 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Models in Vision: A Survey
Nov 08, 2024
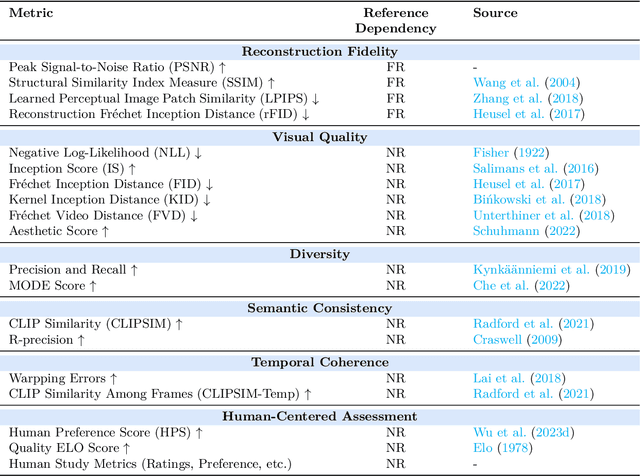

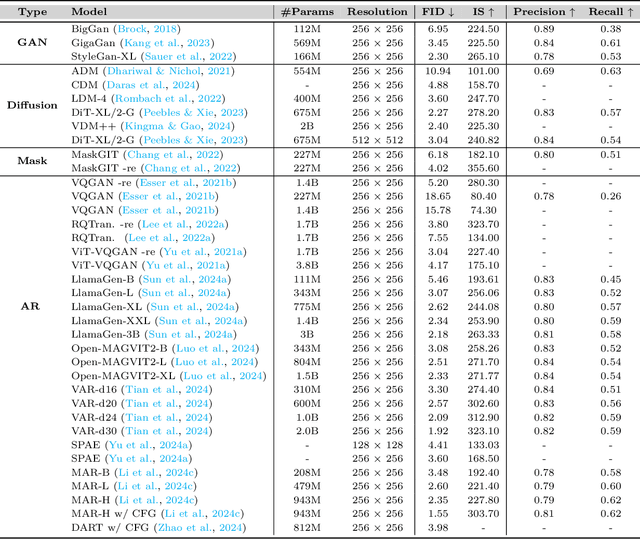
Autoregressive modeling has been a huge success in the field of natural language processing (NLP). Recently, autoregressive models have emerged as a significant area of focus in computer vision, where they excel in producing high-quality visual content. Autoregressive models in NLP typically operate on subword tokens. However, the representation strategy in computer vision can vary in different levels, \textit{i.e.}, pixel-level, token-level, or scale-level, reflecting the diverse and hierarchical nature of visual data compared to the sequential structure of language. This survey comprehensively examines the literature on autoregressive models applied to vision. To improve readability for researchers from diverse research backgrounds, we start with preliminary sequence representation and modeling in vision. Next, we divide the fundamental frameworks of visual autoregressive models into three general sub-categories, including pixel-based, token-based, and scale-based models based on the strategy of representation. We then explore the interconnections between autoregressive models and other generative models. Furthermore, we present a multi-faceted categorization of autoregressive models in computer vision, including image generation, video generation, 3D generation, and multi-modal generation. We also elaborate on their applications in diverse domains, including emerging domains such as embodied AI and 3D medical AI, with about 250 related references. Finally, we highlight the current challenges to autoregressive models in vision with suggestions about potential research directions. We have also set up a Github repository to organize the papers included in this survey at: \url{https://github.com/ChaofanTao/Autoregressive-Models-in-Vision-Survey}.
