 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrive Any Mesh: 4D Latent Diffusion for Mesh Deformation from Video
Jun 09, 2025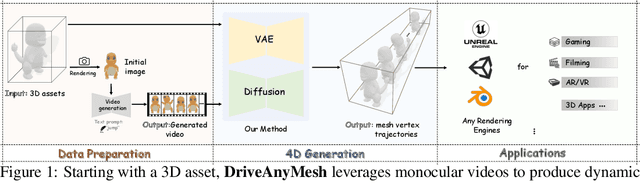



We propose DriveAnyMesh, a method for driving mesh guided by monocular video. Current 4D generation techniques encounter challenges with modern rendering engines. Implicit methods have low rendering efficiency and are unfriendly to rasterization-based engines, while skeletal methods demand significant manual effort and lack cross-category generalization. Animating existing 3D assets, instead of creating 4D assets from scratch, demands a deep understanding of the input's 3D structure. To tackle these challenges, we present a 4D diffusion model that denoises sequences of latent sets, which are then decoded to produce mesh animations from point cloud trajectory sequences. These latent sets leverage a transformer-based variational autoencoder, simultaneously capturing 3D shape and motion information. By employing a spatiotemporal, transformer-based diffusion model, information is exchanged across multiple latent frames, enhancing the efficiency and generalization of the generated results. Our experimental results demonstrate that DriveAnyMesh can rapidly produce high-quality animations for complex motions and is compatible with modern rendering engines. This method holds potential for applications in both the gaming and filming industries.
SecureGS: Boosting the Security and Fidelity of 3D Gaussian Splatting Steganography
Mar 08, 2025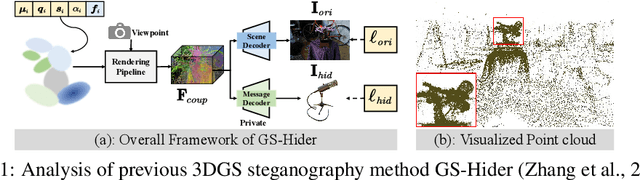
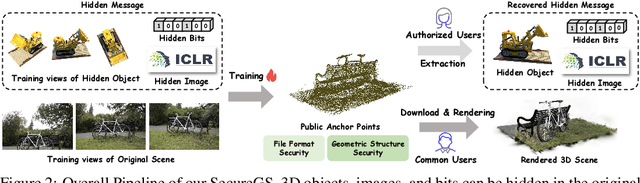
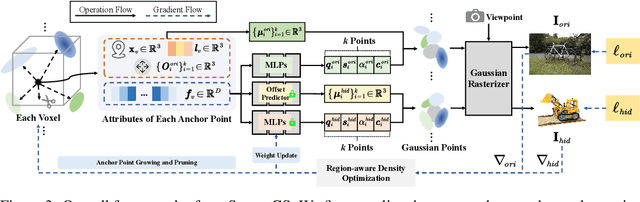

3D Gaussian Splatting (3DGS) has emerged as a premier method for 3D representation due to its real-time rendering and high-quality outputs, underscoring the critical need to protect the privacy of 3D assets. Traditional NeRF steganography methods fail to address the explicit nature of 3DGS since its point cloud files are publicly accessible. Existing GS steganography solutions mitigate some issues but still struggle with reduced rendering fidelity, increased computational demands, and security flaws, especially in the security of the geometric structure of the visualized point cloud. To address these demands, we propose a SecureGS, a secure and efficient 3DGS steganography framework inspired by Scaffold-GS's anchor point design and neural decoding. SecureGS uses a hybrid decoupled Gaussian encryption mechanism to embed offsets, scales, rotations, and RGB attributes of the hidden 3D Gaussian points in anchor point features, retrievable only by authorized users through privacy-preserving neural networks. To further enhance security, we propose a density region-aware anchor growing and pruning strategy that adaptively locates optimal hiding regions without exposing hidden information. Extensive experiments show that SecureGS significantly surpasses existing GS steganography methods in rendering fidelity, speed, and security.
