 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetroInfer: A Vector-Storage Approach for Scalable Long-Context LLM Inference
May 05, 2025The growing context lengths of large language models (LLMs) pose significant challenges for efficient inference, primarily due to GPU memory and bandwidth constraints. We present RetroInfer, a novel system that reconceptualizes the key-value (KV) cache as a vector storage system which exploits the inherent attention sparsity to accelerate long-context LLM inference. At its core is the wave index, an Attention-aWare VEctor index that enables efficient and accurate retrieval of critical tokens through techniques such as tripartite attention approximation, accuracy-bounded attention estimation, and segmented clustering. Complementing this is the wave buffer, which coordinates KV cache placement and overlaps computation and data transfer across GPU and CPU to sustain high throughput. Unlike prior sparsity-based methods that struggle with token selection and hardware coordination, RetroInfer delivers robust performance without compromising model accuracy. Experiments on long-context benchmarks show up to 4.5X speedup over full attention within GPU memory limits and up to 10.5X over sparse attention baselines when KV cache is extended to CPU memory, all while preserving full-attention-level accuracy.
Scaling Up On-Device LLMs via Active-Weight Swapping Between DRAM and Flash
Apr 11, 2025Large language models (LLMs) are increasingly being deployed on mobile devices, but the limited DRAM capacity constrains the deployable model size. This paper introduces ActiveFlow, the first LLM inference framework that can achieve adaptive DRAM usage for modern LLMs (not ReLU-based), enabling the scaling up of deployable model sizes. The framework is based on the novel concept of active weight DRAM-flash swapping and incorporates three novel techniques: (1) Cross-layer active weights preloading. It uses the activations from the current layer to predict the active weights of several subsequent layers, enabling computation and data loading to overlap, as well as facilitating large I/O transfers. (2) Sparsity-aware self-distillation. It adjusts the active weights to align with the dense-model output distribution, compensating for approximations introduced by contextual sparsity. (3) Active weight DRAM-flash swapping pipeline. It orchestrates the DRAM space allocation among the hot weight cache, preloaded active weights, and computation-involved weights based on available memory. Results show ActiveFlow achieves the performance-cost Pareto frontier compared to existing efficiency optimization methods.
Making Every Frame Matter: Continuous Video Understanding for Large Models via Adaptive State Modeling
Oct 19, 2024
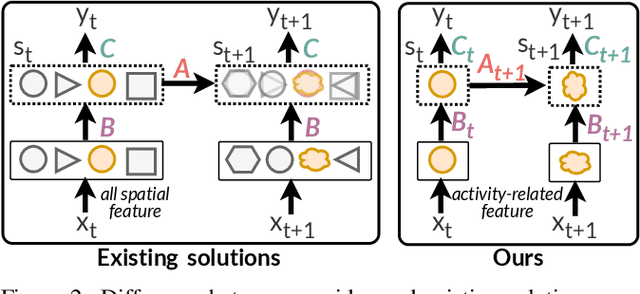
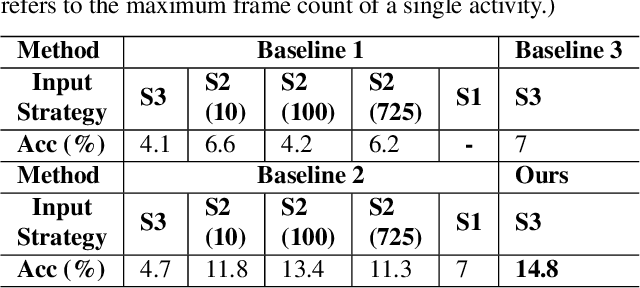
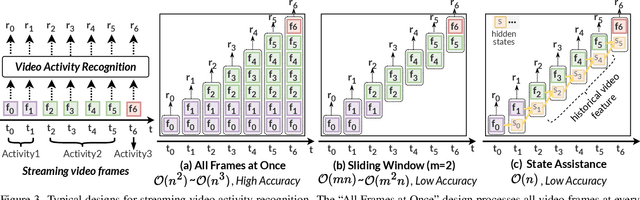
Video understanding has become increasingly important with the rise of multi-modality applications. Understanding continuous video poses considerable challenges due to the fast expansion of streaming video, which contains multi-scale and untrimmed events. We introduce a novel system, C-VUE, to overcome these issues through adaptive state modeling. C-VUE has three key designs. The first is a long-range history modeling technique that uses a video-aware approach to retain historical video information. The second is a spatial redundancy reduction technique, which enhances the efficiency of history modeling based on temporal relations. The third is a parallel training structure that incorporates the frame-weighted loss to understand multi-scale events in long videos. Our C-VUE offers high accuracy and efficiency. It runs at speeds >30 FPS on typical edge devices and outperforms all baselines in accuracy. Moreover, applying C-VUE to a video foundation model as a video encoder in our case study resulted in a 0.46-point enhancement (on a 5-point scale) on the in-distribution dataset, and an improvement ranging from 1.19\% to 4\% on zero-shot datasets.
