 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRPO-Guard: Mitigating Implicit Over-Optimization in Flow Matching via Regulated Clipping
Oct 25, 2025Recently, GRPO-based reinforcement learning has shown remarkable progress in optimizing flow-matching models, effectively improving their alignment with task-specific rewards. Within these frameworks, the policy update relies on importance-ratio clipping to constrain overconfident positive and negative gradients. However, in practice, we observe a systematic shift in the importance-ratio distribution-its mean falls below 1 and its variance differs substantially across timesteps. This left-shifted and inconsistent distribution prevents positive-advantage samples from entering the clipped region, causing the mechanism to fail in constraining overconfident positive updates. As a result, the policy model inevitably enters an implicit over-optimization stage-while the proxy reward continues to increase, essential metrics such as image quality and text-prompt alignment deteriorate sharply, ultimately making the learned policy impractical for real-world use. To address this issue, we introduce GRPO-Guard, a simple yet effective enhancement to existing GRPO frameworks. Our method incorporates ratio normalization, which restores a balanced and step-consistent importance ratio, ensuring that PPO clipping properly constrains harmful updates across denoising timesteps. In addition, a gradient reweighting strategy equalizes policy gradients over noise conditions, preventing excessive updates from particular timestep regions. Together, these designs act as a regulated clipping mechanism, stabilizing optimization and substantially mitigating implicit over-optimization without relying on heavy KL regularization. Extensive experiments on multiple diffusion backbones (e.g., SD3.5M, Flux.1-dev) and diverse proxy tasks demonstrate that GRPO-Guard significantly reduces over-optimization while maintaining or even improving generation quality.
Flow-GRPO: Training Flow Matching Models via Online RL
May 08, 2025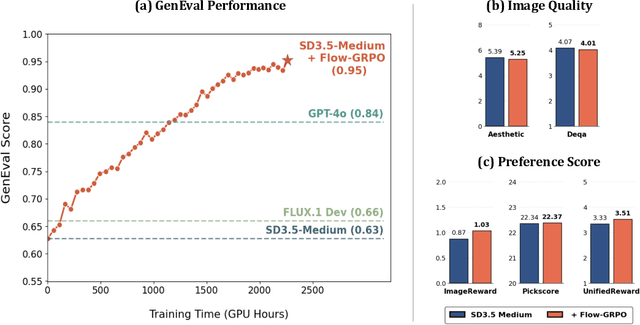
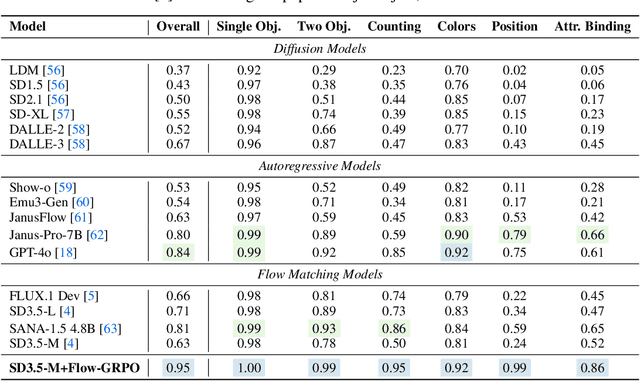
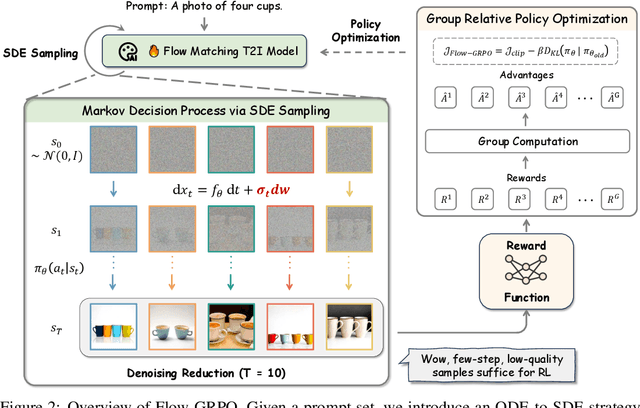
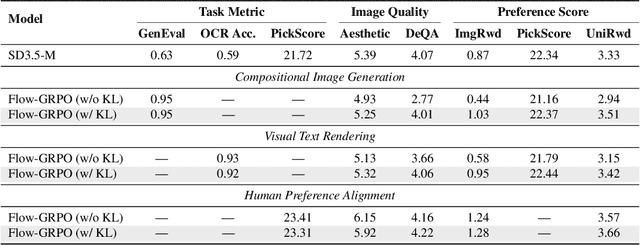
We propose Flow-GRPO, the first method integrating online reinforcement learning (RL) into flow matching models. Our approach uses two key strategies: (1) an ODE-to-SDE conversion that transforms a deterministic Ordinary Differential Equation (ODE) into an equivalent Stochastic Differential Equation (SDE) that matches the original model's marginal distribution at all timesteps, enabling statistical sampling for RL exploration; and (2) a Denoising Reduction strategy that reduces training denoising steps while retaining the original inference timestep number, significantly improving sampling efficiency without performance