GODIVA: Generating Open-DomaIn Videos from nAtural Descriptions
Apr 30, 2021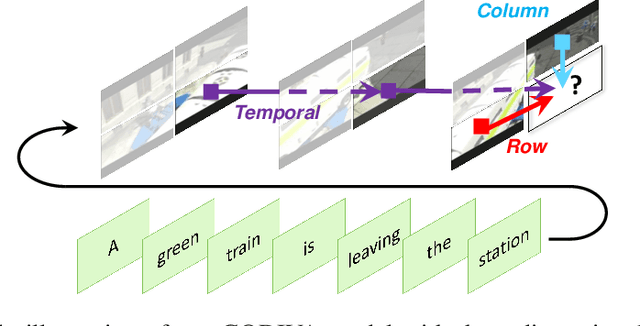
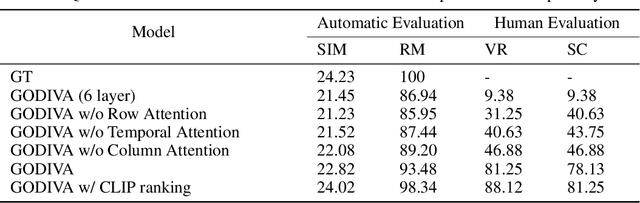
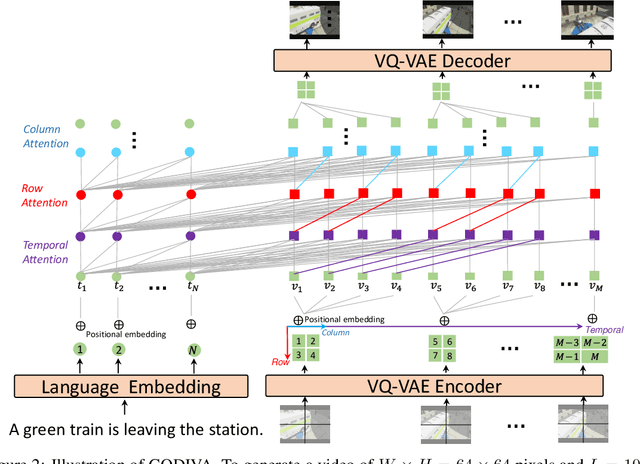

Generating videos from text is a challenging task due to its high computational requirements for training and infinite possible answers for evaluation. Existing works typically experiment on simple or small datasets, where the generalization ability is quite limited. In this work, we propose GODIVA, an open-domain text-to-video pretrained model that can generate videos from text in an auto-regressive manner using a three-dimensional sparse attention mechanism. We pretrain our model on Howto100M, a large-scale text-video dataset that contains more than 136 million text-video pairs. Experiments show that GODIVA not only can be fine-tuned on downstream video generation tasks, but also has a good zero-shot capability on unseen texts. We also propose a new metric called Relative Matching (RM) to automatically evaluate the video generation quality. Several challenges are listed and discussed as future work.
Adaptively Aligned Image Captioning via Adaptive Attention Time
Nov 01, 2019



Recent neural models for image captioning usually employ an encoder-decoder framework with an attention mechanism. However, the attention mechanism in such a framework aligns one single (attended) image feature vector to one caption word, assuming one-to-one mapping from source image regions and target caption words, which is never possible. In this paper, we propose a novel attention model, namely Adaptive Attention Time (AAT), to align the source and the target adaptively for image captioning. AAT allows the framework to learn how many attention steps to take to output a caption word at each decoding step. With AAT, an image region can be mapped to an arbitrary number of caption words while a caption word can also attend to an arbitrary number of image regions. AAT is deterministic and differentiable, and doesn't introduce any noise to the parameter gradients. In this paper, we empirically show that AAT improves over state-of-the-art methods on the task of image captioning. Code is available at https://github.com/husthuaan/AAT.
