 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecEyes: Accelerating Agentic Multimodal LLMs via Speculative Perception and Planning
Mar 24, 2026Agentic multimodal large language models (MLLMs) (e.g., OpenAI o3 and Gemini Agentic Vision) achieve remarkable reasoning capabilities through iterative visual tool invocation. However, the cascaded perception, reasoning, and tool-calling loops introduce significant sequential overhead. This overhead, termed agentic depth, incurs prohibitive latency and seriously limits system-level concurrency. To this end, we propose SpecEyes, an agentic-level speculative acceleration framework that breaks this sequential bottleneck. Our key insight is that a lightweight, tool-free MLLM can serve as a speculative planner to predict the execution trajectory, enabling early termination of expensive tool chains without sacrificing accuracy. To regulate this speculative planning, we introduce a cognitive gating mechanism based on answer separability, which quantifies the model's confidence for self-verification without requiring oracle labels. Furthermore, we design a heterogeneous parallel funnel that exploits the stateless concurrency of the small model to mask the stateful serial execution of the large model, maximizing system throughput. Extensive experiments on V* Bench, HR-Bench, and POPE demonstrate that SpecEyes achieves 1.1-3.35x speedup over the agentic baseline while preserving or even improving accuracy (up to +6.7%), thereby boosting serving throughput under concurrent workloads.
SocialOmni: Benchmarking Audio-Visual Social Interactivity in Omni Models
Mar 17, 2026Omni-modal large language models (OLMs) redefine human-machine interaction by natively integrating audio, vision, and text. However, existing OLM benchmarks remain anchored to static, accuracy-centric tasks, leaving a critical gap in assessing social interactivity, the fundamental capacity to navigate dynamic cues in natural dialogues. To this end, we propose SocialOmni, a comprehensive benchmark that operationalizes the evaluation of this conversational interactivity across three core dimensions: (i) speaker separation and identification (who is speaking), (ii) interruption timing control (when to interject), and (iii) natural interruption generation (how to phrase the interruption). SocialOmni features 2,000 perception samples and a quality-controlled diagnostic set of 209 interaction-generation instances with strict temporal and contextual constraints, complemented by controlled audio-visual inconsistency scenarios to test model robustness. We benchmarked 12 leading OLMs, which uncovers significant variance in their social-interaction capabilities across models. Furthermore, our analysis reveals a pronounced decoupling between a model's perceptual accuracy and its ability to generate contextually appropriate interruptions, indicating that understanding-centric metrics alone are insufficient to characterize conversational social competence. More encouragingly, these diagnostics from SocialOmni yield actionable signals for bridging the perception-interaction divide in future OLMs.
A Survey on Latent Reasoning
Jul 08, 2025



Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, especially when guided by explicit chain-of-thought (CoT) reasoning that verbalizes intermediate steps. While CoT improves both interpretability and accuracy, its dependence on natural language reasoning limits the model's expressive bandwidth. Latent reasoning tackles this bottleneck by performing multi-step inference entirely in the model's continuous hidden state, eliminating token-level supervision. To advance latent reasoning research, this survey provides a comprehensive overview of the emerging field of latent reasoning. We begin by examining the foundational role of neural network layers as the computational substrate for reasoning, highlighting how hierarchical representations support complex transformations. Next, we explore diverse latent reasoning methodologies, including activation-based recurrence, hidden state propagation, and fine-tuning strategies that compress or internalize explicit reasoning traces. Finally, we discuss advanced paradigms such as infinite-depth latent reasoning via masked diffusion models, which enable globally consistent and reversible reasoning processes. By unifying these perspectives, we aim to clarify the conceptual landscape of latent reasoning and chart future directions for research at the frontier of LLM cognition. An associated GitHub repository collecting the latest papers and repos is available at: https://github.com/multimodal-art-projection/LatentCoT-Horizon/.
