 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-platform Product Matching Based on Entity Alignment of Knowledge Graph with RAEA model
Dec 08, 2025Product matching aims to identify identical or similar products sold on different platforms. By building knowledge graphs (KGs), the product matching problem can be converted to the Entity Alignment (EA) task, which aims to discover the equivalent entities from diverse KGs. The existing EA methods inadequately utilize both attribute triples and relation triples simultaneously, especially the interactions between them. This paper introduces a two-stage pipeline consisting of rough filter and fine filter to match products from eBay and Amazon. For fine filtering, a new framework for Entity Alignment, Relation-aware and Attribute-aware Graph Attention Networks for Entity Alignment (RAEA), is employed. RAEA focuses on the interactions between attribute triples and relation triples, where the entity representation aggregates the alignment signals from attributes and relations with Attribute-aware Entity Encoder and Relation-aware Graph Attention Networks. The experimental results indicate that the RAEA model achieves significant improvements over 12 baselines on EA task in the cross-lingual dataset DBP15K (6.59% on average Hits@1) and delivers competitive results in the monolingual dataset DWY100K. The source code for experiments on DBP15K and DWY100K is available at github (https://github.com/Mockingjay-liu/RAEA-model-for-Entity-Alignment).
* 10 pages, 5 figures, published on World Wide Web
Geometry Forcing: Marrying Video Diffusion and 3D Representation for Consistent World Modeling
Jul 10, 2025Videos inherently represent 2D projections of a dynamic 3D world. However, our analysis suggests that video diffusion models trained solely on raw video data often fail to capture meaningful geometric-aware structure in their learned representations. To bridge this gap between video diffusion models and the underlying 3D nature of the physical world, we propose Geometry Forcing, a simple yet effective method that encourages video diffusion models to internalize latent 3D representations. Our key insight is to guide the model's intermediate representations toward geometry-aware structure by aligning them with features from a pretrained geometric foundation model. To this end, we introduce two complementary alignment objectives: Angular Alignment, which enforces directional consistency via cosine similarity, and Scale Alignment, which preserves scale-related information by regressing unnormalized geometric features from normalized diffusion representation. We evaluate Geometry Forcing on both camera view-conditioned and action-conditioned video generation tasks. Experimental results demonstrate that our method substantially improves visual quality and 3D consistency over the baseline methods. Project page: https://GeometryForcing.github.io.
OpenS2V-Nexus: A Detailed Benchmark and Million-Scale Dataset for Subject-to-Video Generation
May 28, 2025Subject-to-Video (S2V) generation aims to create videos that faithfully incorporate reference content, providing enhanced flexibility in the production of videos. To establish the infrastructure for S2V generation, we propose OpenS2V-Nexus, consisting of (i) OpenS2V-Eval, a fine-grained benchmark, and (ii) OpenS2V-5M, a million-scale dataset. In contrast to existing S2V benchmarks inherited from VBench that focus on global and coarse-grained assessment of generated videos, OpenS2V-Eval focuses on the model's ability to generate subject-consistent videos with natural subject appearance and identity fidelity. For these purposes, OpenS2V-Eval introduces 180 prompts from seven major categories of S2V, which incorporate both real and synthetic test data. Furthermore, to accurately align human preferences with S2V benchmarks, we propose three automatic metrics, NexusScore, NaturalScore and GmeScore, to separately quantify subject consistency, naturalness, and text relevance in generated videos. Building on this, we conduct a comprehensive evaluation of 16 representative S2V models, highlighting their strengths and weaknesses across different content. Moreover, we create the first open-source large-scale S2V generation dataset OpenS2V-5M, which consists of five million high-quality 720P subject-text-video triples. Specifically, we ensure subject-information diversity in our dataset by (1) segmenting subjects and building pairing information via cross-video associations and (2) prompting GPT-Image-1 on raw frames to synthesize multi-view representations. Through OpenS2V-Nexus, we deliver a robust infrastructure to accelerate future S2V generation research.
