 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvatarShield: Visual Reinforcement Learning for Human-Centric Video Forgery Detection
May 21, 2025The rapid advancement of Artificial Intelligence Generated Content (AIGC) technologies, particularly in video generation, has led to unprecedented creative capabilities but also increased threats to information integrity, identity security, and public trust. Existing detection methods, while effective in general scenarios, lack robust solutions for human-centric videos, which pose greater risks due to their realism and potential for legal and ethical misuse. Moreover, current detection approaches often suffer from poor generalization, limited scalability, and reliance on labor-intensive supervised fine-tuning. To address these challenges, we propose AvatarShield, the first interpretable MLLM-based framework for detecting human-centric fake videos, enhanced via Group Relative Policy Optimization (GRPO). Through our carefully designed accuracy detection reward and temporal compensation reward, it effectively avoids the use of high-cost text annotation data, enabling precise temporal modeling and forgery detection. Meanwhile, we design a dual-encoder architecture, combining high-level semantic reasoning and low-level artifact amplification to guide MLLMs in effective forgery detection. We further collect FakeHumanVid, a large-scale human-centric video benchmark that includes synthesis methods guided by pose, audio, and text inputs, enabling rigorous evaluation of detection methods in real-world scenes. Extensive experiments show that AvatarShield significantly outperforms existing approaches in both in-domain and cross-domain detection, setting a new standard for human-centric video forensics.
SecureGS: Boosting the Security and Fidelity of 3D Gaussian Splatting Steganography
Mar 08, 2025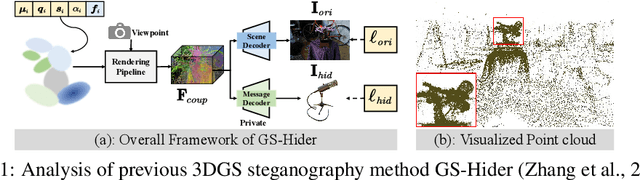
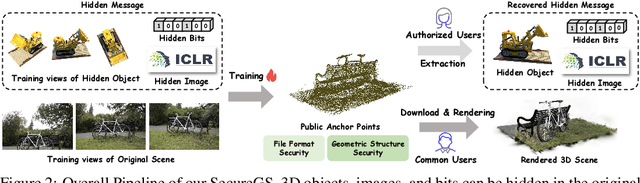
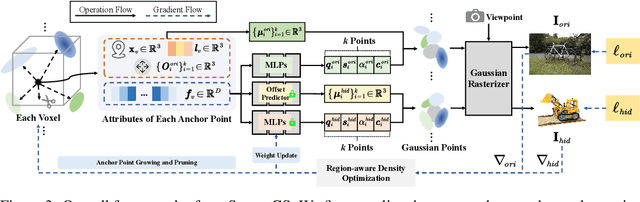

3D Gaussian Splatting (3DGS) has emerged as a premier method for 3D representation due to its real-time rendering and high-quality outputs, underscoring the critical need to protect the privacy of 3D assets. Traditional NeRF steganography methods fail to address the explicit nature of 3DGS since its point cloud files are publicly accessible. Existing GS steganography solutions mitigate some issues but still struggle with reduced rendering fidelity, increased computational demands, and security flaws, especially in the security of the geometric structure of the visualized point cloud. To address these demands, we propose a SecureGS, a secure and efficient 3DGS steganography framework inspired by Scaffold-GS's anchor point design and neural decoding. SecureGS uses a hybrid decoupled Gaussian encryption mechanism to embed offsets, scales, rotations, and RGB attributes of the hidden 3D Gaussian points in anchor point features, retrievable only by authorized users through privacy-preserving neural networks. To further enhance security, we propose a density region-aware anchor growing and pruning strategy that adaptively locates optimal hiding regions without exposing hidden information. Extensive experiments show that SecureGS significantly surpasses existing GS steganography methods in rendering fidelity, speed, and security.
