 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltraShape 1.0: High-Fidelity 3D Shape Generation via Scalable Geometric Refinement
Dec 24, 2025In this report, we introduce UltraShape 1.0, a scalable 3D diffusion framework for high-fidelity 3D geometry generation. The proposed approach adopts a two-stage generation pipeline: a coarse global structure is first synthesized and then refined to produce detailed, high-quality geometry. To support reliable 3D generation, we develop a comprehensive data processing pipeline that includes a novel watertight processing method and high-quality data filtering. This pipeline improves the geometric quality of publicly available 3D datasets by removing low-quality samples, filling holes, and thickening thin structures, while preserving fine-grained geometric details. To enable fine-grained geometry refinement, we decouple spatial localization from geometric detail synthesis in the diffusion process. We achieve this by performing voxel-based refinement at fixed spatial locations, where voxel queries derived from coarse geometry provide explicit positional anchors encoded via RoPE, allowing the diffusion model to focus on synthesizing local geometric details within a reduced, structured solution space. Our model is trained exclusively on publicly available 3D datasets, achieving strong geometric quality despite limited training resources. Extensive evaluations demonstrate that UltraShape 1.0 performs competitively with existing open-source methods in both data processing quality and geometry generation. All code and trained models will be released to support future research.
OpenS2V-Nexus: A Detailed Benchmark and Million-Scale Dataset for Subject-to-Video Generation
May 28, 2025Subject-to-Video (S2V) generation aims to create videos that faithfully incorporate reference content, providing enhanced flexibility in the production of videos. To establish the infrastructure for S2V generation, we propose OpenS2V-Nexus, consisting of (i) OpenS2V-Eval, a fine-grained benchmark, and (ii) OpenS2V-5M, a million-scale dataset. In contrast to existing S2V benchmarks inherited from VBench that focus on global and coarse-grained assessment of generated videos, OpenS2V-Eval focuses on the model's ability to generate subject-consistent videos with natural subject appearance and identity fidelity. For these purposes, OpenS2V-Eval introduces 180 prompts from seven major categories of S2V, which incorporate both real and synthetic test data. Furthermore, to accurately align human preferences with S2V benchmarks, we propose three automatic metrics, NexusScore, NaturalScore and GmeScore, to separately quantify subject consistency, naturalness, and text relevance in generated videos. Building on this, we conduct a comprehensive evaluation of 16 representative S2V models, highlighting their strengths and weaknesses across different content. Moreover, we create the first open-source large-scale S2V generation dataset OpenS2V-5M, which consists of five million high-quality 720P subject-text-video triples. Specifically, we ensure subject-information diversity in our dataset by (1) segmenting subjects and building pairing information via cross-video associations and (2) prompting GPT-Image-1 on raw frames to synthesize multi-view representations. Through OpenS2V-Nexus, we deliver a robust infrastructure to accelerate future S2V generation research.
Sci-Fi: Symmetric Constraint for Frame Inbetweening
May 27, 2025



Frame inbetweening aims to synthesize intermediate video sequences conditioned on the given start and end frames. Current state-of-the-art methods mainly extend large-scale pre-trained Image-to-Video Diffusion models (I2V-DMs) by incorporating end-frame constraints via directly fine-tuning or omitting training. We identify a critical limitation in their design: Their injections of the end-frame constraint usually utilize the same mechanism that originally imposed the start-frame (single image) constraint. However, since the original I2V-DMs are adequately trained for the start-frame condition in advance, naively introducing the end-frame constraint by the same mechanism with much less (even zero) specialized training probably can't make the end frame have a strong enough impact on the intermediate content like the start frame. This asymmetric control strength of the two frames over the intermediate content likely leads to inconsistent motion or appearance collapse in generated frames. To efficiently achieve symmetric constraints of start and end frames, we propose a novel framework, termed Sci-Fi, which applies a stronger injection for the constraint of a smaller training scale. Specifically, it deals with the start-frame constraint as before, while introducing the end-frame constraint by an improved mechanism. The new mechanism is based on a well-designed lightweight module, named EF-Net, which encodes only the end frame and expands it into temporally adaptive frame-wise features injected into the I2V-DM. This makes the end-frame constraint as strong as the start-frame constraint, enabling our Sci-Fi to produce more harmonious transitions in various scenarios. Extensive experiments prove the superiority of our Sci-Fi compared with other baselines.