ImgEdit: A Unified Image Editing Dataset and Benchmark
May 26, 2025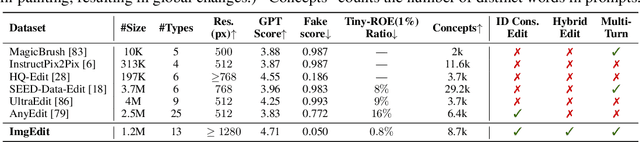
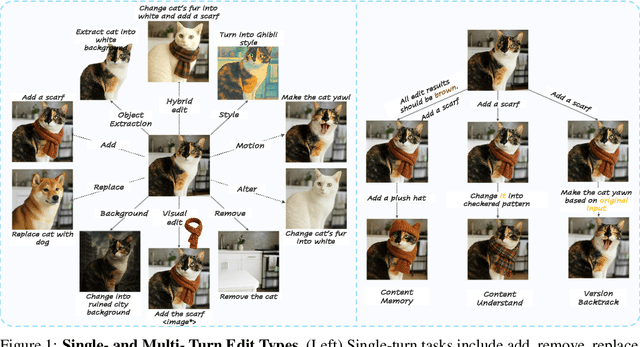
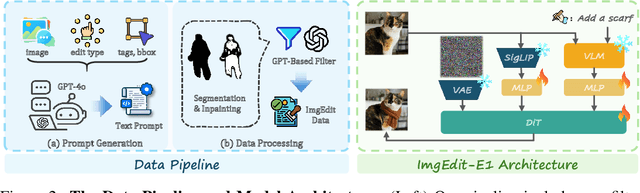

Recent advancements in generative models have enabled high-fidelity text-to-image generation. However, open-source image-editing models still lag behind their proprietary counterparts, primarily due to limited high-quality data and insufficient benchmarks. To overcome these limitations, we introduce ImgEdit, a large-scale, high-quality image-editing dataset comprising 1.2 million carefully curated edit pairs, which contain both novel and complex single-turn edits, as well as challenging multi-turn tasks. To ensure the data quality, we employ a multi-stage pipeline that integrates a cutting-edge vision-language model, a detection model, a segmentation model, alongside task-specific in-painting procedures and strict post-processing. ImgEdit surpasses existing datasets in both task novelty and data quality. Using ImgEdit, we train ImgEdit-E1, an editing model using Vision Language Model to process the reference image and editing prompt, which outperforms existing open-source models on multiple tasks, highlighting the value of ImgEdit and model design. For comprehensive evaluation, we introduce ImgEdit-Bench, a benchmark designed to evaluate image editing performance in terms of instruction adherence, editing quality, and detail preservation. It includes a basic testsuite, a challenging single-turn suite, and a dedicated multi-turn suite. We evaluate both open-source and proprietary models, as well as ImgEdit-E1, providing deep analysis and actionable insights into the current behavior of image-editing models. The source data are publicly available on https://github.com/PKU-YuanGroup/ImgEdit.
Tactile-based Reinforcement Learning for Adaptive Grasping under Observation Uncertainties
May 22, 2025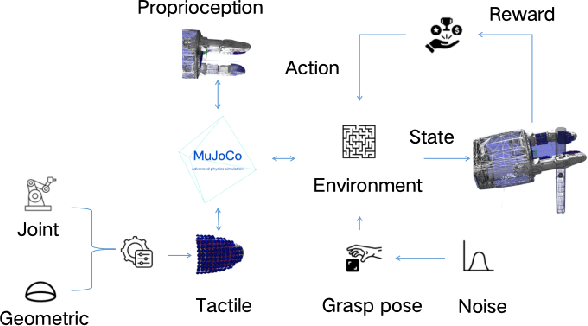

Robotic manipulation in industrial scenarios such as construction commonly faces uncertain observations in which the state of the manipulating object may not be accurately captured due to occlusions and partial observables. For example, object status estimation during pipe assembly, rebar installation, and electrical installation can be impacted by observation errors. Traditional vision-based grasping methods often struggle to ensure robust stability and adaptability. To address this challenge, this paper proposes a tactile simulator that enables a tactile-based adaptive grasping method to enhance grasping robustness. This approach leverages tactile feedback combined with the Proximal Policy Optimization (PPO) reinforcement learning algorithm to dynamically adjust the grasping posture, allowing adaptation to varying grasping conditions under inaccurate object state estimations. Simulation results demonstrate that the proposed method effectively adapts grasping postures, thereby improving the success rate and stability of grasping tasks.