OmniGuard: Hybrid Manipulation Localization via Augmented Versatile Deep Image Watermarking
Dec 02, 2024



With the rapid growth of generative AI and its widespread application in image editing, new risks have emerged regarding the authenticity and integrity of digital content. Existing versatile watermarking approaches suffer from trade-offs between tamper localization precision and visual quality. Constrained by the limited flexibility of previous framework, their localized watermark must remain fixed across all images. Under AIGC-editing, their copyright extraction accuracy is also unsatisfactory. To address these challenges, we propose OmniGuard, a novel augmented versatile watermarking approach that integrates proactive embedding with passive, blind extraction for robust copyright protection and tamper localization. OmniGuard employs a hybrid forensic framework that enables flexible localization watermark selection and introduces a degradation-aware tamper extraction network for precise localization under challenging conditions. Additionally, a lightweight AIGC-editing simulation layer is designed to enhance robustness across global and local editing. Extensive experiments show that OmniGuard achieves superior fidelity, robustness, and flexibility. Compared to the recent state-of-the-art approach EditGuard, our method outperforms it by 4.25dB in PSNR of the container image, 20.7% in F1-Score under noisy conditions, and 14.8% in average bit accuracy.
FakeShield: Explainable Image Forgery Detection and Localization via Multi-modal Large Language Models
Oct 03, 2024
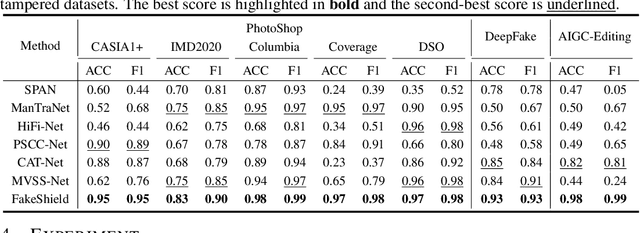
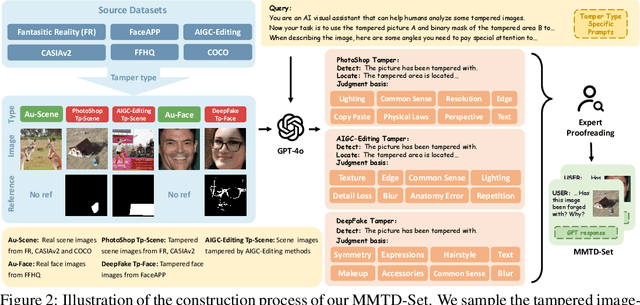

The rapid development of generative AI is a double-edged sword, which not only facilitates content creation but also makes image manipulation easier and more difficult to detect. Although current image forgery detection and localization (IFDL) methods are generally effective, they tend to face two challenges: \textbf{1)} black-box nature with unknown detection principle, \textbf{2)} limited generalization across diverse tampering methods (e.g., Photoshop, DeepFake, AIGC-Editing). To address these issues, we propose the explainable IFDL task and design FakeShield, a multi-modal framework capable of evaluating image authenticity, generating tampered region masks, and providing a judgment basis based on pixel-level and image-level tampering clues. Additionally, we leverage GPT-4o to enhance existing IFDL datasets, creating the Multi-Modal Tamper Description dataSet (MMTD-Set) for training FakeShield's tampering analysis capabilities. Meanwhile, we incorporate a Domain Tag-guided Explainable Forgery Detection Module (DTE-FDM) and a Multi-modal Forgery Localization Module (MFLM) to address various types of tamper detection interpretation and achieve forgery localization guided by detailed textual descriptions. Extensive experiments demonstrate that FakeShield effectively detects and localizes various tampering techniques, offering an explainable and superior solution compared to previous IFDL methods.
