 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObservability Analysis and Composite Disturbance Filtering for a Bar Tethered to Dual UAVs Subject to Multi-source Disturbances
Dec 10, 2025Cooperative suspended aerial transportation is highly susceptible to multi-source disturbances such as aerodynamic effects and thrust uncertainties. To achieve precise load manipulation, existing methods often rely on extra sensors to measure cable directions or the payload's pose, which increases the system cost and complexity. A fundamental question remains: is the payload's pose observable under multi-source disturbances using only the drones' odometry information? To answer this question, this work focuses on the two-drone-bar system and proves that the whole system is observable when only two or fewer types of lumped disturbances exist by using the observability rank criterion. To the best of our knowledge, we are the first to present such a conclusion and this result paves the way for more cost-effective and robust systems by minimizing their sensor suites. Next, to validate this analysis, we consider the situation where the disturbances are only exerted on the drones, and develop a composite disturbance filtering scheme. A disturbance observer-based error-state extended Kalman filter is designed for both state and disturbance estimation, which renders improved estimation performance for the whole system evolving on the manifold $(\mathbb{R}^3)^2\times(TS^2)^3$. Our simulation and experimental tests have validated that it is possible to fully estimate the state and disturbance of the system with only odometry information of the drones.
Modeling Thousands of Human Annotators for Generalizable Text-to-Image Person Re-identification
Mar 13, 2025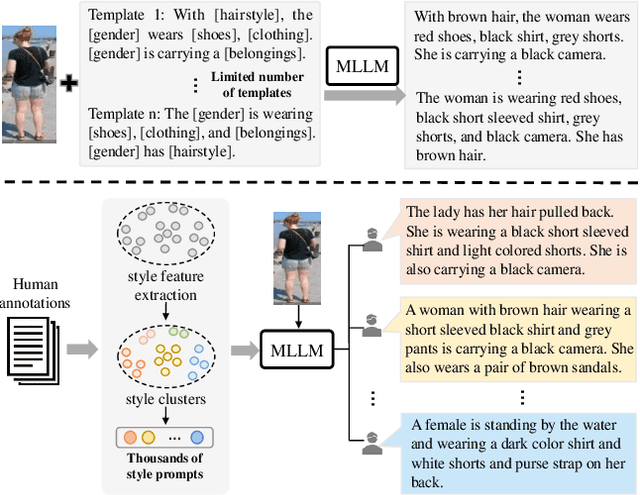
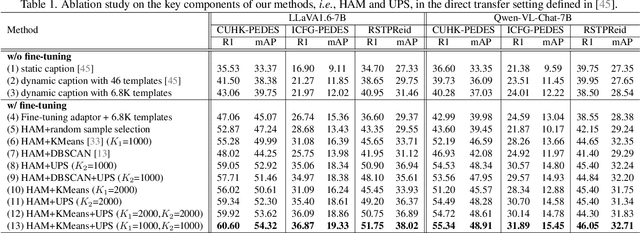
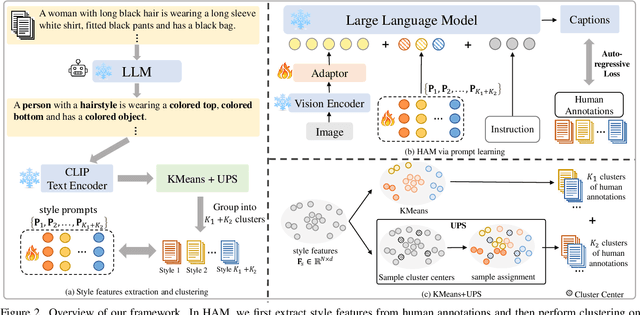
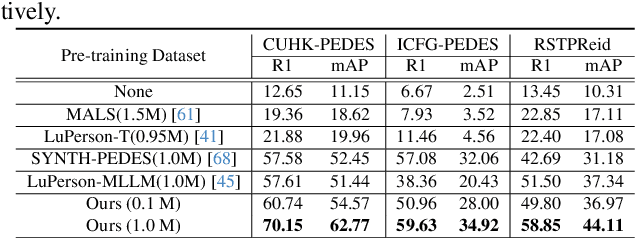
Text-to-image person re-identification (ReID) aims to retrieve the images of an interested person based on textual descriptions. One main challenge for this task is the high cost in manually annotating large-scale databases, which affects the generalization ability of ReID models. Recent works handle this problem by leveraging Multi-modal Large Language Models (MLLMs) to describe pedestrian images automatically. However, the captions produced by MLLMs lack diversity in description styles. To address this issue, we propose a Human Annotator Modeling (HAM) approach to enable MLLMs to mimic the description styles of thousands of human annotators. Specifically, we first extract style features from human textual descriptions and perform clustering on them. This allows us to group textual descriptions with similar styles into the same cluster. Then, we employ a prompt to represent each of these clusters and apply prompt learning to mimic the description styles of different human annotators. Furthermore, we define a style feature space and perform uniform sampling in this space to obtain more diverse clustering prototypes, which further enriches the diversity of the MLLM-generated captions. Finally, we adopt HAM to automatically annotate a massive-scale database for text-to-image ReID. Extensive experiments on this database demonstrate that it significantly improves the generalization ability of ReID models.