SPFresh: Incremental In-Place Update for Billion-Scale Vector Search
Oct 18, 2024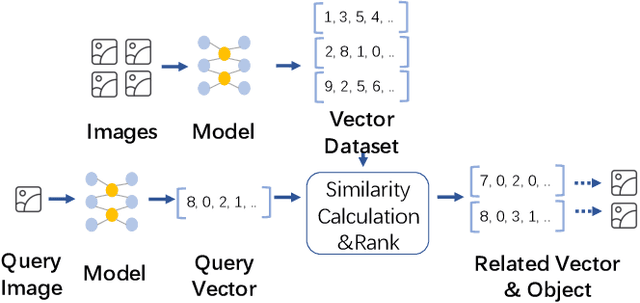
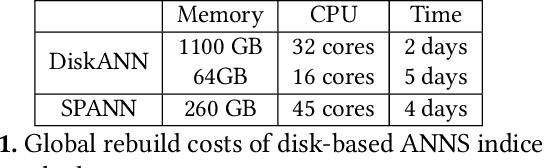
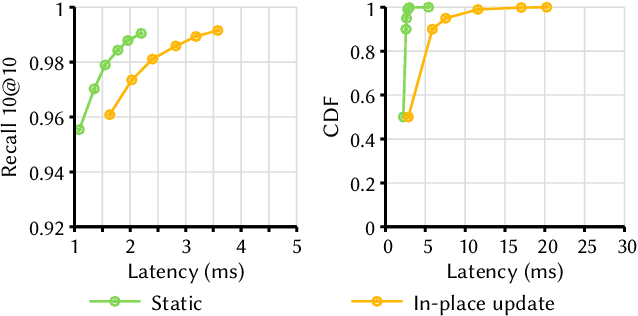
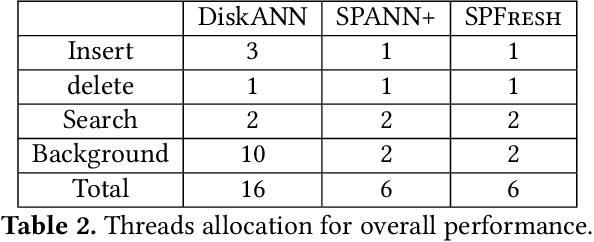
Approximate Nearest Neighbor Search (ANNS) is now widely used in various applications, ranging from information retrieval, question answering, and recommendation, to search for similar high-dimensional vectors. As the amount of vector data grows continuously, it becomes important to support updates to vector index, the enabling technique that allows for efficient and accurate ANNS on vectors. Because of the curse of high dimensionality, it is often costly to identify the right neighbors of a single new vector, a necessary process for index update. To amortize update costs, existing systems maintain a secondary index to accumulate updates, which are merged by the main index by global rebuilding the entire index periodically. However, this approach has high fluctuations of search latency and accuracy, not even to mention that it requires substantial resources and is extremely time-consuming for rebuilds. We introduce SPFresh, a system that supports in-place vector updates. At the heart of SPFresh is LIRE, a lightweight incremental rebalancing protocol to split vector partitions and reassign vectors in the nearby partitions to adapt to data distribution shift. LIRE achieves low-overhead vector updates by only reassigning vectors at the boundary between partitions, where in a high-quality vector index the amount of such vectors are deemed small. With LIRE, SPFresh provides superior query latency and accuracy to solutions based on global rebuild, with only 1% of DRAM and less than 10% cores needed at the peak compared to the state-of-the-art, in a billion scale vector index with 1% of daily vector update rate.
RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval
Sep 16, 2024



Transformer-based large Language Models (LLMs) become increasingly important in various domains. However, the quadratic time complexity of attention operation poses a significant challenge for scaling to longer contexts due to the extremely high inference latency and GPU memory consumption for caching key-value (KV) vectors. This paper proposes RetrievalAttention, a training-free approach to accelerate attention computation. To leverage the dynamic sparse property of attention, RetrievalAttention builds approximate nearest neighbor search (ANNS) indexes upon KV vectors in CPU memory and retrieves the most relevant ones via vector search during generation. Due to the out-of-distribution (OOD) between query vectors and key vectors, off-the-shelf ANNS indexes still need to scan O(N) (usually 30% of all keys) data for accurate retrieval, which fails to exploit the high sparsity. RetrievalAttention first identifies the OOD challenge of ANNS-based attention, and addresses it via an attention-aware vector search algorithm that can adapt to queries and only access 1--3% of data, thus achieving a sub-linear time complexity. RetrievalAttention greatly reduces the inference cost of long-context LLM with much lower GPU memory requirements while maintaining the model accuracy. Especially, RetrievalAttention only needs 16GB GPU memory for serving 128K tokens in LLMs with 8B parameters, which is capable of generating one token in 0.188 seconds on a single NVIDIA RTX4090 (24GB).
GODIVA: Generating Open-DomaIn Videos from nAtural Descriptions
Apr 30, 2021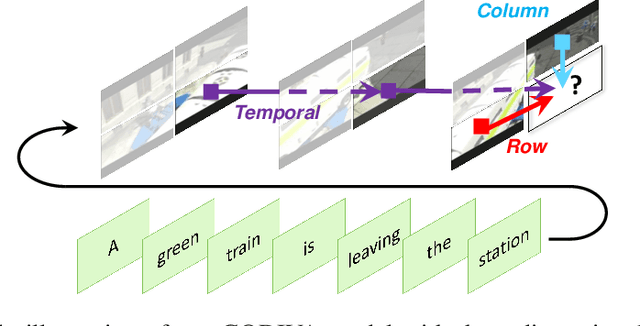
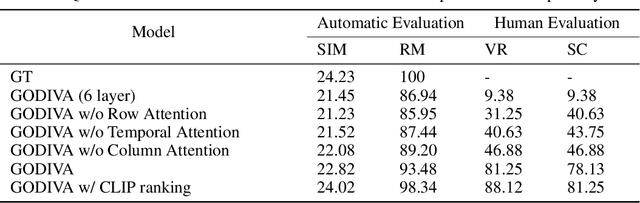
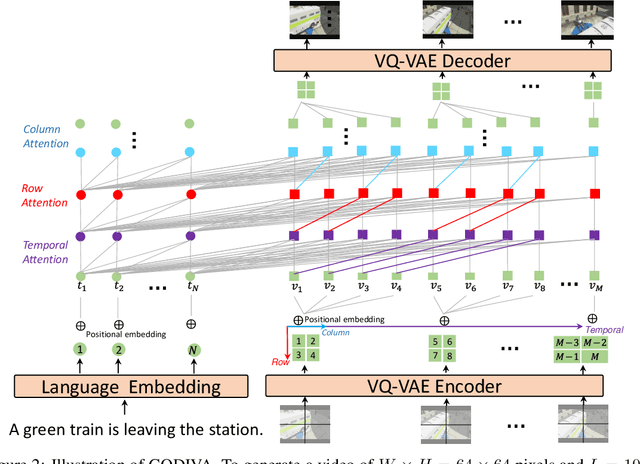

Generating videos from text is a challenging task due to its high computational requirements for training and infinite possible answers for evaluation. Existing works typically experiment on simple or small datasets, where the generalization ability is quite limited. In this work, we propose GODIVA, an open-domain text-to-video pretrained model that can generate videos from text in an auto-regressive manner using a three-dimensional sparse attention mechanism. We pretrain our model on Howto100M, a large-scale text-video dataset that contains more than 136 million text-video pairs. Experiments show that GODIVA not only can be fine-tuned on downstream video generation tasks, but also has a good zero-shot capability on unseen texts. We also propose a new metric called Relative Matching (RM) to automatically evaluate the video generation quality. Several challenges are listed and discussed as future work.