LeanPO: Lean Preference Optimization for Likelihood Alignment in Video-LLMs
Jun 05, 2025Most Video Large Language Models (Video-LLMs) adopt preference alignment techniques, e.g., DPO~\citep{rafailov2024dpo}, to optimize the reward margin between a winning response ($y_w$) and a losing response ($y_l$). However, the likelihood displacement observed in DPO indicates that both $\log \pi_\theta (y_w\mid x)$ and $\log \pi_\theta (y_l\mid x) $ often decrease during training, inadvertently boosting the probabilities of non-target responses. In this paper, we systematically revisit this phenomenon from LLMs to Video-LLMs, showing that it intensifies when dealing with the redundant complexity of video content. To alleviate the impact of this phenomenon, we propose \emph{Lean Preference Optimization} (LeanPO), a reference-free approach that reformulates the implicit reward as the average likelihood of the response with respect to the policy model. A key component of LeanPO is the reward-trustworthiness correlated self-generated preference data pipeline, which carefully infuses relevant prior knowledge into the model while continuously refining the preference data via self-reflection. This allows the policy model to obtain high-quality paired data and accurately estimate the newly defined reward, thus mitigating the unintended drop. In addition, we introduce a dynamic label smoothing strategy that mitigates the impact of noise in responses from diverse video content, preventing the model from overfitting to spurious details. Extensive experiments demonstrate that LeanPO significantly enhances the performance of state-of-the-art Video-LLMs, consistently boosting baselines of varying capacities with minimal additional training overhead. Moreover, LeanPO offers a simple yet effective solution for aligning Video-LLM preferences with human trustworthiness, paving the way toward the reliable and efficient Video-LLMs.
OpenS2V-Nexus: A Detailed Benchmark and Million-Scale Dataset for Subject-to-Video Generation
May 28, 2025Subject-to-Video (S2V) generation aims to create videos that faithfully incorporate reference content, providing enhanced flexibility in the production of videos. To establish the infrastructure for S2V generation, we propose OpenS2V-Nexus, consisting of (i) OpenS2V-Eval, a fine-grained benchmark, and (ii) OpenS2V-5M, a million-scale dataset. In contrast to existing S2V benchmarks inherited from VBench that focus on global and coarse-grained assessment of generated videos, OpenS2V-Eval focuses on the model's ability to generate subject-consistent videos with natural subject appearance and identity