RelayGS: Reconstructing Dynamic Scenes with Large-Scale and Complex Motions via Relay Gaussians
Dec 03, 2024
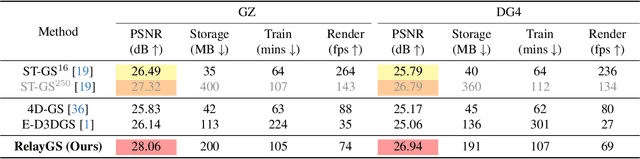
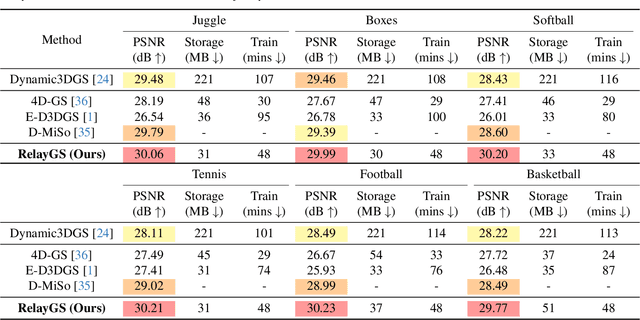
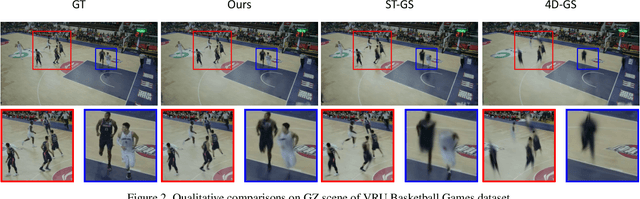
Reconstructing dynamic scenes with large-scale and complex motions remains a significant challenge. Recent techniques like Neural Radiance Fields and 3D Gaussian Splatting (3DGS) have shown promise but still struggle with scenes involving substantial movement. This paper proposes RelayGS, a novel method based on 3DGS, specifically designed to represent and reconstruct highly dynamic scenes. Our RelayGS learns a complete 4D representation with canonical 3D Gaussians and a compact motion field, consisting of three stages. First, we learn a fundamental 3DGS from all frames, ignoring temporal scene variations, and use a learnable mask to separate the highly dynamic foreground from the minimally moving background. Second, we replicate multiple copies of the decoupled foreground Gaussians from the first stage, each corresponding to a temporal segment, and optimize them using pseudo-views constructed from multiple frames within each segment. These Gaussians, termed Relay Gaussians, act as explicit relay nodes, simplifying and breaking down large-scale motion trajectories into smaller, manageable segments. Finally, we jointly learn the scene's temporal motion and refine the canonical Gaussians learned from the first two stages. We conduct thorough experiments on two dynamic scene datasets featuring large and complex motions, where our RelayGS outperforms state-of-the-arts by more than 1 dB in PSNR, and successfully reconstructs real-world basketball game scenes in a much more complete and coherent manner, whereas previous methods usually struggle to capture the complex motion of players. Code will be publicly available at https://github.com/gqk/RelayGS
InstanceGaussian: Appearance-Semantic Joint Gaussian Representation for 3D Instance-Level Perception
Nov 28, 2024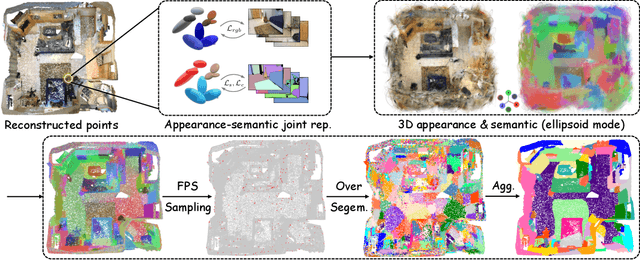
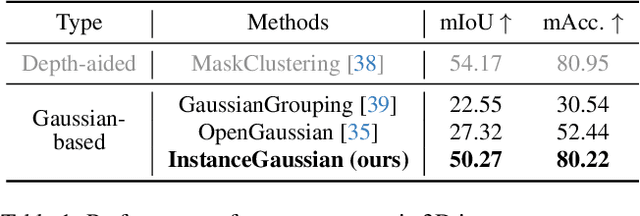
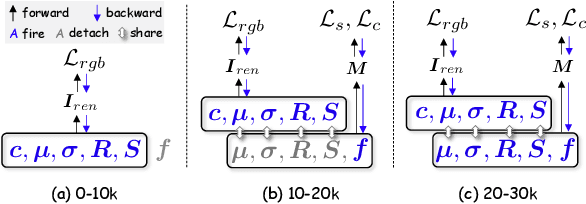
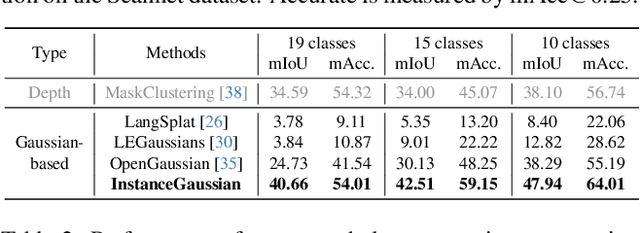
3D scene understanding has become an essential area of research with applications in autonomous driving, robotics, and augmented reality. Recently, 3D Gaussian Splatting (3DGS) has emerged as a powerful approach, combining explicit modeling with neural adaptability to provide efficient and detailed scene representations. However, three major challenges remain in leveraging 3DGS for scene understanding: 1) an imbalance between appearance and semantics, where dense Gaussian usage for fine-grained texture modeling