Towards Human-Level 3D Relative Pose Estimation: Generalizable, Training-Free, with Single Reference
Jun 26, 2024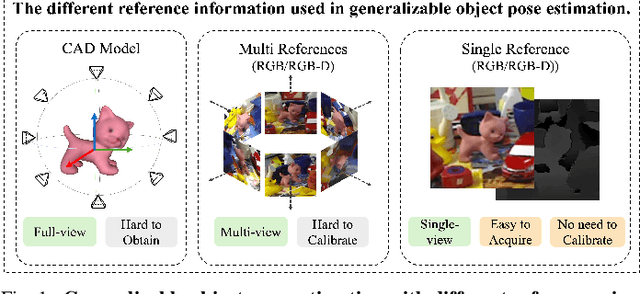
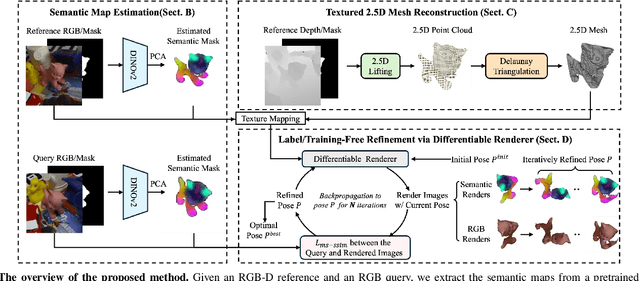

Humans can easily deduce the relative pose of an unseen object, without label/training, given only a single query-reference image pair. This is arguably achieved by incorporating (i) 3D/2.5D shape perception from a single image, (ii) render-and-compare simulation, and (iii) rich semantic cue awareness to furnish (coarse) reference-query correspondence. Existing methods implement (i) by a 3D CAD model or well-calibrated multiple images and (ii) by training a network on specific objects, which necessitate laborious ground-truth labeling and tedious training, potentially leading to challenges in generalization. Moreover, (iii) was less exploited in the paradigm of (ii), despite that the coarse correspondence from (iii) enhances the compare process by filtering out non-overlapped parts under substantial pose differences/occlusions. Motivated by this, we propose a novel 3D generalizable relative pose estimation method by elaborating (i) with a 2.5D shape from an RGB-D reference, (ii) with an off-the-shelf differentiable renderer, and (iii) with semantic cues from a pretrained model like DINOv2. Specifically, our differentiable renderer takes the 2.5D rotatable mesh textured by the RGB and the semantic maps (obtained by DINOv2 from the RGB input), then renders new RGB and semantic maps (with back-surface culling) under a novel rotated view. The refinement loss comes from comparing the rendered RGB and semantic maps with the query ones, back-propagating the gradients through the differentiable renderer to refine the 3D relative pose. As a result, our method can be readily applied to unseen objects, given only a single RGB-D reference, without label/training. Extensive experiments on LineMOD, LM-O, and YCB-V show that our training-free method significantly outperforms the SOTA supervised methods, especially under the rigorous Acc@5/10/15{\deg} metrics and the challenging cross-dataset settings.
BianQue: Balancing the Questioning and Suggestion Ability of Health LLMs with Multi-turn Health Conversations Polished by ChatGPT
Oct 24, 2023Large language models (LLMs) have performed well in providing general and extensive health suggestions in single-turn conversations, exemplified by systems such as ChatGPT, ChatGLM, ChatDoctor, DoctorGLM, and etc. However, the limited information provided by users during single turn results in inadequate personalization and targeting of the generated suggestions, which requires users to independently select the useful part. It is mainly caused by the missing ability to engage in multi-turn questioning. In real-world medical consultations, doctors usually employ a series of iterative inquiries to comprehend the patient's condition thoroughly, enabling them to provide effective and personalized suggestions subsequently, which can be defined as chain of questioning (CoQ) for LLMs. To improve the CoQ of LLMs, we propose BianQue, a ChatGLM-based LLM finetuned with the self-constructed health conversation dataset BianQueCorpus that is consist of multiple turns of questioning and health suggestions polished by ChatGPT. Experimental results demonstrate that the proposed BianQue can simultaneously balance the capabilities of both questioning and health suggestions, which will help promote the research and application of LLMs in the field of proactive health.
