 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLARM: Streaming and Language-Aligned Reconstruction Model for Dynamic Scenes
Mar 25, 2026We propose SLARM, a feed-forward model that unifies dynamic scene reconstruction, semantic understanding, and real-time streaming inference. SLARM captures complex, non-uniform motion through higher-order motion modeling, trained solely on differentiable renderings without any flow supervision. Besides, SLARM distills semantic features from LSeg to obtain language-aligned representations. This design enables semantic querying via natural language, and the tight coupling between semantics and geometry further enhances the accuracy and robustness of dynamic reconstruction. Moreover, SLARM processes image sequences using window-based causal attention, achieving stable, low-latency streaming inference without accumulating memory cost. Within this unified framework, SLARM achieves state-of-the-art results in dynamic estimation, rendering quality, and scene parsing, improving motion accuracy by 21%, reconstruction PSNR by 1.6 dB, and segmentation mIoU by 20% over existing methods.
SecureGS: Boosting the Security and Fidelity of 3D Gaussian Splatting Steganography
Mar 08, 2025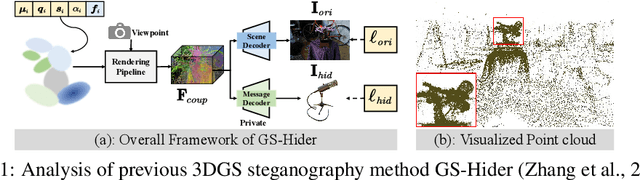
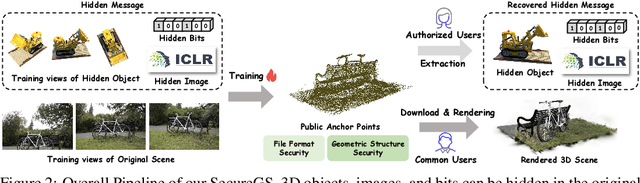
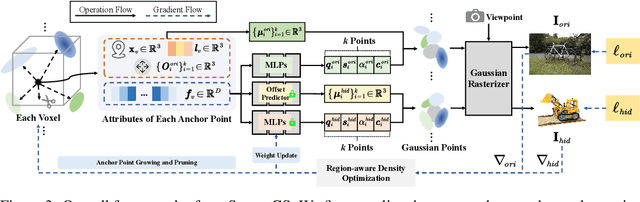

3D Gaussian Splatting (3DGS) has emerged as a premier method for 3D representation due to its real-time rendering and high-quality outputs, underscoring the critical need to protect the privacy of 3D assets. Traditional NeRF steganography methods fail to address the explicit nature of 3DGS since its point cloud files are publicly accessible. Existing GS steganography solutions mitigate some issues but still struggle with reduced rendering fidelity, increased computational demands, and security flaws, especially in the security of the geometric structure of the visualized point cloud. To address these demands, we propose a SecureGS, a secure and efficient 3DGS steganography framework inspired by Scaffold-GS's anchor point design and neural decoding. SecureGS uses a hybrid decoupled Gaussian encryption mechanism to embed offsets, scales, rotations, and RGB attributes of the hidden 3D Gaussian points in anchor point features, retrievable only by authorized users through privacy-preserving neural networks. To further enhance security, we propose a density region-aware anchor growing and pruning strategy that adaptively locates optimal hiding regions without exposing hidden information. Extensive experiments show that SecureGS significantly surpasses existing GS steganography methods in rendering fidelity, speed, and security.