HeteroSpec: Leveraging Contextual Heterogeneity for Efficient Speculative Decoding
May 19, 2025Autoregressive decoding, the standard approach for Large Language Model (LLM) inference, remains a significant bottleneck due to its sequential nature. While speculative decoding algorithms mitigate this inefficiency through parallel verification, they fail to exploit the inherent heterogeneity in linguistic complexity, a key factor leading to suboptimal resource allocation. We address this by proposing HeteroSpec, a heterogeneity-adaptive speculative decoding framework that dynamically optimizes computational resource allocation based on linguistic context complexity. HeteroSpec introduces two key mechanisms: (1) A novel cumulative meta-path Top-$K$ entropy metric for efficiently identifying predictable contexts. (2) A dynamic resource allocation strategy based on data-driven entropy partitioning, enabling adaptive speculative expansion and pruning tailored to local context difficulty. Evaluated on five public benchmarks and four models, HeteroSpec achieves an average speedup of 4.26$\times$. It consistently outperforms state-of-the-art EAGLE-3 across speedup rates, average acceptance length, and verification cost. Notably, HeteroSpec requires no draft model retraining, incurs minimal overhead, and is orthogonal to other acceleration techniques. It demonstrates enhanced acceleration with stronger draft models, establishing a new paradigm for context-aware LLM inference acceleration.
MineWorld: a Real-Time and Open-Source Interactive World Model on Minecraft
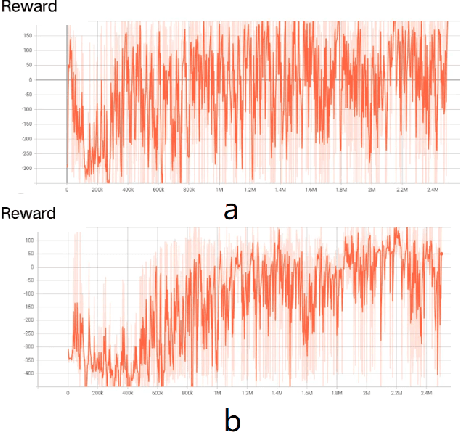
Apr 11, 2025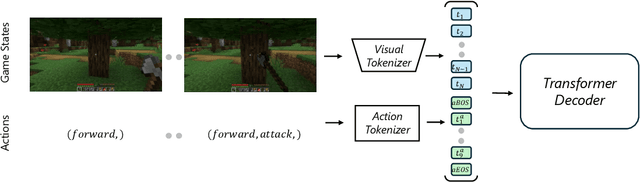

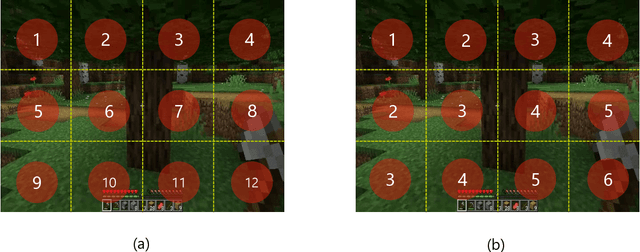
World modeling is a crucial task for enabling intelligent agents to effectively interact with humans and operate in dynamic environments. In this work, we propose MineWorld, a real-time interactive world model on Minecraft, an open-ended sandbox game which has been utilized as a common testbed for world modeling. MineWorld is driven by a visual-action autoregressive Transformer, which takes paired game scenes and corresponding actions as input, and generates consequent new scenes following the actions. Specifically, by transforming visual game scenes and actions into discrete token ids with an image tokenizer and an action tokenizer correspondingly, we consist the model input with the concatenation of the two kinds of ids interleaved. The model is then trained with next token prediction to learn rich representations of game states as well as the conditions between states and actions simultaneously. In inference, we develop a novel parallel decoding algorithm that predicts the spatial redundant tokens in each frame at the same time, letting models in different scales generate $4$ to $7$ frames per second and enabling real-time interactions with game players. In evaluation, we propose new metrics to assess not only visual quality but also the action following capacity when generating new scenes, which is crucial for a world model. Our comprehensive evaluation shows the efficacy of MineWorld, outperforming SoTA open-sourced diffusion based world models significantly. The code and model have been released.