An Ensemble Classification Algorithm Based on Information Entropy for Data Streams
Aug 11, 2017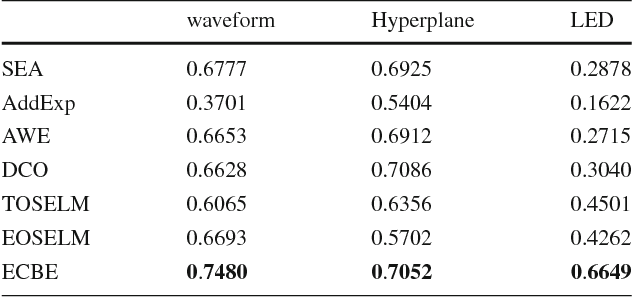
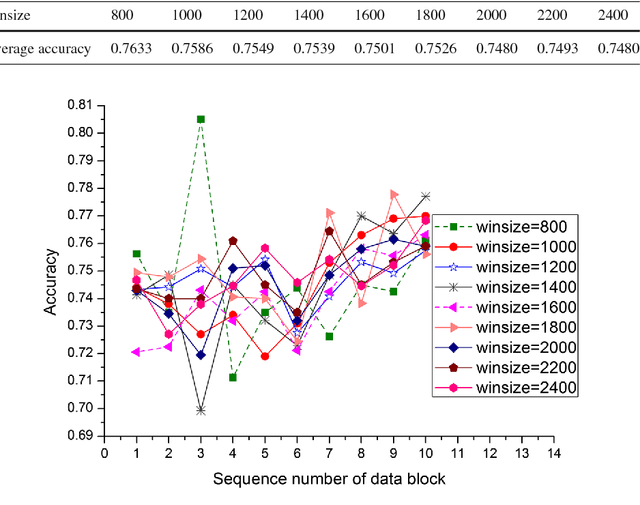
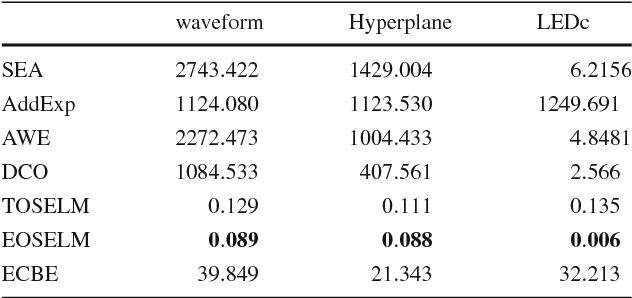
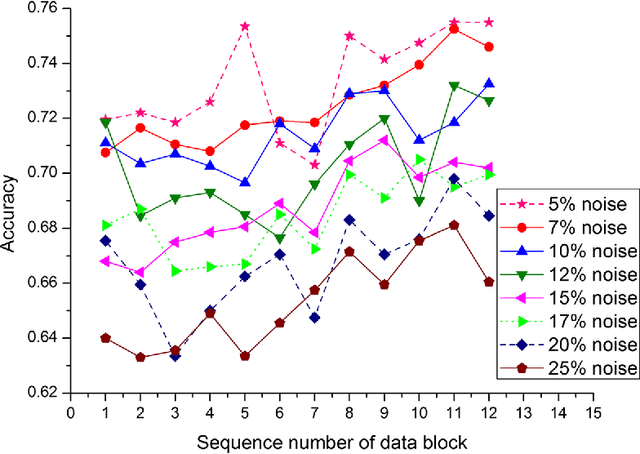
Data stream mining problem has caused widely concerns in the area of machine learning and data mining. In some recent studies, ensemble classification has been widely used in concept drift detection, however, most of them regard classification accuracy as a criterion for judging whether concept drift happening or not. Information entropy is an important and effective method for measuring uncertainty. Based on the information entropy theory, a new algorithm using information entropy to evaluate a classification result is developed. It uses ensemble classification techniques, and the weight of each classifier is decided through the entropy of the result produced by an ensemble classifiers system. When the concept in data streams changing, the classifiers' weight below a threshold value will be abandoned to adapt to a new concept in one time. In the experimental analysis section, six databases and four proposed algorithms are executed. The results show that the proposed method can not only handle concept drift effectively, but also have a better classification accuracy and time performance than the contrastive algorithms.