does not align with the minimal requirements for semantic attributes; 2) inconsistencies between appearance and semantics, as purely appearance-based Gaussians often misrepresent object boundaries; and 3) reliance on top-down instance segmentation methods, which struggle with uneven category distributions, leading to over- or under-segmentation. In this work, we propose InstanceGaussian, a method that jointly learns appearance and semantic features while adaptively aggregating instances. Our contributions include: i) a novel Semantic-Scaffold-GS representation balancing appearance and semantics to improve feature representations and boundary delineation; ii) a progressive appearance-semantic joint training strategy to enhance stability and segmentation accuracy; and iii) a bottom-up, category-agnostic instance aggregation approach that addresses segmentation challenges through farthest point sampling and connected component analysis. Our approach achieves state-of-the-art performance in category-agnostic, open-vocabulary 3D point-level segmentation, highlighting the effectiveness of the proposed representation and training strategies. Project page: https://lhj-git.github.io/InstanceGaussian/
OpenGaussian: Towards Point-Level 3D Gaussian-based Open Vocabulary Understanding
Jun 04, 2024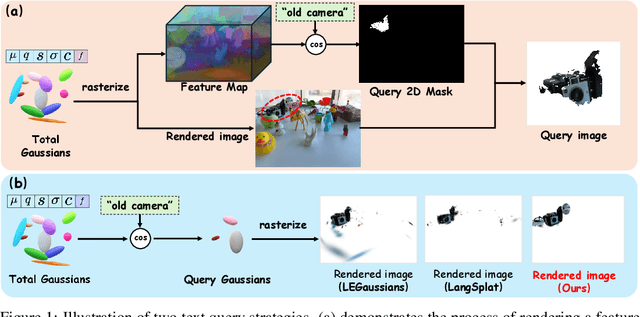


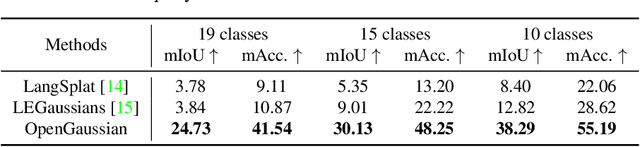
This paper introduces OpenGaussian, a method based on 3D Gaussian Splatting (3DGS) capable of 3D point-level open vocabulary understanding. Our primary motivation stems from observing that existing 3DGS-based open vocabulary methods mainly focus on 2D pixel-level parsing. These methods struggle with 3D point-level tasks due to weak feature expressiveness and inaccurate 2D-3D feature associations. To ensure robust feature presentation and 3D point-level understanding, we first employ SAM masks without cross-frame associations to train instance features with 3D consistency. These features exhibit both intra-object consistency and inter-object distinction. Then, we propose a two-stage codebook to discretize these features from coarse to fine levels. At the coarse level, we consider the positional information of 3D points to achieve location-based clustering, which is then refined at the fine level. Finally, we introduce an instance-level 3D-2D feature association method that links 3D points to 2D masks, which are further associated with 2D CLIP features. Extensive experiments, including open vocabulary-based 3D object selection, 3D point cloud understanding, click-based 3D object selection, and ablation studies, demonstrate the effectiveness of our proposed method. Project page: https://3d-aigc.github.io/OpenGaussian