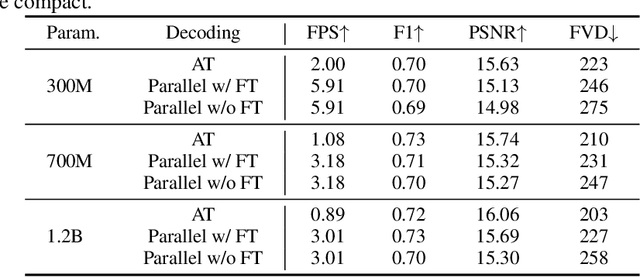
Fast Autoregressive Video Generation with Diagonal Decoding
Mar 18, 2025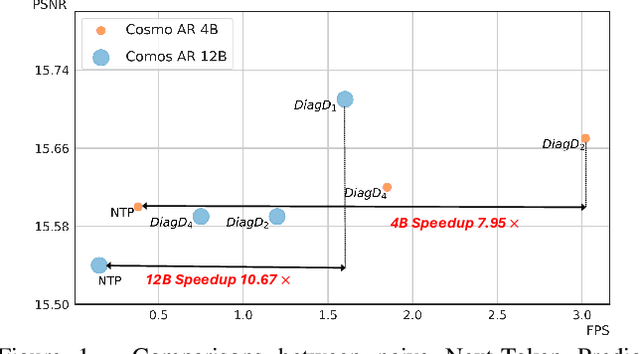
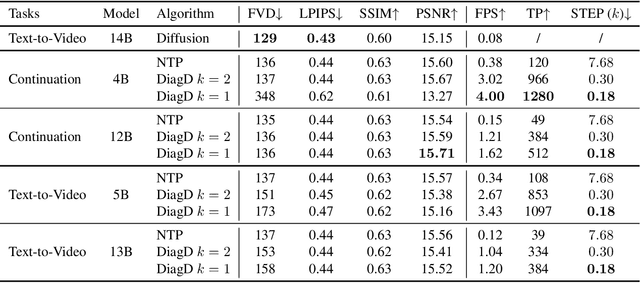
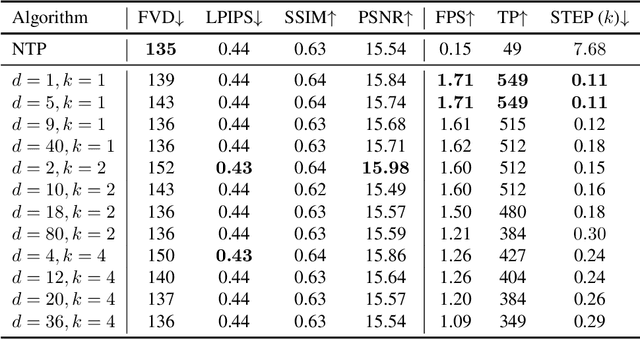
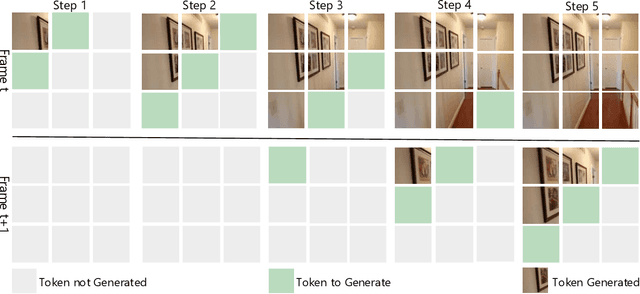
Autoregressive Transformer models have demonstrated impressive performance in video generation, but their sequential token-by-token decoding process poses a major bottleneck, particularly for long videos represented by tens of thousands of tokens. In this paper, we propose Diagonal Decoding (DiagD), a training-free inference acceleration algorithm for autoregressively pre-trained models that exploits spatial and temporal correlations in videos. Our method generates tokens along diagonal paths in the spatial-temporal token grid, enabling parallel decoding within each frame as well as partially overlapping across consecutive frames. The proposed algorithm is versatile and adaptive to various generative models and tasks, while providing flexible control over the trade-off between inference speed and visual quality. Furthermore, we propose a cost-effective finetuning strategy that aligns the attention patterns of the model with our decoding order, further mitigating the training-inference gap on small-scale models. Experiments on multiple autoregressive video generation models and datasets demonstrate that DiagD achieves up to $10\times$ speedup compared to naive sequential decoding, while maintaining comparable visual fidelity.
