 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoloTime: Taming Video Diffusion Models for Panoramic 4D Scene Generation
Apr 30, 2025



The rapid advancement of diffusion models holds the promise of revolutionizing the application of VR and AR technologies, which typically require scene-level 4D assets for user experience. Nonetheless, existing diffusion models predominantly concentrate on modeling static 3D scenes or object-level dynamics, constraining their capacity to provide truly immersive experiences. To address this issue, we propose HoloTime, a framework that integrates video diffusion models to generate panoramic videos from a single prompt or reference image, along with a 360-degree 4D scene reconstruction method that seamlessly transforms the generated panoramic video into 4D assets, enabling a fully immersive 4D experience for users. Specifically, to tame video diffusion models for generating high-fidelity panoramic videos, we introduce the 360World dataset, the first comprehensive collection of panoramic videos suitable for downstream 4D scene reconstruction tasks. With this curated dataset, we propose Panoramic Animator, a two-stage image-to-video diffusion model that can convert panoramic images into high-quality panoramic videos. Following this, we present Panoramic Space-Time Reconstruction, which leverages a space-time depth estimation method to transform the generated panoramic videos into 4D point clouds, enabling the optimization of a holistic 4D Gaussian Splatting representation to reconstruct spatially and temporally consistent 4D scenes. To validate the efficacy of our method, we conducted a comparative analysis with existing approaches, revealing its superiority in both panoramic video generation and 4D scene reconstruction. This demonstrates our method's capability to create more engaging and realistic immersive environments, thereby enhancing user experiences in VR and AR applications.
NeuralGS: Bridging Neural Fields and 3D Gaussian Splatting for Compact 3D Representations
Mar 29, 2025



3D Gaussian Splatting (3DGS) demonstrates superior quality and rendering speed, but with millions of 3D Gaussians and significant storage and transmission costs. Recent 3DGS compression methods mainly concentrate on compressing Scaffold-GS, achieving impressive performance but with an additional voxel structure and a complex encoding and quantization strategy. In this paper, we aim to develop a simple yet effective method called NeuralGS that explores in another way to compress the original 3DGS into a compact representation without the voxel structure and complex quantization strategies. Our observation is that neural fields like NeRF can represent complex 3D scenes with Multi-Layer Perceptron (MLP) neural networks using only a few megabytes. Thus, NeuralGS effectively adopts the neural field representation to encode the attributes of 3D Gaussians with MLPs, only requiring a small storage size even for a large-scale scene. To achieve this, we adopt a clustering strategy and fit the Gaussians with different tiny MLPs for each cluster, based on importance scores of Gaussians as fitting weights. We experiment on multiple datasets, achieving a 45-times average model size reduction without harming the visual quality. The compression performance of our method on original 3DGS is comparable to the dedicated Scaffold-GS-based compression methods, which demonstrate the huge potential of directly compressing original 3DGS with neural fields.
SwapAnyone: Consistent and Realistic Video Synthesis for Swapping Any Person into Any Video
Mar 12, 2025
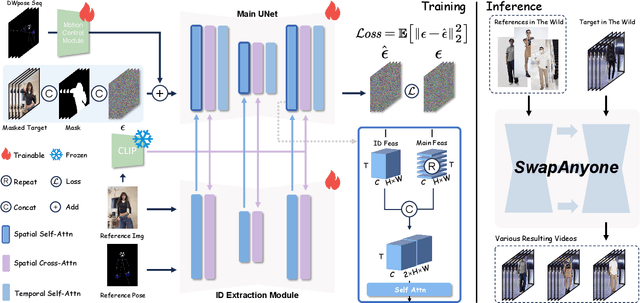
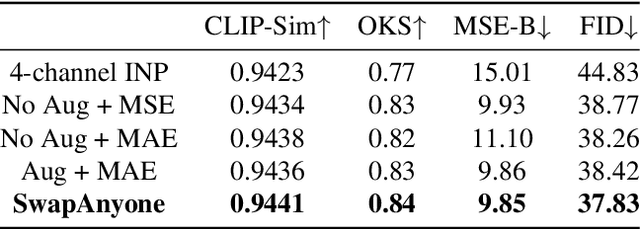

Video body-swapping aims to replace the body in an existing video with a new body from arbitrary sources, which has garnered more attention in recent years. Existing methods treat video body-swapping as a composite of multiple tasks instead of an independent task and typically rely on various models to achieve video body-swapping sequentially. However, these methods fail to achieve end-to-end optimization for the video body-swapping which causes issues such as variations in luminance among frames, disorganized occlusion relationships, and the noticeable separation between bodies and background. In this work, we define video body-swapping as an independent task and propose three critical consistencies: identity consistency, motion consistency, and environment consistency. We introduce an end-to-end model named SwapAnyone, treating video body-swapping as a video inpainting task with reference fidelity and motion control. To improve the ability to maintain environmental harmony, particularly luminance harmony in the resulting video, we introduce a novel EnvHarmony strategy for training our model progressively. Additionally, we provide a dataset named HumanAction-32K covering various videos about human actions. Extensive experiments demonstrate that our method achieves State-Of-The-Art (SOTA) performance among open-source methods while approaching or surpassing closed-source models across multiple dimensions. All code, model weights, and the HumanAction-32K dataset will be open-sourced at https://github.com/PKU-YuanGroup/SwapAnyone.