Protect-Your-IP: Scalable Source-Tracing and Attribution against Personalized Generation
May 26, 2024
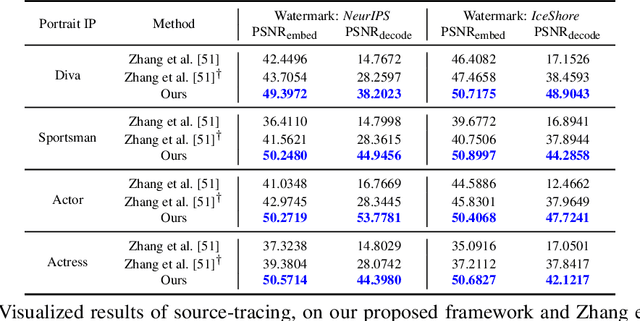


With the advent of personalized generation models, users can more readily create images resembling existing content, heightening the risk of violating portrait rights and intellectual property (IP). Traditional post-hoc detection and source-tracing methods for AI-generated content (AIGC) employ proactive watermark approaches; however, these are less effective against personalized generation models. Moreover, attribution techniques for AIGC rely on passive detection but often struggle to differentiate AIGC from authentic images, presenting a substantial challenge. Integrating these two processes into a cohesive framework not only meets the practical demands for protection and forensics but also improves the effectiveness of attribution tasks. Inspired by this insight, we propose a unified approach for image copyright source-tracing and attribution, introducing an innovative watermarking-attribution method that blends proactive and passive strategies. We embed copyright watermarks into protected images and train a watermark decoder to retrieve copyright information from the outputs of personalized models, using this watermark as an initial step for confirming if an image is AIGC-generated. To pinpoint specific generation techniques, we utilize powerful visual backbone networks for classification. Additionally, we implement an incremental learning strategy to adeptly attribute new personalized models without losing prior knowledge, thereby enhancing the model's adaptability to novel generation methods. We have conducted experiments using various celebrity portrait series sourced online, and the results affirm the efficacy of our method in source-tracing and attribution tasks, as well as its robustness against knowledge forgetting.
GS-Hider: Hiding Messages into 3D Gaussian Splatting
May 24, 2024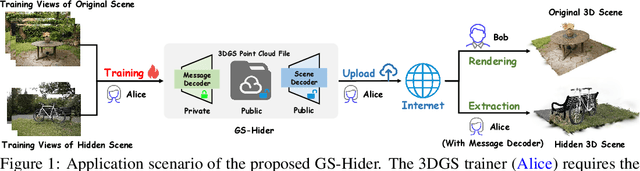



3D Gaussian Splatting (3DGS) has already become the emerging research focus in the fields of 3D scene reconstruction and novel view synthesis. Given that training a 3DGS requires a significant amount of time and computational cost, it is crucial to protect the copyright, integrity, and privacy of such 3D assets. Steganography, as a crucial technique for encrypted transmission and copyright protection, has been extensively studied. However, it still lacks profound exploration targeted at 3DGS. Unlike its predecessor NeRF, 3DGS possesses two distinct features: 1) explicit 3D representation; and 2) real-time rendering speeds. These characteristics result in the 3DGS point cloud files being public and transparent, with each Gaussian point having a clear physical significance. Therefore, ensuring the security and fidelity of the original 3D scene while embedding information into the 3DGS point cloud files is an extremely challenging task. To solve the above-mentioned issue, we first propose a steganography framework for 3DGS, dubbed GS-Hider, which can embed 3D scenes and images into original GS point clouds in an invisible manner and accurately extract the hidden messages. Specifically, we design a coupled secured feature attribute to replace the original 3DGS's spherical harmonics coefficients and then use a scene decoder and a message decoder to disentangle the original RGB scene and the hidden message. Extensive experiments demonstrated that the proposed GS-Hider can effectively conceal multimodal messages without compromising rendering quality and possesses exceptional security, robustness, capacity, and flexibility. Our project is available at: https://xuanyuzhang21.github.io/project/gshider.