S3-SLAM: Sparse Tri-plane Encoding for Neural Implicit SLAM
Apr 28, 2024With the emergence of Neural Radiance Fields (NeRF), neural implicit representations have gained widespread applications across various domains, including simultaneous localization and mapping. However, current neural implicit SLAM faces a challenging trade-off problem between performance and the number of parameters. To address this problem, we propose sparse tri-plane encoding, which efficiently achieves scene reconstruction at resolutions up to 512 using only 2~4% of the commonly used tri-plane parameters (reduced from 100MB to 2~4MB). On this basis, we design S3-SLAM to achieve rapid and high-quality tracking and mapping through sparsifying plane parameters and integrating orthogonal features of tri-plane. Furthermore, we develop hierarchical bundle adjustment to achieve globally consistent geometric structures and reconstruct high-resolution appearance. Experimental results demonstrate that our approach achieves competitive tracking and scene reconstruction with minimal parameters on three datasets. Source code will soon be available.
Mirror-3DGS: Incorporating Mirror Reflections into 3D Gaussian Splatting
Apr 01, 2024
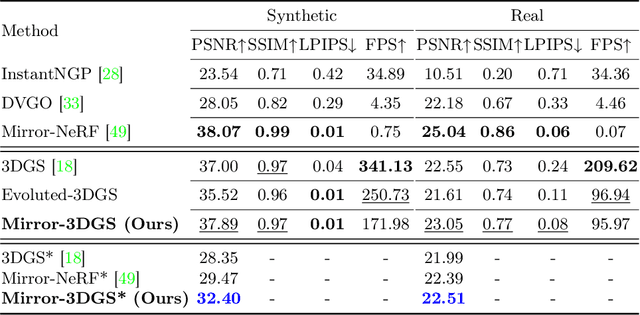
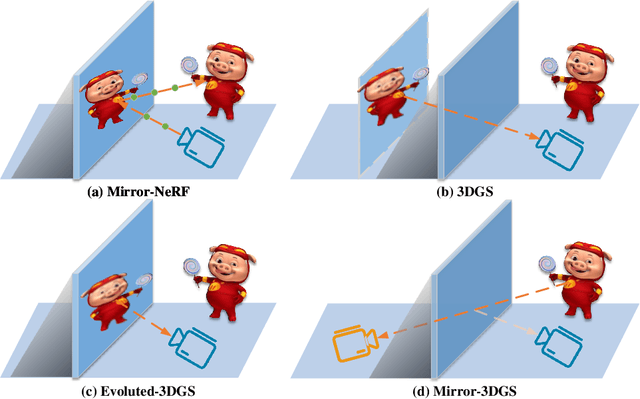
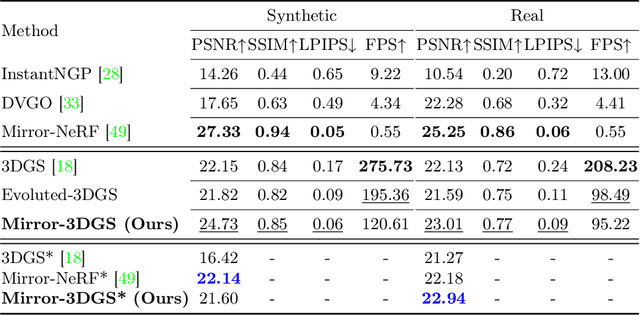
3D Gaussian Splatting (3DGS) has marked a significant breakthrough in the realm of 3D scene reconstruction and novel view synthesis. However, 3DGS, much like its predecessor Neural Radiance Fields (NeRF), struggles to accurately model physical reflections, particularly in mirrors that are ubiquitous in real-world scenes. This oversight mistakenly perceives reflections as separate entities that physically exist, resulting in inaccurate reconstructions and inconsistent reflective properties across varied viewpoints. To address this pivotal challenge, we introduce Mirror-3DGS, an innovative rendering framework devised to master the intricacies of mirror geometries and reflections, paving the way for the generation of realistically depicted mirror reflections. By ingeniously incorporating mirror attributes into the 3DGS and leveraging the principle of plane mirror imaging, Mirror-3DGS crafts a mirrored viewpoint to observe from behind the mirror, enriching the realism of scene renderings. Extensive assessments, spanning both synthetic and real-world scenes, showcase our method's ability to render novel views with enhanced fidelity in real-time, surpassing the state-of-the-art Mirror-NeRF specifically within the challenging mirror regions. Our code will be made publicly available for reproducible research.