ImgEdit: A Unified Image Editing Dataset and Benchmark
May 26, 2025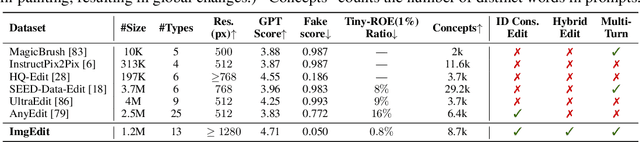
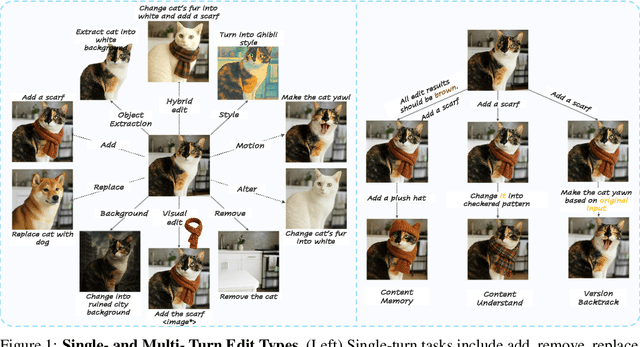
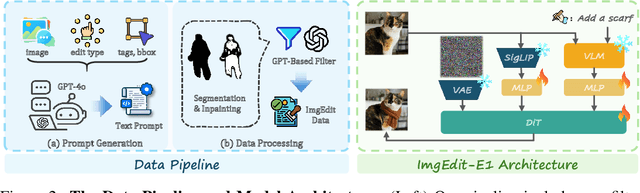

Recent advancements in generative models have enabled high-fidelity text-to-image generation. However, open-source image-editing models still lag behind their proprietary counterparts, primarily due to limited high-quality data and insufficient benchmarks. To overcome these limitations, we introduce ImgEdit, a large-scale, high-quality image-editing dataset comprising 1.2 million carefully curated edit pairs, which contain both novel and complex single-turn edits, as well as challenging multi-turn tasks. To ensure the data quality, we employ a multi-stage pipeline that integrates a cutting-edge vision-language model, a detection model, a segmentation model, alongside task-specific in-painting procedures and strict post-processing. ImgEdit surpasses existing datasets in both task novelty and data quality. Using ImgEdit, we train ImgEdit-E1, an editing model using Vision Language Model to process the reference image and editing prompt, which outperforms existing open-source models on multiple tasks, highlighting the value of ImgEdit and model design. For comprehensive evaluation, we introduce ImgEdit-Bench, a benchmark designed to evaluate image editing performance in terms of instruction adherence, editing quality, and detail preservation. It includes a basic testsuite, a challenging single-turn suite, and a dedicated multi-turn suite. We evaluate both open-source and proprietary models, as well as ImgEdit-E1, providing deep analysis and actionable insights into the current behavior of image-editing models. The source data are publicly available on https://github.com/PKU-YuanGroup/ImgEdit.
Open-Sora Plan: Open-Source Large Video Generation Model
Nov 28, 2024



We introduce Open-Sora Plan, an open-source project that aims to contribute a large generation model for generating desired high-resolution videos with long durations based on various user inputs. Our project comprises multiple components for the entire video generation process, including a Wavelet-Flow Variational Autoencoder, a Joint Image-Video Skiparse Denoiser, and various condition controllers. Moreover, many assistant strategies for efficient training and inference are designed, and a multi-dimensional data curation pipeline is proposed for obtaining desired high-quality data. Benefiting from efficient thoughts, our Open-Sora Plan achieves impressive video generation results in both qualitative and quantitative evaluations. We hope our careful design and practical experience can inspire the video generation research community. All our codes and model weights are publicly available at \url{https://github.com/PKU-YuanGroup/Open-Sora-Plan}.