AE-NeRF: Augmenting Event-Based Neural Radiance Fields for Non-ideal Conditions and Larger Scene
Jan 07, 2025Compared to frame-based methods, computational neuromorphic imaging using event cameras offers significant advantages, such as minimal motion blur, enhanced temporal resolution, and high dynamic range. The multi-view consistency of Neural Radiance Fields combined with the unique benefits of event cameras, has spurred recent research into reconstructing NeRF from data captured by moving event cameras. While showing impressive performance, existing methods rely on ideal conditions with the availability of uniform and high-quality event sequences and accurate camera poses, and mainly focus on the object level reconstruction, thus limiting their practical applications. In this work, we propose AE-NeRF to address the challenges of learning event-based NeRF from non-ideal conditions, including non-uniform event sequences, noisy poses, and various scales of scenes. Our method exploits the density of event streams and jointly learn a pose correction module with an event-based NeRF (e-NeRF) framework for robust 3D reconstruction from inaccurate camera poses. To generalize to larger scenes, we propose hierarchical event distillation with a proposal e-NeRF network and a vanilla e-NeRF network to resample and refine the reconstruction process. We further propose an event reconstruction loss and a temporal loss to improve the view consistency of the reconstructed scene. We established a comprehensive benchmark that includes large-scale scenes to simulate practical non-ideal conditions, incorporating both synthetic and challenging real-world event datasets. The experimental results show that our method achieves a new state-of-the-art in event-based 3D reconstruction.
RoomPainter: View-Integrated Diffusion for Consistent Indoor Scene Texturing
Dec 21, 2024Indoor scene texture synthesis has garnered significant interest due to its important potential applications in virtual reality, digital media, and creative arts. Existing diffusion model-based researches either rely on per-view inpainting techniques, which are plagued by severe cross-view inconsistencies and conspicuous seams, or they resort to optimization-based approaches that entail substantial computational overhead. In this work, we present RoomPainter, a framework that seamlessly integrates efficiency and consistency to achieve high-fidelity texturing of indoor scenes. The core of RoomPainter features a zero-shot technique that effectively adapts a 2D diffusion model for 3D-consistent texture synthesis, along with a two-stage generation strategy that ensures both global and local consistency. Specifically, we introduce Attention-Guided Multi-View Integrated Sampling (MVIS) combined with a neighbor-integrated attention mechanism for zero-shot texture map generation. Using the MVIS, we firstly generate texture map for the entire room to ensure global consistency, then adopt its variant, namely an attention-guided multi-view integrated repaint sampling (MVRS) to repaint individual instances within the room, thereby further enhancing local consistency. Experiments demonstrate that RoomPainter achieves superior performance for indoor scene texture synthesis in visual quality, global consistency, and generation efficiency.
Open-Sora Plan: Open-Source Large Video Generation Model
Nov 28, 2024



We introduce Open-Sora Plan, an open-source project that aims to contribute a large generation model for generating desired high-resolution videos with long durations based on various user inputs. Our project comprises multiple components for the entire video generation process, including a Wavelet-Flow Variational Autoencoder, a Joint Image-Video Skiparse Denoiser, and various condition controllers. Moreover, many assistant strategies for efficient training and inference are designed, and a multi-dimensional data curation pipeline is proposed for obtaining desired high-quality data. Benefiting from efficient thoughts, our Open-Sora Plan achieves impressive video generation results in both qualitative and quantitative evaluations. We hope our careful design and practical experience can inspire the video generation research community. All our codes and model weights are publicly available at \url{https://github.com/PKU-YuanGroup/Open-Sora-Plan}.