degradation. Empirically, Flow-GRPO is effective across multiple text-to-image tasks. For complex compositions, RL-tuned SD3.5 generates nearly perfect object counts, spatial relations, and fine-grained attributes, boosting GenEval accuracy from $63\%$ to $95\%$. In visual text rendering, its accuracy improves from $59\%$ to $92\%$, significantly enhancing text generation. Flow-GRPO also achieves substantial gains in human preference alignment. Notably, little to no reward hacking occurred, meaning rewards did not increase at the cost of image quality or diversity, and both remained stable in our experiments.
Improving Video Generation with Human Feedback
Jan 23, 2025



Video generation has achieved significant advances through rectified flow techniques, but issues like unsmooth motion and misalignment between videos and prompts persist. In this work, we develop a systematic pipeline that harnesses human feedback to mitigate these problems and refine the video generation model. Specifically, we begin by constructing a large-scale human preference dataset focused on modern video generation models, incorporating pairwise annotations across multi-dimensions. We then introduce VideoReward, a multi-dimensional video reward model, and examine how annotations and various design choices impact its rewarding efficacy. From a unified reinforcement learning perspective aimed at maximizing reward with KL regularization, we introduce three alignment algorithms for flow-based models by extending those from diffusion models. These include two training-time strategies: direct preference optimization for flow (Flow-DPO) and reward weighted regression for flow (Flow-RWR), and an inference-time technique, Flow-NRG, which applies reward guidance directly to noisy videos. Experimental results indicate that VideoReward significantly outperforms existing reward models, and Flow-DPO demonstrates superior performance compared to both Flow-RWR and standard supervised fine-tuning methods. Additionally, Flow-NRG lets users assign custom weights to multiple objectives during inference, meeting personalized video quality needs. Project page: https://gongyeliu.github.io/videoalign.
Autoregressive Models in Vision: A Survey
Nov 08, 2024
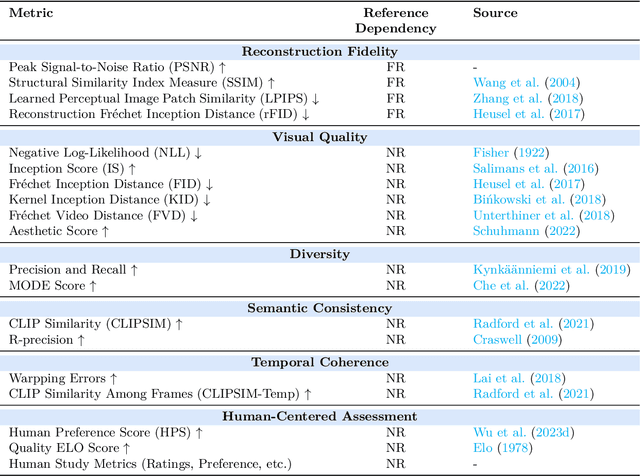

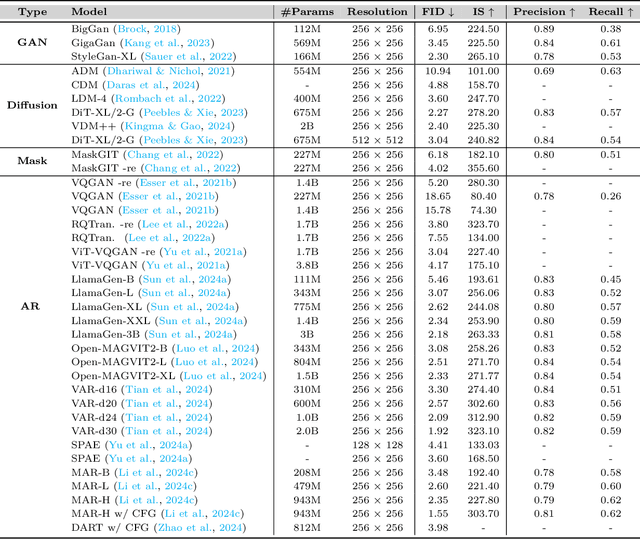
Autoregressive modeling has been a huge success in the field of natural language processing (NLP). Recently, autoregressive models have emerged as a significant area of focus in computer vision, where they excel in producing high-quality visual content. Autoregressive models in NLP typically operate on subword tokens. However, the representation strategy in computer vision can vary in different levels, \textit{i.e.