RelayGS: Reconstructing Dynamic Scenes with Large-Scale and Complex Motions via Relay Gaussians
Dec 03, 2024
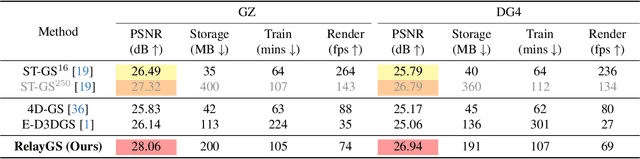
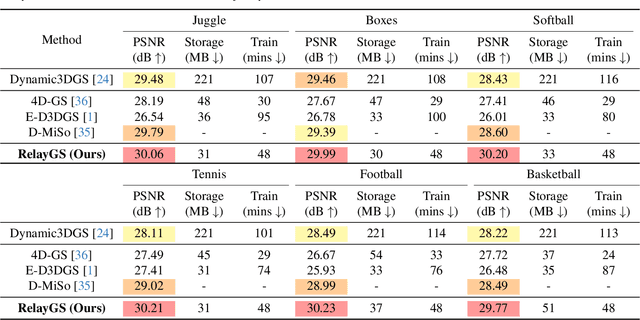
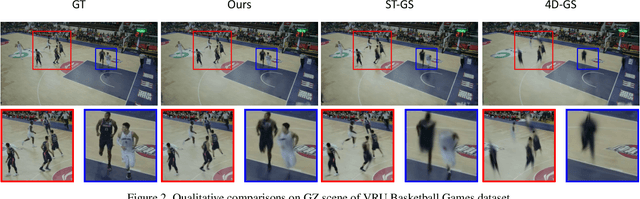
Reconstructing dynamic scenes with large-scale and complex motions remains a significant challenge. Recent techniques like Neural Radiance Fields and 3D Gaussian Splatting (3DGS) have shown promise but still struggle with scenes involving substantial movement. This paper proposes RelayGS, a novel method based on 3DGS, specifically designed to represent and reconstruct highly dynamic scenes. Our RelayGS learns a complete 4D representation with canonical 3D Gaussians and a compact motion field, consisting of three stages. First, we learn a fundamental 3DGS from all frames, ignoring temporal scene variations, and use a learnable mask to separate the highly dynamic foreground from the minimally moving background. Second, we replicate multiple copies of the decoupled foreground Gaussians from the first stage, each corresponding to a temporal segment, and optimize them using pseudo-views constructed from multiple frames within each segment. These Gaussians, termed Relay Gaussians, act as explicit relay nodes, simplifying and breaking down large-scale motion trajectories into smaller, manageable segments. Finally, we jointly learn the scene's temporal motion and refine the canonical Gaussians learned from the first two stages. We conduct thorough experiments on two dynamic scene datasets featuring large and complex motions, where our RelayGS outperforms state-of-the-arts by more than 1 dB in PSNR, and successfully reconstructs real-world basketball game scenes in a much more complete and coherent manner, whereas previous methods usually struggle to capture the complex motion of players. Code will be publicly available at https://github.com/gqk/RelayGS
InstanceGaussian: Appearance-Semantic Joint Gaussian Representation for 3D Instance-Level Perception
Nov 28, 2024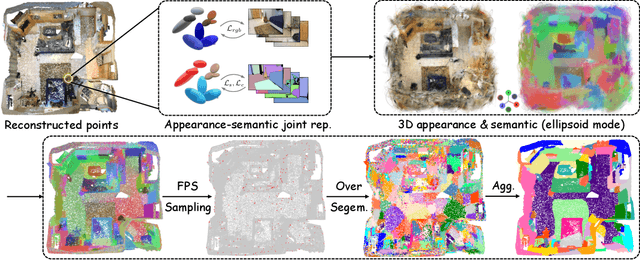
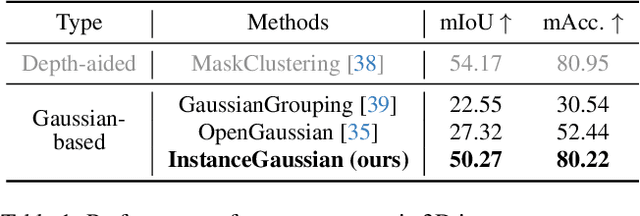
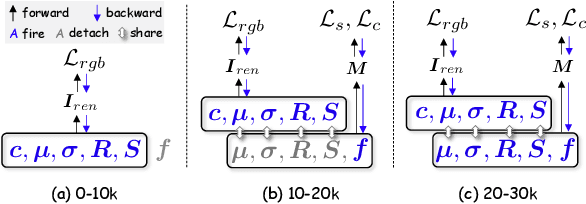
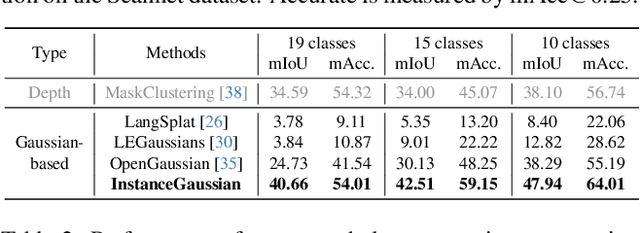
3D scene understanding has become an essential area of research with applications in autonomous driving, robotics, and augmented reality. Recently, 3D Gaussian Splatting (3DGS) has emerged as a powerful approach, combining explicit modeling with neural adaptability to provide efficient and detailed scene representations. However, three major challenges remain in leveraging 3DGS for scene understanding: 1) an imbalance between appearance and semantics, where dense Gaussian usage for fine-grained texture modeling does not align with the minimal requirements for semantic attributes; 2) inconsistencies between appearance and semantics, as purely appearance-based Gaussians often misrepresent object