 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstanceGaussian: Appearance-Semantic Joint Gaussian Representation for 3D Instance-Level Perception
Nov 28, 2024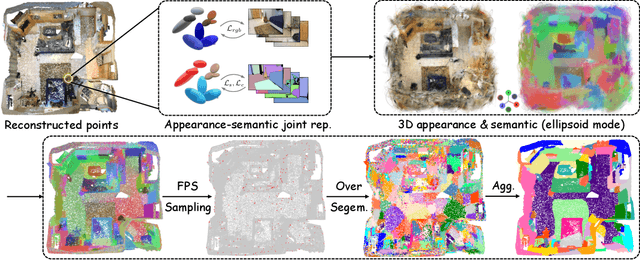
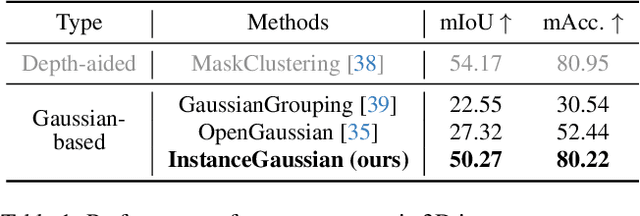
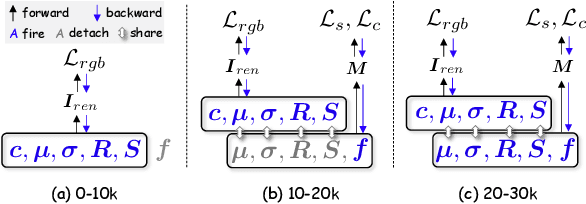
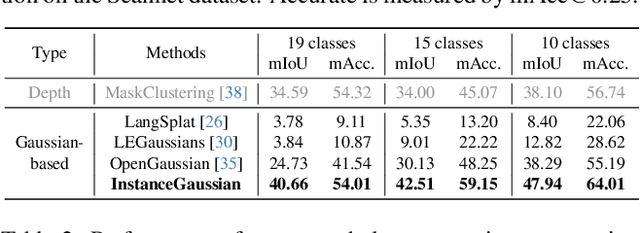
3D scene understanding has become an essential area of research with applications in autonomous driving, robotics, and augmented reality. Recently, 3D Gaussian Splatting (3DGS) has emerged as a powerful approach, combining explicit modeling with neural adaptability to provide efficient and detailed scene representations. However, three major challenges remain in leveraging 3DGS for scene understanding: 1) an imbalance between appearance and semantics, where dense Gaussian usage for fine-grained texture modeling does not align with the minimal requirements for semantic attributes; 2) inconsistencies between appearance and semantics, as purely appearance-based Gaussians often misrepresent object boundaries; and 3) reliance on top-down instance segmentation methods, which struggle with uneven category distributions, leading to over- or under-segmentation. In this work, we propose InstanceGaussian, a method that jointly learns appearance and semantic features while adaptively aggregating instances. Our contributions include: i) a novel Semantic-Scaffold-GS representation balancing appearance and semantics to improve feature representations and boundary delineation; ii) a progressive appearance-semantic joint training strategy to enhance stability and segmentation accuracy; and iii) a bottom-up, category-agnostic instance aggregation approach that addresses segmentation challenges through farthest point sampling and connected component analysis. Our approach achieves state-of-the-art performance in category-agnostic, open-vocabulary 3D point-level segmentation, highlighting the effectiveness of the proposed representation and training strategies. Project page: https://lhj-git.github.io/InstanceGaussian/
OpenGaussian: Towards Point-Level 3D Gaussian-based Open Vocabulary Understanding
Jun 04, 2024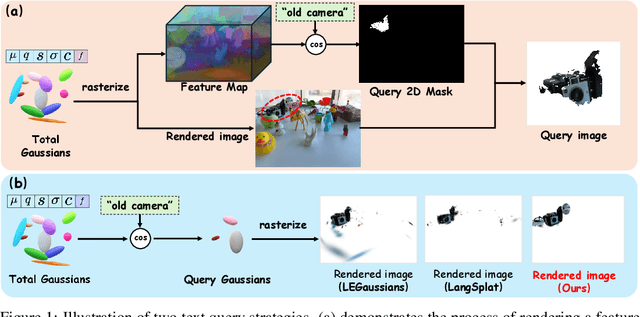


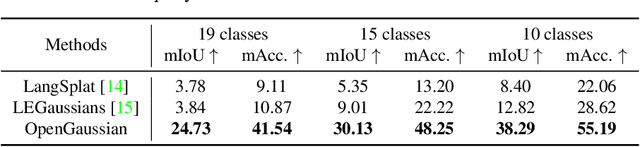
This paper introduces OpenGaussian, a method based on 3D Gaussian Splatting (3DGS) capable of 3D point-level open vocabulary understanding. Our primary motivation stems from observing that existing 3DGS-based open vocabulary methods mainly focus on 2D pixel-level parsing. These methods struggle with 3D point-level tasks due to weak feature expressiveness and inaccurate 2D-3D feature associations. To ensure robust feature presentation and 3D point-level understanding, we first employ SAM masks without cross-frame associations to train instance features with 3D consistency. These features exhibit both intra-object consistency and inter-object distinction. Then, we propose a two-stage codebook to discretize these features from coarse to fine levels. At the coarse level, we consider the positional information of 3D points to achieve location-based clustering, which is then refined at the fine level. Finally, we introduce an instance-level 3D-2D feature association method that links 3D points to 2D masks, which are further associated with 2D CLIP features. Extensive experiments, including open vocabulary-based 3D object selection, 3D point cloud understanding, click-based 3D object selection, and ablation studies, demonstrate the effectiveness of our proposed method. Project page: https://3d-aigc.github.io/OpenGaussian
