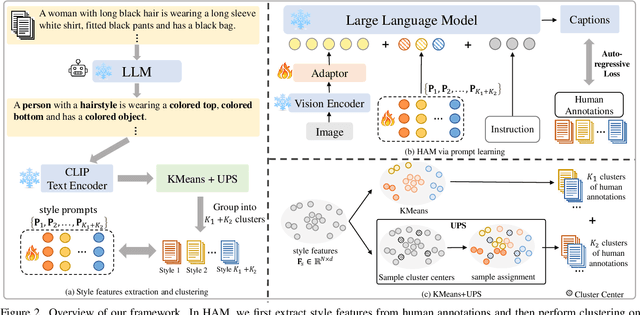
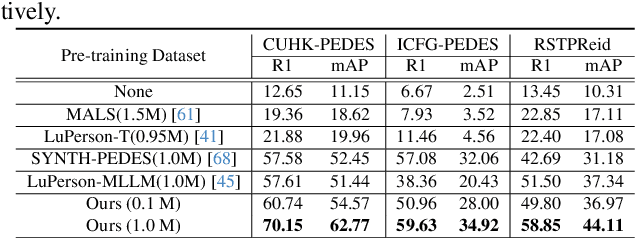
Text-to-image person re-identification (ReID) aims to retrieve the images of an interested person based on textual descriptions. One main challenge for this task is the high cost in manually annotating large-scale databases, which affects the generalization ability of ReID models. Recent works handle this problem by leveraging Multi-modal Large Language Models (MLLMs) to describe pedestrian images automatically. However, the captions produced by MLLMs lack diversity in description styles. To address this issue, we propose a Human Annotator Modeling (HAM) approach to enable MLLMs to mimic the description styles of thousands of human annotators. Specifically, we first extract style features from human textual descriptions and perform clustering on them. This allows us to group textual descriptions with similar styles into the same cluster. Then, we employ a prompt to represent each of these clusters and apply prompt learning to mimic the description styles of different human annotators. Furthermore, we define a style feature space and perform uniform sampling in this space to obtain more diverse clustering prototypes, which further enriches the diversity of the MLLM-generated captions. Finally, we adopt HAM to automatically annotate a massive-scale database for text-to-image ReID. Extensive experiments on this database demonstrate that it significantly improves the generalization ability of ReID models.
Harnessing the Power of MLLMs for Transferable Text-to-Image Person ReID
May 08, 2024



Text-to-image person re-identification (ReID) retrieves pedestrian images according to textual descriptions. Manually annotating textual descriptions is time-consuming, restricting the scale of existing datasets and therefore the generalization ability of ReID models. As a result, we study the transferable text-to-image ReID problem, where we train a model on our proposed large-scale database and directly deploy it to various datasets for evaluation. We obtain substantial training data via Multi-modal Large Language Models (MLLMs). Moreover, we identify and address two key challenges in utilizing the obtained textual descriptions. First, an MLLM tends to generate descriptions with similar structures, causing the model to overfit specific sentence patterns. Thus, we propose a novel method that uses MLLMs to caption images according to various templates. These templates are obtained using a multi-turn dialogue with a Large Language Model (LLM). Therefore, we can build a large-scale dataset with diverse textual descriptions. Second, an MLLM may produce incorrect descriptions. Hence, we introduce a novel method that automatically identifies words in a description that do not correspond with the image. This method is based on the similarity between one text and all patch token embeddings in the image. Then, we mask these words with a larger probability in the subsequent training epoch, alleviating the impact of noisy textual descriptions. The experimental results demonstrate that our methods significantly boost the direct transfer text-to-image ReID performance. Benefiting from the pre-trained model weights, we also achieve state-of-the-art performance in the traditional evaluation settings.