fidelity. For these purposes, OpenS2V-Eval introduces 180 prompts from seven major categories of S2V, which incorporate both real and synthetic test data. Furthermore, to accurately align human preferences with S2V benchmarks, we propose three automatic metrics, NexusScore, NaturalScore and GmeScore, to separately quantify subject consistency, naturalness, and text relevance in generated videos. Building on this, we conduct a comprehensive evaluation of 16 representative S2V models, highlighting their strengths and weaknesses across different content. Moreover, we create the first open-source large-scale S2V generation dataset OpenS2V-5M, which consists of five million high-quality 720P subject-text-video triples. Specifically, we ensure subject-information diversity in our dataset by (1) segmenting subjects and building pairing information via cross-video associations and (2) prompting GPT-Image-1 on raw frames to synthesize multi-view representations. Through OpenS2V-Nexus, we deliver a robust infrastructure to accelerate future S2V generation research.
TACO: Enhancing Multimodal In-context Learning via Task Mapping-Guided Sequence Configuration
May 21, 2025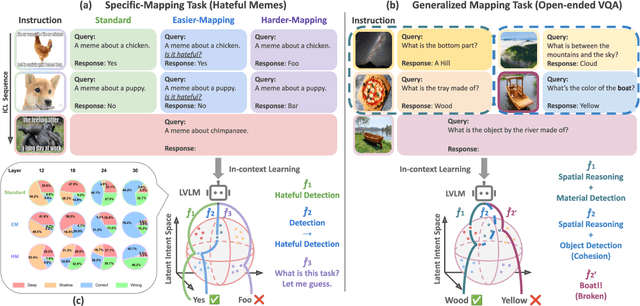
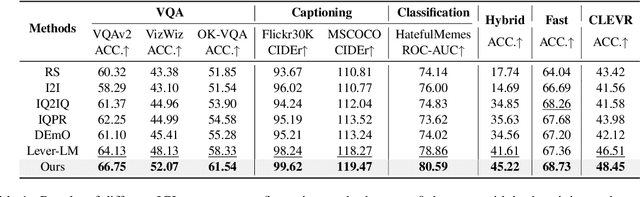
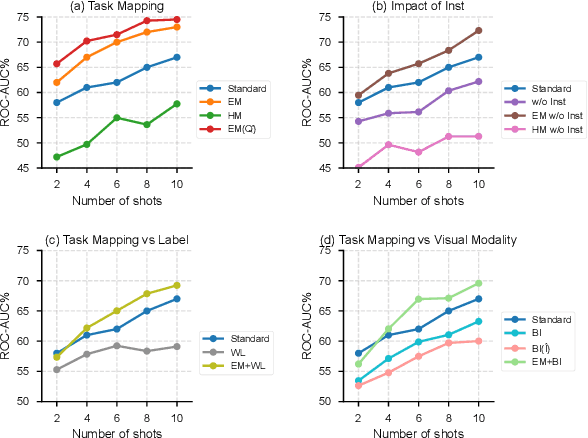
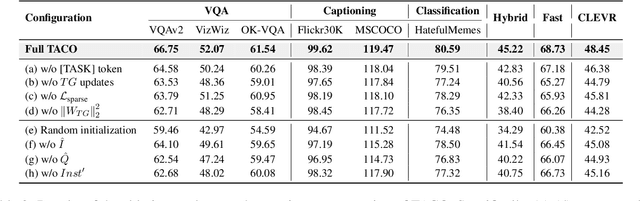
Multimodal in-context learning (ICL) has emerged as a key mechanism for harnessing the capabilities of large vision-language models (LVLMs). However, its effectiveness remains highly sensitive to the quality of input in-context sequences, particularly for tasks involving complex reasoning or open-ended generation. A major limitation is our limited understanding of how LVLMs actually exploit these sequences during inference. To bridge this gap, we systematically interpret multimodal ICL through the lens of task mapping, which reveals how local and global relationships within and among demonstrations guide model reasoning. Building on this insight, we present TACO, a lightweight transformer-based model equipped with task-aware attention that dynamically configures in-context sequences. By injecting task-mapping signals into the autoregressive decoding process, TACO creates a bidirectional synergy between sequence construction and task reasoning. Experiments on five LVLMs and nine datasets demonstrate that TACO consistently surpasses baselines across diverse ICL tasks. These results position task mapping as a valuable perspective for interpreting and improving multimodal ICL.
QuoTA: Query-oriented Token Assignment via CoT Query Decouple for Long Video Comprehension