boundaries; and 3) reliance on top-down instance segmentation methods, which struggle with uneven category distributions, leading to over- or under-segmentation. In this work, we propose InstanceGaussian, a method that jointly learns appearance and semantic features while adaptively aggregating instances. Our contributions include: i) a novel Semantic-Scaffold-GS representation balancing appearance and semantics to improve feature representations and boundary delineation; ii) a progressive appearance-semantic joint training strategy to enhance stability and segmentation accuracy; and iii) a bottom-up, category-agnostic instance aggregation approach that addresses segmentation challenges through farthest point sampling and connected component analysis. Our approach achieves state-of-the-art performance in category-agnostic, open-vocabulary 3D point-level segmentation, highlighting the effectiveness of the proposed representation and training strategies. Project page: https://lhj-git.github.io/InstanceGaussian/
HiCoM: Hierarchical Coherent Motion for Streamable Dynamic Scene with 3D Gaussian Splatting
Nov 12, 2024



The online reconstruction of dynamic scenes from multi-view streaming videos faces significant challenges in training, rendering and storage efficiency. Harnessing superior learning speed and real-time rendering capabilities, 3D Gaussian Splatting (3DGS) has recently demonstrated considerable potential in this field. However, 3DGS can be inefficient in terms of storage and prone to overfitting by excessively growing Gaussians, particularly with limited views. This paper proposes an efficient framework, dubbed HiCoM, with three key components. First, we construct a compact and robust initial 3DGS representation using a perturbation smoothing strategy. Next, we introduce a Hierarchical Coherent Motion mechanism that leverages the inherent non-uniform distribution and local consistency of 3D Gaussians to swiftly and accurately learn motions across frames. Finally, we continually refine the 3DGS with additional Gaussians, which are later merged into the initial 3DGS to maintain consistency with the evolving scene. To preserve a compact representation, an equivalent number of low-opacity Gaussians that minimally impact the representation are removed before processing subsequent frames. Extensive experiments conducted on two widely used datasets show that our framework improves learning efficiency of the state-of-the-art methods by about $20\%$ and reduces the data storage by $85\%$, achieving competitive free-viewpoint video synthesis quality but with higher robustness and stability. Moreover, by parallel learning multiple frames simultaneously, our HiCoM decreases the average training wall time to $<2$ seconds per frame with negligible performance degradation, substantially boosting real-world applicability and responsiveness.