PAS-SLAM: A Visual SLAM System for Planar Ambiguous Scenes
Feb 09, 2024Visual SLAM (Simultaneous Localization and Mapping) based on planar features has found widespread applications in fields such as environmental structure perception and augmented reality. However, current research faces challenges in accurately localizing and mapping in planar ambiguous scenes, primarily due to the poor accuracy of the employed planar features and data association methods. In this paper, we propose a visual SLAM system based on planar features designed for planar ambiguous scenes, encompassing planar processing, data association, and multi-constraint factor graph optimization. We introduce a planar processing strategy that integrates semantic information with planar features, extracting the edges and vertices of planes to be utilized in tasks such as plane selection, data association, and pose optimization. Next, we present an integrated data association strategy that combines plane parameters, semantic information, projection IoU (Intersection over Union), and non-parametric tests, achieving accurate and robust plane data association in planar ambiguous scenes. Finally, we design a set of multi-constraint factor graphs for camera pose optimization. Qualitative and quantitative experiments conducted on publicly available datasets demonstrate that our proposed system competes effectively in both accuracy and robustness in terms of map construction and camera localization compared to state-of-the-art methods.
Language-Assisted 3D Scene Understanding
Dec 31, 2023



The scale and quality of point cloud datasets constrain the advancement of point cloud learning. Recently, with the development of multi-modal learning, the incorporation of domain-agnostic prior knowledge from other modalities, such as images and text, to assist in point cloud feature learning has been considered a promising avenue. Existing methods have demonstrated the effectiveness of multi-modal contrastive training and feature distillation on point clouds. However, challenges remain, including the requirement for paired triplet data, redundancy and ambiguity in supervised features, and the disruption of the original priors. In this paper, we propose a language-assisted approach to point cloud feature learning (LAST-PCL), enriching semantic concepts through LLMs-based text enrichment. We achieve de-redundancy and feature dimensionality reduction without compromising textual priors by statistical-based and training-free significant feature selection. Furthermore, we also delve into an in-depth analysis of the impact of text contrastive training on the point cloud. Extensive experiments validate that the proposed method learns semantically meaningful point cloud features and achieves state-of-the-art or comparable performance in 3D semantic segmentation, 3D object detection, and 3D scene classification tasks.
GIR: 3D Gaussian Inverse Rendering for Relightable Scene Factorization
Dec 08, 2023



This paper presents GIR, a 3D Gaussian Inverse Rendering method for relightable scene factorization. Compared to existing methods leveraging discrete meshes or neural implicit fields for inverse rendering, our method utilizes 3D Gaussians to estimate the material properties, illumination, and geometry of an object from multi-view images. Our study is motivated by the evidence showing that 3D Gaussian is a more promising backbone than neural fields in terms of performance, versatility, and efficiency. In this paper, we aim to answer the question: ``How can 3D Gaussian be applied to improve the performance of inverse rendering?'' To address the complexity of estimating normals based on discrete and often in-homogeneous distributed 3D Gaussian representations, we proposed an efficient self-regularization method that facilitates the modeling of surface normals without the need for additional supervision. To reconstruct indirect illumination, we propose an approach that simulates ray tracing. Extensive experiments demonstrate our proposed GIR's superior performance over existing methods across multiple tasks on a variety of widely used datasets in inverse rendering. This substantiates its efficacy and broad applicability, highlighting its potential as an influential tool in relighting and reconstruction. Project page: https://3dgir.github.io