Force-Based Robotic Imitation Learning: A Two-Phase Approach for Construction Assembly Tasks
Jan 24, 2025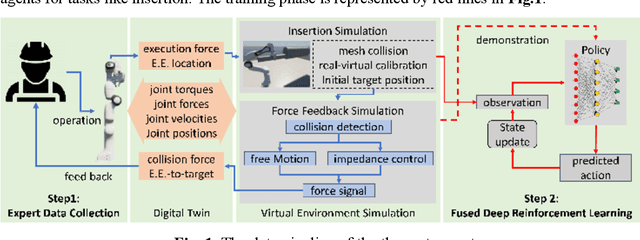
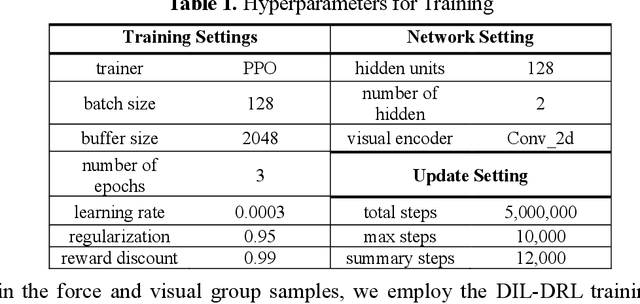
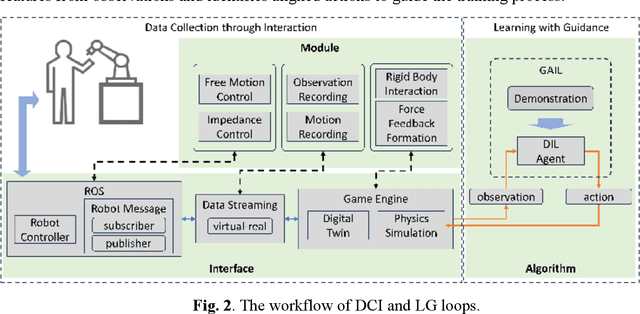

The drive for efficiency and safety in construction has boosted the role of robotics and automation. However, complex tasks like welding and pipe insertion pose challenges due to their need for precise adaptive force control, which complicates robotic training. This paper proposes a two-phase system to improve robot learning, integrating human-derived force feedback. The first phase captures real-time data from operators using a robot arm linked with a virtual simulator via ROS-Sharp. In the second phase, this feedback is converted into robotic motion instructions, using a generative approach to incorporate force feedback into the learning process. This method's effectiveness is demonstrated through improved task completion times and success rates. The framework simulates realistic force-based interactions, enhancing the training data's quality for precise robotic manipulation in construction tasks.
Open-Sora Plan: Open-Source Large Video Generation Model
Nov 28, 2024



We introduce Open-Sora Plan, an open-source project that aims to contribute a large generation model for generating desired high-resolution videos with long durations based on various user inputs. Our project comprises multiple components for the entire video generation process, including a Wavelet-Flow Variational Autoencoder, a Joint Image-Video Skiparse Denoiser, and various condition controllers. Moreover, many assistant strategies for efficient training and inference are designed, and a multi-dimensional data curation pipeline is proposed for obtaining desired high-quality data. Benefiting from efficient thoughts, our Open-Sora Plan achieves impressive video generation results in both qualitative and quantitative evaluations. We hope our careful design and practical experience can inspire the video generation research community. All our codes and model weights are publicly available at \url{https://github.com/PKU-YuanGroup/Open-Sora-Plan}.