OpenGaussian: Towards Point-Level 3D Gaussian-based Open Vocabulary Understanding
Jun 04, 2024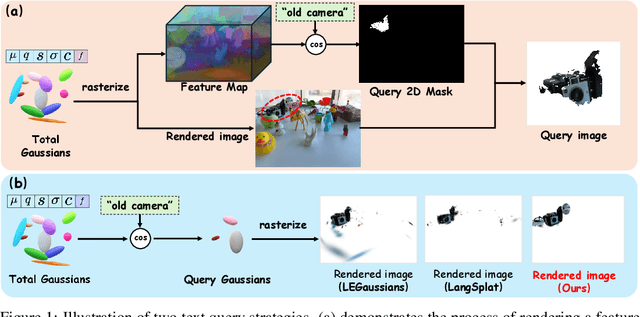


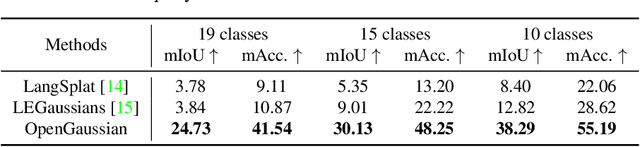
This paper introduces OpenGaussian, a method based on 3D Gaussian Splatting (3DGS) capable of 3D point-level open vocabulary understanding. Our primary motivation stems from observing that existing 3DGS-based open vocabulary methods mainly focus on 2D pixel-level parsing. These methods struggle with 3D point-level tasks due to weak feature expressiveness and inaccurate 2D-3D feature associations. To ensure robust feature presentation and 3D point-level understanding, we first employ SAM masks without cross-frame associations to train instance features with 3D consistency. These features exhibit both intra-object consistency and inter-object distinction. Then, we propose a two-stage codebook to discretize these features from coarse to fine levels. At the coarse level, we consider the positional information of 3D points to achieve location-based clustering, which is then refined at the fine level. Finally, we introduce an instance-level 3D-2D feature association method that links 3D points to 2D masks, which are further associated with 2D CLIP features. Extensive experiments, including open vocabulary-based 3D object selection, 3D point cloud understanding, click-based 3D object selection, and ablation studies, demonstrate the effectiveness of our proposed method. Project page: https://3d-aigc.github.io/OpenGaussian
Fourier123: One Image to High-Quality 3D Object Generation with Hybrid Fourier Score Distillation
May 31, 2024Single image-to-3D generation is pivotal for crafting controllable 3D assets. Given its underconstrained nature, we leverage geometric priors from a 3D novel view generation diffusion model and appearance priors from a 2D image generation method to guide the optimization process. We note that a disparity exists between the training datasets of 2D and 3D diffusion models, leading to their outputs showing marked differences in appearance. Specifically, 2D models tend to deliver more detailed visuals, whereas 3D models produce consistent yet over-smooth results across different views. Hence, we optimize a set of 3D Gaussians using 3D priors in spatial domain to ensure geometric consistency, while exploiting 2D priors in the frequency domain through Fourier transform for higher visual quality. This 2D-3D hybrid Fourier Score Distillation objective function (dubbed hy-FSD), can be integrated into existing 3D generation methods, yielding significant performance improvements. With this technique, we further develop an image-to-3D generation pipeline to create high-quality 3D objects within one minute, named Fourier123. Extensive experiments demonstrate that Fourier123 excels in efficient generation with rapid convergence speed and visual-friendly generation results.
GS-Hider: Hiding Messages into 3D Gaussian Splatting
May 24, 2024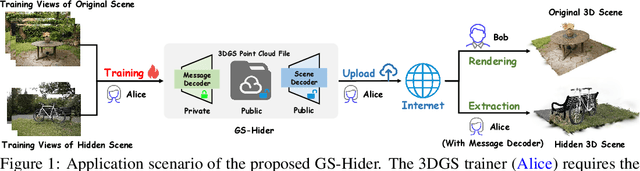



3D Gaussian Splatting (3DGS) has already become the emerging research focus in the fields of 3D scene reconstruction and novel view synthesis. Given that training a 3DGS requires a significant amount of time and computational cost, it is crucial to protect the copyright, integrity, and privacy of such 3D assets. Steganography, as a crucial technique for encrypted transmission and copyright protection, has been extensively studied. However, it still lacks profound exploration targeted at 3DGS. Unlike its predecessor NeRF, 3DGS possesses two distinct features: 1) explicit 3D representation; and 2) real-time rendering speeds. These characteristics result in the 3DGS point cloud files being public and transparent, with each Gaussian point having a clear physical significance. Therefore, ensuring the security and fidelity of the original 3D scene while embedding information into the 3DGS point cloud files is an extremely challenging task. To solve the above-mentioned issue, we first propose a steganography framework for 3DGS, dubbed GS-Hider, which can embed 3D scenes and images into original GS point clouds in an invisible manner and accurately extract the hidden messages. Specifically, we design a coupled secured feature attribute to replace the original 3DGS's spherical harmonics coefficients and then use a scene decoder and a message decoder to disentangle the original RGB scene and the hidden message. Extensive experiments demonstrated that the proposed GS-Hider can effectively conceal multimodal messages without compromising rendering quality and possesses exceptional security, robustness, capacity, and flexibility. Our project is available at: https://xuanyuzhang21.github.io/project/gshider.