V2A-Mark: Versatile Deep Visual-Audio Watermarking for Manipulation Localization and Copyright Protection
Apr 25, 2024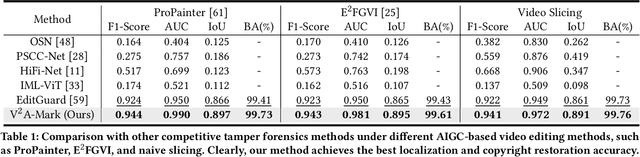
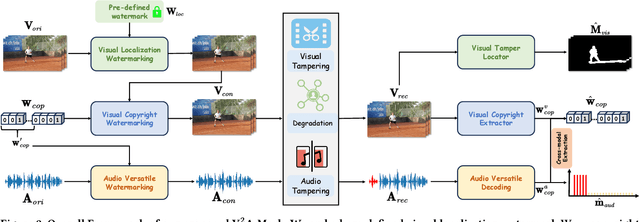
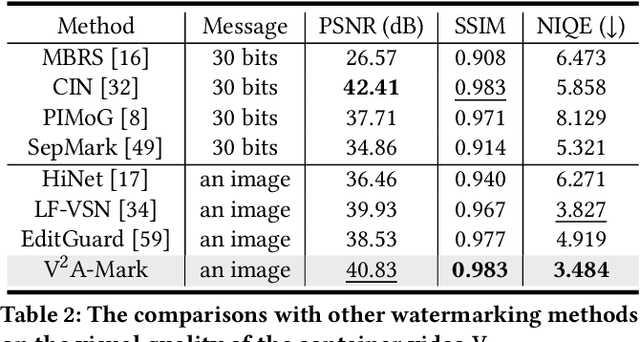
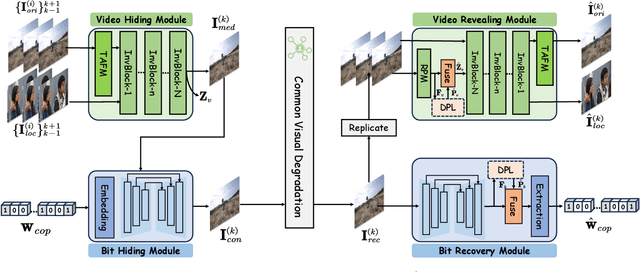
AI-generated video has revolutionized short video production, filmmaking, and personalized media, making video local editing an essential tool. However, this progress also blurs the line between reality and fiction, posing challenges in multimedia forensics. To solve this urgent issue, V2A-Mark is proposed to address the limitations of current video tampering forensics, such as poor generalizability, singular function, and single modality focus. Combining the fragility of video-into-video steganography with deep robust watermarking, our method can embed invisible visual-audio localization watermarks and copyright watermarks into the original video frames and audio, enabling precise manipulation localization and copyright protection. We also design a temporal alignment and fusion module and degradation prompt learning to enhance the localization accuracy and decoding robustness. Meanwhile, we introduce a sample-level audio localization method and a cross-modal copyright extraction mechanism to couple the information of audio and video frames. The effectiveness of V2A-Mark has been verified on a visual-audio tampering dataset, emphasizing its superiority in localization precision and copyright accuracy, crucial for the sustainable development of video editing in the AIGC video era.
BianQue: Balancing the Questioning and Suggestion Ability of Health LLMs with Multi-turn Health Conversations Polished by ChatGPT
Oct 24, 2023Large language models (LLMs) have performed well in providing general and extensive health suggestions in single-turn conversations, exemplified by systems such as ChatGPT, ChatGLM, ChatDoctor, DoctorGLM, and etc. However, the limited information provided by users during single turn results in inadequate personalization and targeting of the generated suggestions, which requires users to independently select the useful part. It is mainly caused by the missing ability to engage in multi-turn questioning. In real-world medical consultations, doctors usually employ a series of iterative inquiries to comprehend the patient's condition thoroughly, enabling them to provide effective and personalized suggestions subsequently, which can be defined as chain of questioning (CoQ) for LLMs. To improve the CoQ of LLMs, we propose BianQue, a ChatGLM-based LLM finetuned with the self-constructed health conversation dataset BianQueCorpus that is consist of multiple turns of questioning and health suggestions polished by ChatGPT. Experimental results demonstrate that the proposed BianQue can simultaneously balance the capabilities of both questioning and health suggestions, which will help promote the research and application of LLMs in the field of proactive health.