Mar 11, 2025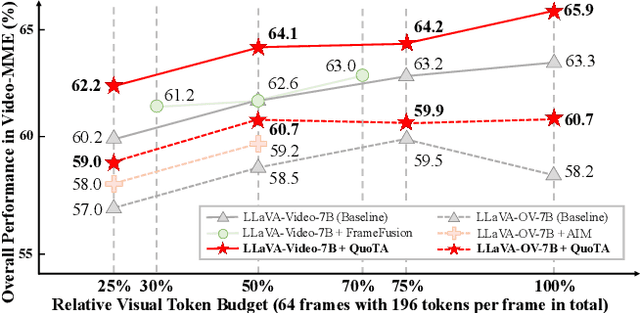
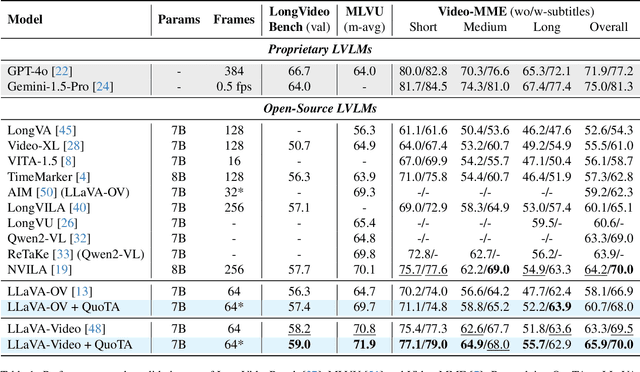
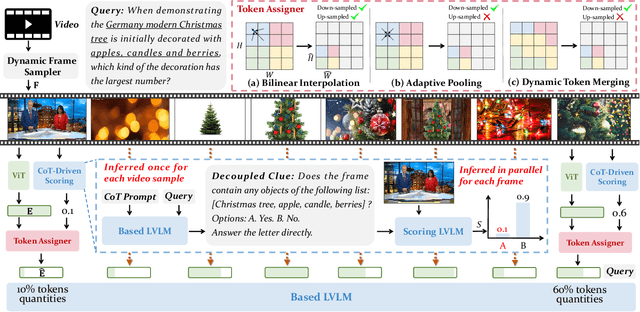
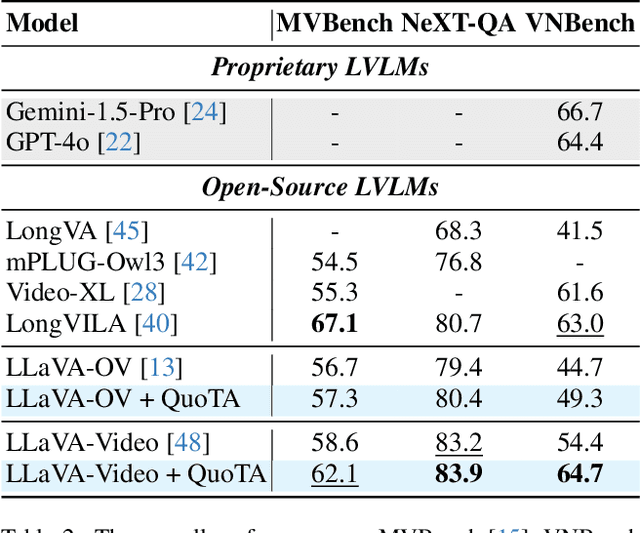
Recent advances in long video understanding typically mitigate visual redundancy through visual token pruning based on attention distribution. However, while existing methods employ post-hoc low-response token pruning in decoder layers, they overlook the input-level semantic correlation between visual tokens and instructions (query). In this paper, we propose QuoTA, an ante-hoc training-free modular that extends existing large video-language models (LVLMs) for visual token assignment based on query-oriented frame-level importance assessment. The query-oriented token selection is crucial as it aligns visual processing with task-specific requirements, optimizing token budget utilization while preserving semantically relevant content. Specifically, (i) QuoTA strategically allocates frame-level importance scores based on query relevance, enabling one-time visual token assignment before cross-modal interactions in decoder layers, (ii) we decouple the query through Chain-of-Thoughts reasoning to facilitate more precise LVLM-based frame importance scoring, and (iii) QuoTA offers a plug-and-play functionality that extends to existing LVLMs. Extensive experimental results demonstrate that implementing QuoTA with LLaVA-Video-7B yields an average performance improvement of 3.2% across six benchmarks (including Video-MME and MLVU) while operating within an identical visual token budget as the baseline. Codes are open-sourced at https://github.com/MAC-AutoML/QuoTA.
Identity-Preserving Text-to-Video Generation by Frequency Decomposition
Nov 26, 2024
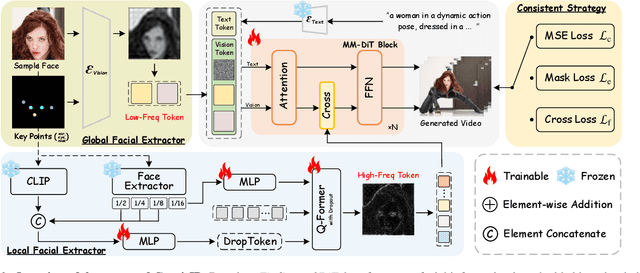
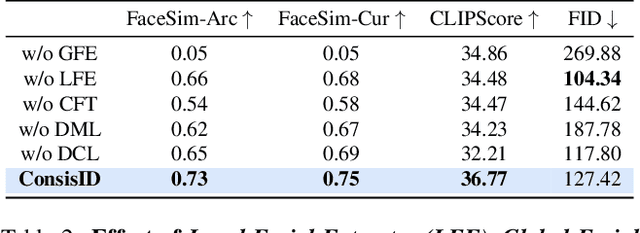
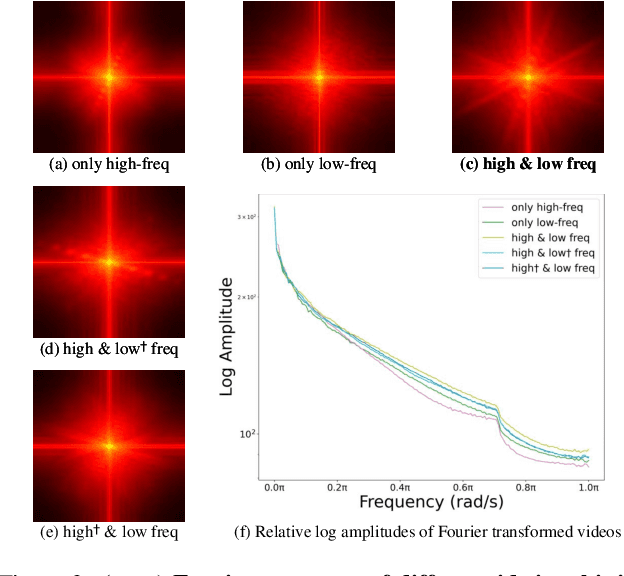
Identity-preserving text-to-video (IPT2V) generation aims to create high-fidelity videos with consistent human identity. It is an important task in video generation but remains an open problem for generative models. This paper pushes the technical frontier of IPT2V in two directions that have not been resolved in literature: (1) A tuning-free pipeline without tedious case-by-case finetuning, and (2) A frequency-aware heuristic identity-preserving DiT-based control scheme. We propose ConsisID, a tuning-free DiT-based controllable IPT2V model to keep human identity consistent in the generated video. Inspired by prior findings in frequency analysis of diffusion transformers, it employs identity-control signals in the frequency domain, where facial features can be decomposed into low-frequency global