WF-VAE: Enhancing Video VAE by Wavelet-Driven Energy Flow for Latent Video Diffusion Model
Nov 26, 2024Video Variational Autoencoder (VAE) encodes videos into a low-dimensional latent space, becoming a key component of most Latent Video Diffusion Models (LVDMs) to reduce model training costs. However, as the resolution and duration of generated videos increase, the encoding cost of Video VAEs becomes a limiting bottleneck in training LVDMs. Moreover, the block-wise inference method adopted by most LVDMs can lead to discontinuities of latent space when processing long-duration videos. The key to addressing the computational bottleneck lies in decomposing videos into distinct components and efficiently encoding the critical information. Wavelet transform can decompose videos into multiple frequency-domain components and improve the efficiency significantly, we thus propose Wavelet Flow VAE (WF-VAE), an autoencoder that leverages multi-level wavelet transform to facilitate low-frequency energy flow into latent representation. Furthermore, we introduce a method called Causal Cache, which maintains the integrity of latent space during block-wise inference. Compared to state-of-the-art video VAEs, WF-VAE demonstrates superior performance in both PSNR and LPIPS metrics, achieving 2x higher throughput and 4x lower memory consumption while maintaining competitive reconstruction quality. Our code and models are available at https://github.com/PKU-YuanGroup/WF-VAE.
Cycle3D: High-quality and Consistent Image-to-3D Generation via Generation-Reconstruction Cycle
Jul 28, 2024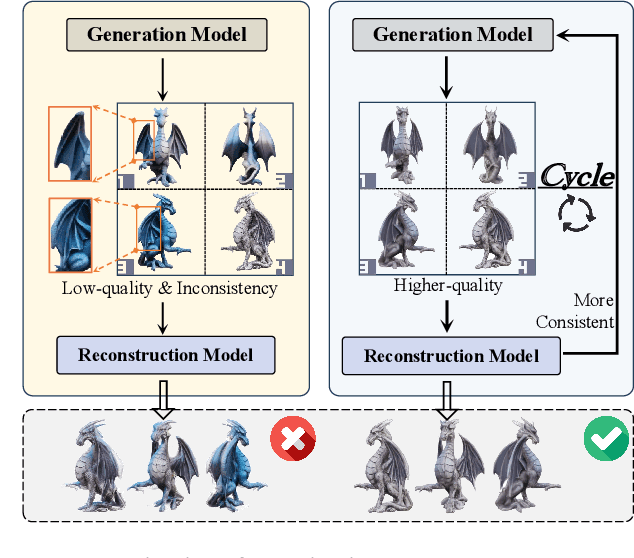
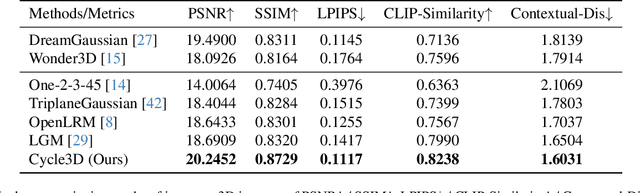
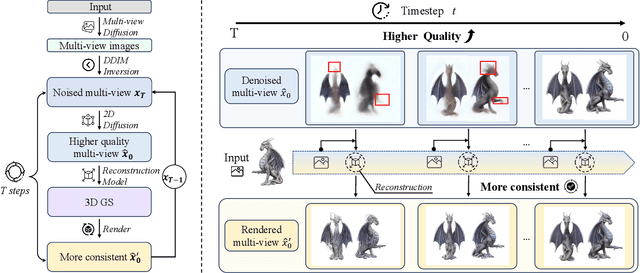
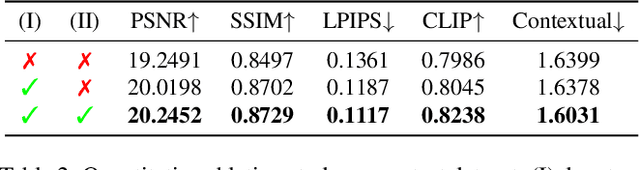
Recent 3D large reconstruction models typically employ a two-stage process, including first generate multi-view images by a multi-view diffusion model, and then utilize a feed-forward model to reconstruct images to 3D content.However, multi-view diffusion models often produce low-quality and inconsistent images, adversely affecting the quality of the final 3D reconstruction. To address this issue, we propose a unified 3D generation framework called Cycle3D, which cyclically utilizes a 2D diffusion-based generation module and a feed-forward 3D reconstruction module during the multi-step diffusion process. Concretely, 2D diffusion model is applied for generating high-quality texture, and the reconstruction model guarantees multi-view consistency.Moreover, 2D diffusion model can further control the generated content and inject reference-view information for unseen views, thereby enhancing the diversity and texture consistency of 3D generation during the denoising process. Extensive experiments demonstrate the superior ability of our method to create 3D content with high-quality and consistency compared with state-of-the-art baselines.