Mirror-3DGS: Incorporating Mirror Reflections into 3D Gaussian Splatting
Apr 01, 2024
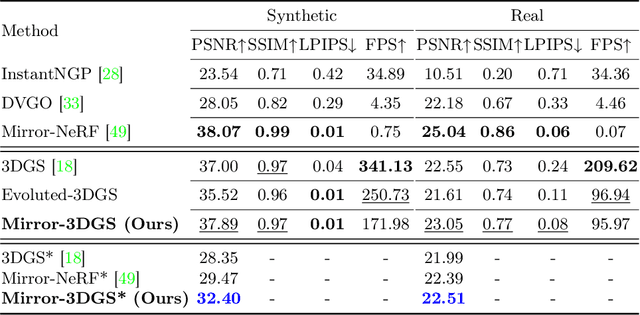
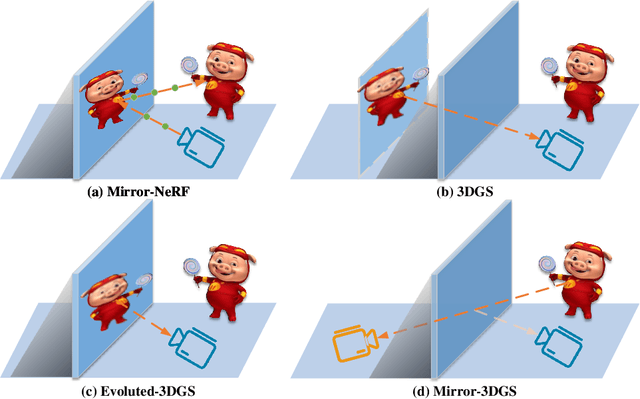
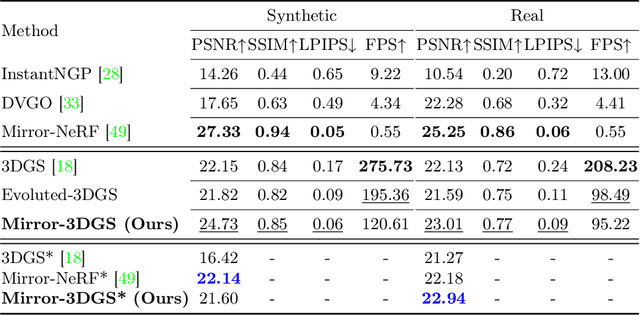
3D Gaussian Splatting (3DGS) has marked a significant breakthrough in the realm of 3D scene reconstruction and novel view synthesis. However, 3DGS, much like its predecessor Neural Radiance Fields (NeRF), struggles to accurately model physical reflections, particularly in mirrors that are ubiquitous in real-world scenes. This oversight mistakenly perceives reflections as separate entities that physically exist, resulting in inaccurate reconstructions and inconsistent reflective properties across varied viewpoints. To address this pivotal challenge, we introduce Mirror-3DGS, an innovative rendering framework devised to master the intricacies of mirror geometries and reflections, paving the way for the generation of realistically depicted mirror reflections. By ingeniously incorporating mirror attributes into the 3DGS and leveraging the principle of plane mirror imaging, Mirror-3DGS crafts a mirrored viewpoint to observe from behind the mirror, enriching the realism of scene renderings. Extensive assessments, spanning both synthetic and real-world scenes, showcase our method's ability to render novel views with enhanced fidelity in real-time, surpassing the state-of-the-art Mirror-NeRF specifically within the challenging mirror regions. Our code will be made publicly available for reproducible research.