features and high-frequency intrinsic features. First, from a low-frequency perspective, we introduce a global facial extractor, which encodes reference images and facial key points into a latent space, generating features enriched with low-frequency information. These features are then integrated into shallow layers of the network to alleviate training challenges associated with DiT. Second, from a high-frequency perspective, we design a local facial extractor to capture high-frequency details and inject them into transformer blocks, enhancing the model's ability to preserve fine-grained features. We propose a hierarchical training strategy to leverage frequency information for identity preservation, transforming a vanilla pre-trained video generation model into an IPT2V model. Extensive experiments demonstrate that our frequency-aware heuristic scheme provides an optimal control solution for DiT-based models. Thanks to this scheme, our ConsisID generates high-quality, identity-preserving videos, making strides towards more effective IPT2V.
Video-RAG: Visually-aligned Retrieval-Augmented Long Video Comprehension
Nov 20, 2024


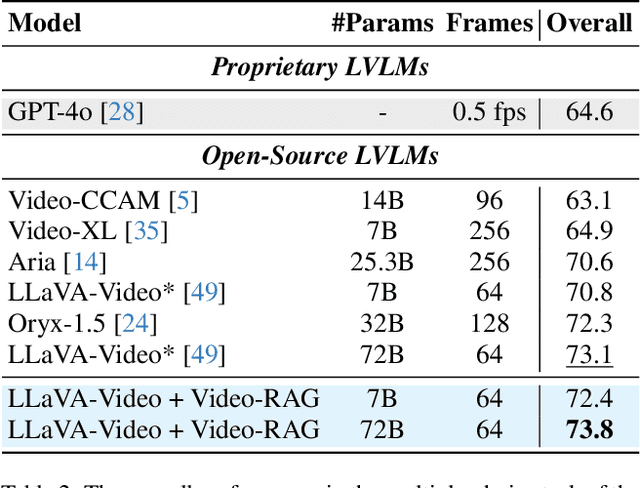
Existing large video-language models (LVLMs) struggle to comprehend long videos correctly due to limited context. To address this problem, fine-tuning long-context LVLMs and employing GPT-based agents have emerged as promising solutions. However, fine-tuning LVLMs would require extensive high-quality data and substantial GPU resources, while GPT-based agents would rely on proprietary models (e.g., GPT-4o). In this paper, we propose Video Retrieval-Augmented Generation (Video-RAG), a training-free and cost-effective pipeline that employs visually-aligned auxiliary texts to help facilitate cross-modality alignment while providing additional information beyond the visual content. Specifically, we leverage open-source external tools to extract visually-aligned information from pure video data (e.g., audio, optical character, and object detection), and incorporate the extracted information into an existing LVLM as auxiliary texts, alongside video frames and queries, in a plug-and-play manner. Our Video-RAG offers several key advantages: (i) lightweight with low computing overhead due to single-turn retrieval; (ii) easy implementation and compatibility with any LVLM; and (iii) significant, consistent performance gains across long video understanding benchmarks, including Video-MME, MLVU, and LongVideoBench. Notably, our model demonstrates superior performance over proprietary models like Gemini-1.5-Pro and GPT-4o when utilized with a 72B model.