HoloDreamer: Holistic 3D Panoramic World Generation from Text Descriptions
Jul 21, 20243D scene generation is in high demand across various domains, including virtual reality, gaming, and the film industry. Owing to the powerful generative capabilities of text-to-image diffusion models that provide reliable priors, the creation of 3D scenes using only text prompts has become viable, thereby significantly advancing researches in text-driven 3D scene generation. In order to obtain multiple-view supervision from 2D diffusion models, prevailing methods typically employ the diffusion model to generate an initial local image, followed by iteratively outpainting the local image using diffusion models to gradually generate scenes. Nevertheless, these outpainting-based approaches prone to produce global inconsistent scene generation results without high degree of completeness, restricting their broader applications. To tackle these problems, we introduce HoloDreamer, a framework that first generates high-definition panorama as a holistic initialization of the full 3D scene, then leverage 3D Gaussian Splatting (3D-GS) to quickly reconstruct the 3D scene, thereby facilitating the creation of view-consistent and fully enclosed 3D scenes. Specifically, we propose Stylized Equirectangular Panorama Generation, a pipeline that combines multiple diffusion models to enable stylized and detailed equirectangular panorama generation from complex text prompts. Subsequently, Enhanced Two-Stage Panorama Reconstruction is introduced, conducting a two-stage optimization of 3D-GS to inpaint the missing region and enhance the integrity of the scene. Comprehensive experiments demonstrated that our method outperforms prior works in terms of overall visual consistency and harmony as well as reconstruction quality and rendering robustness when generating fully enclosed scenes.
ChronoMagic-Bench: A Benchmark for Metamorphic Evaluation of Text-to-Time-lapse Video Generation
Jun 26, 2024



We propose a novel text-to-video (T2V) generation benchmark, ChronoMagic-Bench, to evaluate the temporal and metamorphic capabilities of the T2V models (e.g. Sora and Lumiere) in time-lapse video generation. In contrast to existing benchmarks that focus on the visual quality and textual relevance of generated videos, ChronoMagic-Bench focuses on the model's ability to generate time-lapse videos with significant metamorphic amplitude and temporal coherence. The benchmark probes T2V models for their physics, biology, and chemistry capabilities, in a free-form text query. For these purposes, ChronoMagic-Bench introduces 1,649 prompts and real-world videos as references, categorized into four major types of time-lapse videos: biological, human-created, meteorological, and physical phenomena, which are further divided into 75 subcategories. This categorization comprehensively evaluates the model's capacity to handle diverse and complex transformations. To accurately align human preference with the benchmark, we introduce two new automatic metrics, MTScore and CHScore, to evaluate the videos' metamorphic attributes and temporal coherence. MTScore measures the metamorphic amplitude, reflecting the degree of change over time, while CHScore assesses the temporal coherence, ensuring the generated videos maintain logical progression and continuity. Based on the ChronoMagic-Bench, we conduct comprehensive manual evaluations of ten representative T2V models, revealing their strengths and weaknesses across different categories of prompts, and providing a thorough evaluation framework that addresses current gaps in video generation research. Moreover, we create a large-scale ChronoMagic-Pro dataset, containing 460k high-quality pairs of 720p time-lapse videos and detailed captions ensuring high physical pertinence and large metamorphic amplitude.