Fourier123: One Image to High-Quality 3D Object Generation with Hybrid Fourier Score Distillation
May 31, 2024Single image-to-3D generation is pivotal for crafting controllable 3D assets. Given its underconstrained nature, we leverage geometric priors from a 3D novel view generation diffusion model and appearance priors from a 2D image generation method to guide the optimization process. We note that a disparity exists between the training datasets of 2D and 3D diffusion models, leading to their outputs showing marked differences in appearance. Specifically, 2D models tend to deliver more detailed visuals, whereas 3D models produce consistent yet over-smooth results across different views. Hence, we optimize a set of 3D Gaussians using 3D priors in spatial domain to ensure geometric consistency, while exploiting 2D priors in the frequency domain through Fourier transform for higher visual quality. This 2D-3D hybrid Fourier Score Distillation objective function (dubbed hy-FSD), can be integrated into existing 3D generation methods, yielding significant performance improvements. With this technique, we further develop an image-to-3D generation pipeline to create high-quality 3D objects within one minute, named Fourier123. Extensive experiments demonstrate that Fourier123 excels in efficient generation with rapid convergence speed and visual-friendly generation results.
Mirror-3DGS: Incorporating Mirror Reflections into 3D Gaussian Splatting
Apr 01, 2024
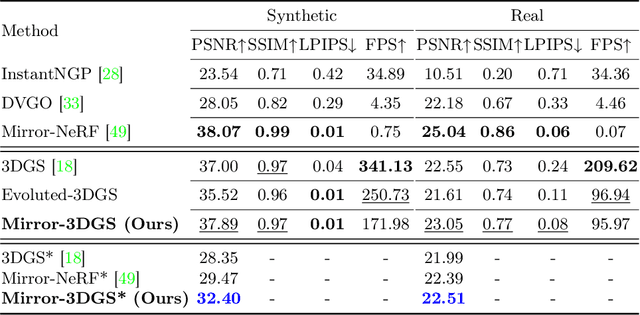
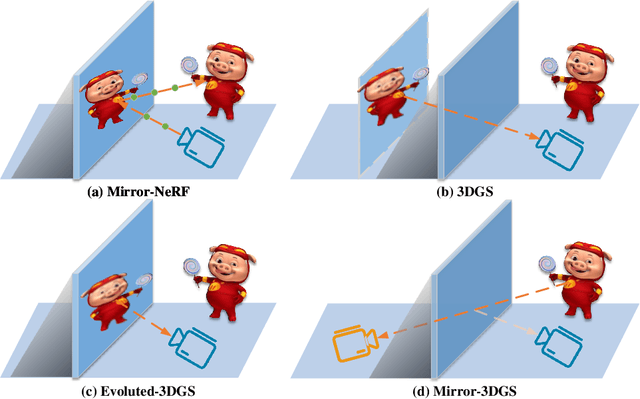
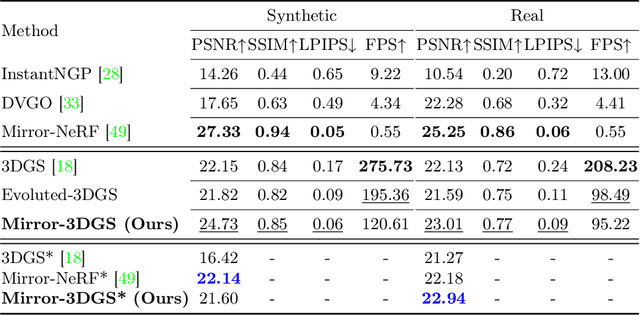
3D Gaussian Splatting (3DGS) has marked a significant breakthrough in the realm of 3D scene reconstruction and novel view synthesis. However, 3DGS, much like its predecessor Neural Radiance Fields (NeRF), struggles to accurately model physical reflections, particularly in mirrors that are ubiquitous in real-world scenes. This oversight mistakenly perceives reflections as separate entities that physically exist, resulting in inaccurate reconstructions and inconsistent reflective properties across varied viewpoints. To address this pivotal challenge, we introduce Mirror-3DGS, an innovative rendering framework devised to master the intricacies of mirror geometries and reflections, paving the way for the generation of realistically depicted mirror reflections. By ingeniously incorporating mirror attributes into the 3DGS and leveraging the principle of plane mirror imaging, Mirror-3DGS crafts a mirrored viewpoint to observe from behind the mirror, enriching the realism of scene renderings. Extensive assessments, spanning both synthetic and real-world scenes, showcase our method's ability to render novel views with enhanced fidelity in real-time, surpassing the state-of-the-art Mirror-NeRF specifically within the challenging mirror regions. Our code will be made publicly available for reproducible research.