Autoregressive Models in Vision: A Survey
Nov 08, 2024
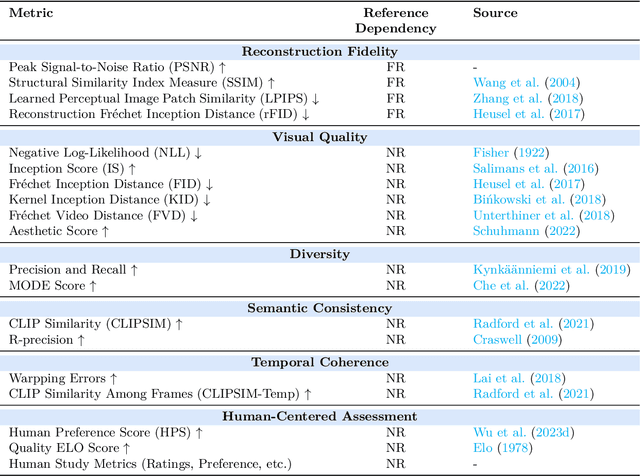

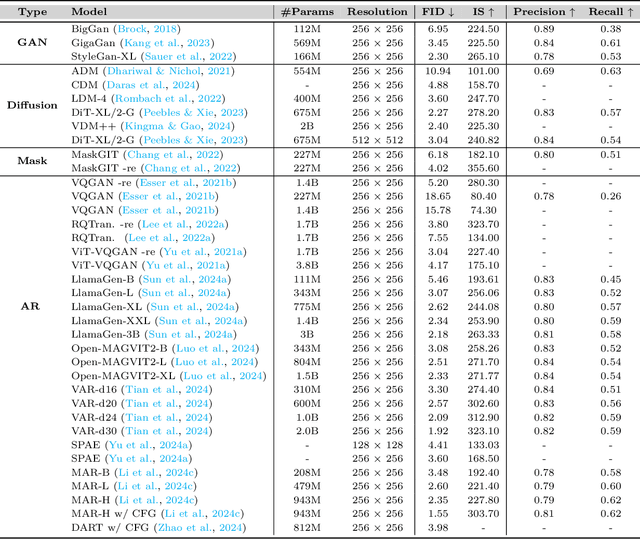
Autoregressive modeling has been a huge success in the field of natural language processing (NLP). Recently, autoregressive models have emerged as a significant area of focus in computer vision, where they excel in producing high-quality visual content. Autoregressive models in NLP typically operate on subword tokens. However, the representation strategy in computer vision can vary in different levels, \textit{i.e.}, pixel-level, token-level, or scale-level, reflecting the diverse and hierarchical nature of visual data compared to the sequential structure of language. This survey comprehensively examines the literature on autoregressive models applied to vision. To improve readability for researchers from diverse research backgrounds, we start with preliminary sequence representation and modeling in vision. Next, we divide the fundamental frameworks of visual autoregressive models into three general sub-categories, including pixel-based, token-based, and scale-based models based on the strategy of representation. We then explore the interconnections between autoregressive models and other generative models. Furthermore, we present a multi-faceted categorization of autoregressive models in computer vision, including image generation, video generation, 3D generation, and multi-modal generation. We also elaborate on their applications in diverse domains, including emerging domains such as embodied AI and 3D medical AI, with about 250 related references. Finally, we highlight the current challenges to autoregressive models in vision with suggestions about potential research directions. We have also set up a Github repository to organize the papers included in this survey at: \url{https://github.com/ChaofanTao/Autoregressive-Models-in-Vision-Survey}.