Attention on Attention for Image Captioning
Aug 21, 2019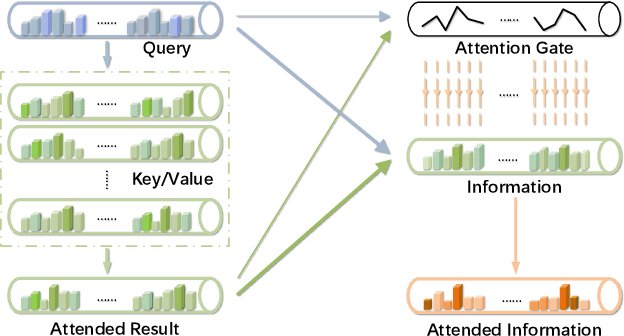
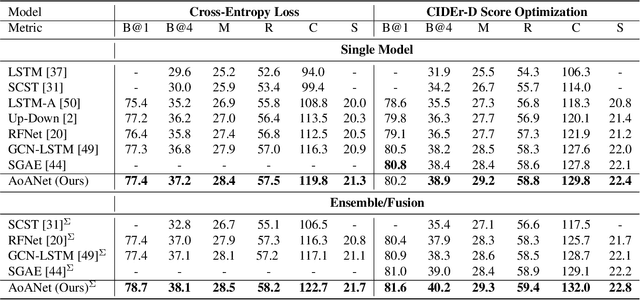
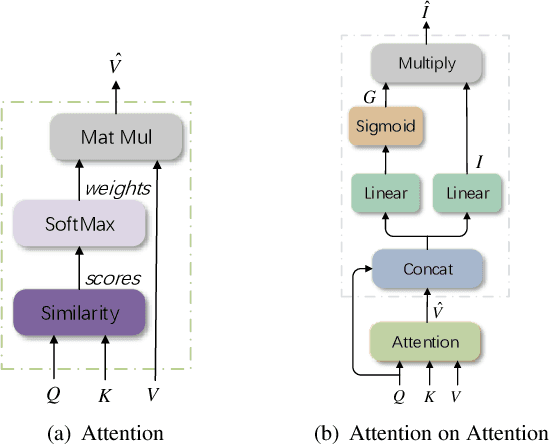
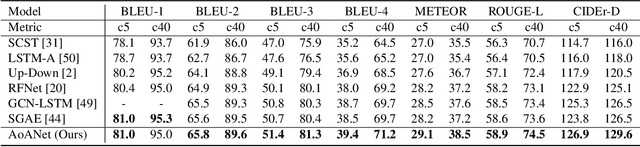
Attention mechanisms are widely used in current encoder/decoder frameworks of image captioning, where a weighted average on encoded vectors is generated at each time step to guide the caption decoding process. However, the decoder has little idea of whether or how well the attended vector and the given attention query are related, which could make the decoder give misled results. In this paper, we propose an Attention on Attention (AoA) module, which extends the conventional attention mechanisms to determine the relevance between attention results and queries. AoA first generates an information vector and an attention gate using the attention result and the current context, then adds another attention by applying element-wise multiplication to them and finally obtains the attended information, the expected useful knowledge. We apply AoA to both the encoder and the decoder of our image captioning model, which we name as AoA Network (AoANet). Experiments show that AoANet outperforms all previously published methods and achieves a new state-of-the-art performance of 129.8 CIDEr-D score on MS COCO Karpathy offline test split and 129.6 CIDEr-D (C40) score on the official online testing server. Code is available at https://github.com/husthuaan/AoANet.
ParNet: Position-aware Aggregated Relation Network for Image-Text matching
Jun 17, 2019



Exploring fine-grained relationship between entities(e.g. objects in image or words in sentence) has great contribution to understand multimedia content precisely. Previous attention mechanism employed in image-text matching either takes multiple self attention steps to gather correspondences or uses image objects (or words) as context to infer image-text similarity. However, they only take advantage of semantic information without considering that objects' relative position also contributes to image understanding. To this end, we introduce a novel position-aware relation module to model both the semantic and spatial relationship simultaneously for image-text matching in this paper. Given an image, our method utilizes the location of different objects to capture spatial relationship innovatively. With the combination of semantic and spatial relationship, it's easier to understand the content of different modalities (images and sentences) and capture fine-grained latent correspondences of image-text pairs. Besides, we employ a two-step aggregated relation module to capture interpretable alignment of image-text pairs. The first step, we call it intra-modal relation mechanism, in which we computes responses between different objects in an image or different words in a sentence separately; The second step, we call it inter-modal relation mechanism, in which the query plays a role of textual context to refine the relationship among object proposals in an image. In this way, our position-aware aggregated relation network (ParNet) not only knows which entities are relevant by attending on different objects (words) adaptively, but also adjust the inter-modal correspondence according to the latent alignments according to query's content. Our approach achieves the state-of-the-art results on MS-COCO dataset.