}, pixel-level, token-level, or scale-level, reflecting the diverse and hierarchical nature of visual data compared to the sequential structure of language. This survey comprehensively examines the literature on autoregressive models applied to vision. To improve readability for researchers from diverse research backgrounds, we start with preliminary sequence representation and modeling in vision. Next, we divide the fundamental frameworks of visual autoregressive models into three general sub-categories, including pixel-based, token-based, and scale-based models based on the strategy of representation. We then explore the interconnections between autoregressive models and other generative models. Furthermore, we present a multi-faceted categorization of autoregressive models in computer vision, including image generation, video generation, 3D generation, and multi-modal generation. We also elaborate on their applications in diverse domains, including emerging domains such as embodied AI and 3D medical AI, with about 250 related references. Finally, we highlight the current challenges to autoregressive models in vision with suggestions about potential research directions. We have also set up a Github repository to organize the papers included in this survey at: \url{https://github.com/ChaofanTao/Autoregressive-Models-in-Vision-Survey}.
CGB-DM: Content and Graphic Balance Layout Generation with Transformer-based Diffusion Model
Jul 23, 2024
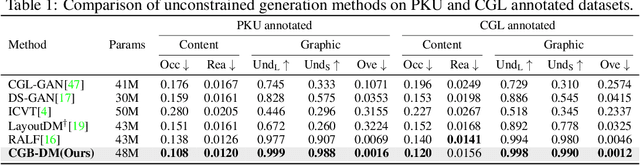
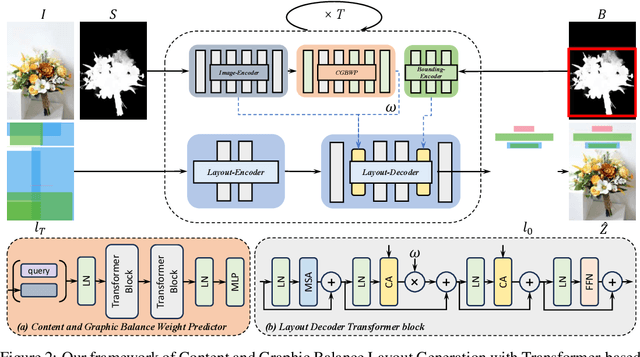

Layout generation is the foundation task of intelligent design, which requires the integration of visual aesthetics and harmonious expression of content delivery. However, existing methods still face challenges in generating precise and visually appealing layouts, including blocking, overlap, or spatial misalignment between layouts, which are closely related to the spatial structure of graphic layouts. We find that these methods overly focus on content information and lack constraints on layout spatial structure, resulting in an imbalance of learning content-aware and graphic-aware features. To tackle this issue, we propose Content and Graphic Balance Layout Generation with Transformer-based Diffusion Model (CGB-DM). Specifically, we first design a regulator that balances the predicted content and graphic weight, overcoming the tendency of paying more attention to the content on canvas. Secondly, we introduce a graphic constraint of saliency bounding box to further enhance the alignment of geometric features between layout representations and images. In addition, we adapt a transformer-based diffusion model as the backbone, whose powerful generation capability ensures the quality in layout generation. Extensive experimental results indicate that our method has achieved state-of-the-art performance in both quantitative and qualitative evaluations. Our model framework can also be expanded to other graphic design fields.