Identity-Preserving Text-to-Video Generation by Frequency Decomposition
Nov 26, 2024
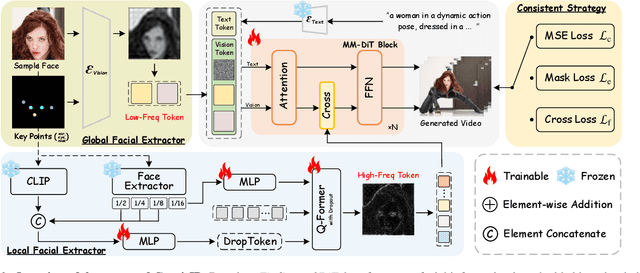
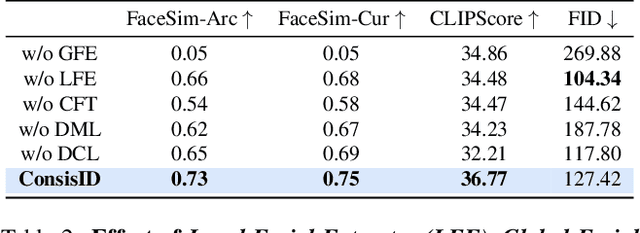
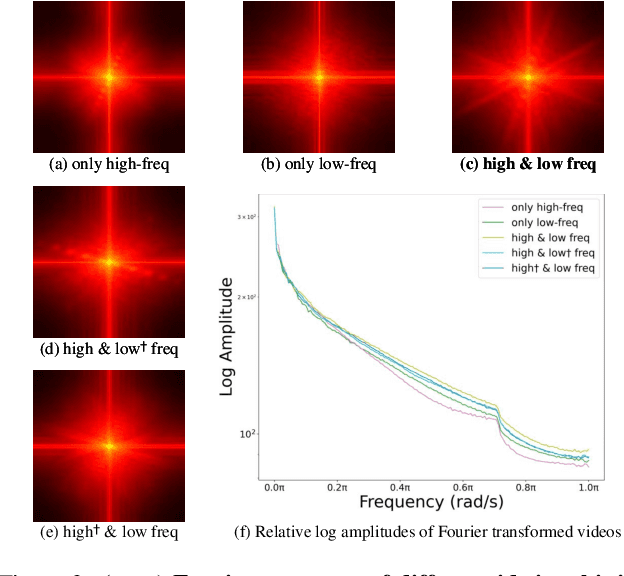
Identity-preserving text-to-video (IPT2V) generation aims to create high-fidelity videos with consistent human identity. It is an important task in video generation but remains an open problem for generative models. This paper pushes the technical frontier of IPT2V in two directions that have not been resolved in literature: (1) A tuning-free pipeline without tedious case-by-case finetuning, and (2) A frequency-aware heuristic identity-preserving DiT-based control scheme. We propose ConsisID, a tuning-free DiT-based controllable IPT2V model to keep human identity consistent in the generated video. Inspired by prior findings in frequency analysis of diffusion transformers, it employs identity-control signals in the frequency domain, where facial features can be decomposed into low-frequency global features and high-frequency intrinsic features. First, from a low-frequency perspective, we introduce a global facial extractor, which encodes reference images and facial key points into a latent space, generating features enriched with low-frequency information. These features are then integrated into shallow layers of the network to alleviate training challenges associated with DiT. Second, from a high-frequency perspective, we design a local facial extractor to capture high-frequency details and inject them into transformer blocks, enhancing the model's ability to preserve fine-grained features. We propose a hierarchical training strategy to leverage frequency information for identity preservation, transforming a vanilla pre-trained video generation model into an IPT2V model. Extensive experiments demonstrate that our frequency-aware heuristic scheme provides an optimal control solution for DiT-based models. Thanks to this scheme, our ConsisID generates high-quality, identity-preserving videos, making strides towards more effective IPT2V.