ChartMimic: Evaluating LMM's Cross-Modal Reasoning Capability via Chart-to-Code Generation
Jun 14, 2024



We introduce a new benchmark, ChartMimic, aimed at assessing the visually-grounded code generation capabilities of large multimodal models (LMMs). ChartMimic utilizes information-intensive visual charts and textual instructions as inputs, requiring LMMs to generate the corresponding code for chart rendering. ChartMimic includes 1,000 human-curated (figure, instruction, code) triplets, which represent the authentic chart use cases found in scientific papers across various domains(e.g., Physics, Computer Science, Economics, etc). These charts span 18 regular types and 4 advanced types, diversifying into 191 subcategories. Furthermore, we propose multi-level evaluation metrics to provide an automatic and thorough assessment of the output code and the rendered charts. Unlike existing code generation benchmarks, ChartMimic places emphasis on evaluating LMMs' capacity to harmonize a blend of cognitive capabilities, encompassing visual understanding, code generation, and cross-modal reasoning. The evaluation of 3 proprietary models and 11 open-weight models highlights the substantial challenges posed by ChartMimic. Even the advanced GPT-4V, Claude-3-opus only achieve an average score of 73.2 and 53.7, respectively, indicating significant room for improvement. We anticipate that ChartMimic will inspire the development of LMMs, advancing the pursuit of artificial general intelligence.
StyleCrafter: Enhancing Stylized Text-to-Video Generation with Style Adapter
Dec 01, 2023



Text-to-video (T2V) models have shown remarkable capabilities in generating diverse videos. However, they struggle to produce user-desired stylized videos due to (i) text's inherent clumsiness in expressing specific styles and (ii) the generally degraded style fidelity. To address these challenges, we introduce StyleCrafter, a generic method that enhances pre-trained T2V models with a style control adapter, enabling video generation in any style by providing a reference image. Considering the scarcity of stylized video datasets, we propose to first train a style control adapter using style-rich image datasets, then transfer the learned stylization ability to video generation through a tailor-made finetuning paradigm. To promote content-style disentanglement, we remove style descriptions from the text prompt and extract style information solely from the reference image using a decoupling learning strategy. Additionally, we design a scale-adaptive fusion module to balance the influences of text-based content features and image-based style features, which helps generalization across various text and style combinations. StyleCrafter efficiently generates high-quality stylized videos that align with the content of the texts and resemble the style of the reference images. Experiments demonstrate that our approach is more flexible and efficient than existing competitors.
Accelerating Diffusion Models for Inverse Problems through Shortcut Sampling
May 26, 2023
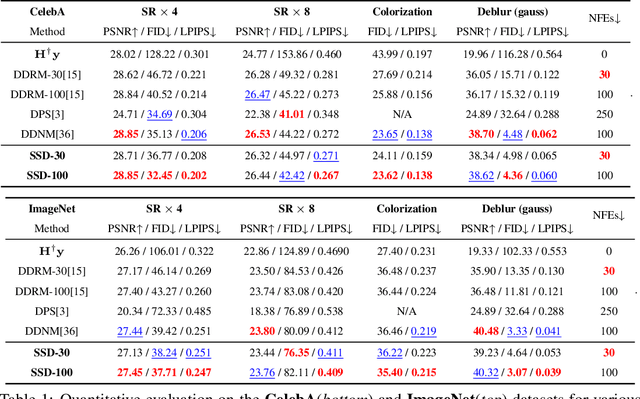


Recently, diffusion models have demonstrated a remarkable ability to solve inverse problems in an unsupervised manner. Existing methods mainly focus on modifying the posterior sampling process while neglecting the potential of the forward process. In this work, we propose Shortcut Sampling for Diffusion (SSD), a novel pipeline for solving inverse problems. Instead of initiating from random noise, the key concept of SSD is to find the "Embryo", a transitional state that bridges the measurement image y and the restored image x. By utilizing the "shortcut" path of "input-Embryo-output", SSD can achieve precise and fast restoration. To obtain the Embryo in the forward process, We propose Distortion Adaptive Inversion (DA Inversion). Moreover, we apply back projection and attention injection as additional consistency constraints during the generation process. Experimentally, we demonstrate the effectiveness of SSD on several representative tasks, including super-resolution, deblurring, and colorization. Compared to state-of-the-art zero-shot methods, our method achieves competitive results with only 30 NFEs. Moreover, SSD with 100 NFEs can outperform state-of-the-art zero-shot methods in certain tasks.