 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVecAttention: Vector-wise Sparse Attention for Accelerating Long Context Inference
Mar 31, 2026Long-context video understanding and generation pose a significant computational challenge for Transformer-based video models due to the quadratic complexity of self-attention. While existing sparse attention methods employ coarse-grained patterns to improve efficiency, they typically incur redundant computation and suboptimal performance. To address this issue, in this paper, we propose \textbf{VecAttention}, a novel framework of vector-wise sparse attention that achieves superior accuracy-efficiency trade-offs for video models. We observe that video attention maps exhibit a strong vertical-vector sparse pattern, and further demonstrate that this vertical-vector pattern offers consistently better accuracy-sparsity trade-offs compared with existing coarse-grained sparse patterns. Based on this observation, VecAttention dynamically selects and processes only informative vertical vectors through a lightweight important-vector selection that minimizes memory access overhead and an optimized kernel of vector sparse attention. Comprehensive evaluations on video understanding (VideoMME, LongVideoBench, and VCRBench) and generation (VBench) tasks show that VecAttention delivers a 2.65$\times$ speedup over full attention and a 1.83$\times$ speedup over state-of-the-art sparse attention methods, with comparable accuracy to full attention. Our code is available at https://github.com/anminliu/VecAttention.
SortedRL: Accelerating RL Training for LLMs through Online Length-Aware Scheduling
Mar 24, 2026Scaling reinforcement learning (RL) has shown strong promise for enhancing the reasoning abilities of large language models (LLMs), particularly in tasks requiring long chain-of-thought generation. However, RL training efficiency is often bottlenecked by the rollout phase, which can account for up to 70% of total training time when generating long trajectories (e.g., 16k tokens), due to slow autoregressive generation and synchronization overhead between rollout and policy updates. We propose SortedRL, an online length-aware scheduling strategy designed to address this bottleneck by improving rollout efficiency and maintaining training stability. SortedRL reorders rollout samples based on output lengths, prioritizing short samples forming groups for early updates. This enables large rollout batches, flexible update batches, and near on-policy micro-curriculum construction simultaneously. To further accelerate the pipeline, SortedRL incorporates a mechanism to control the degree of off-policy training through a cache-based mechanism, and is supported by a dedicated RL infrastructure that manages rollout and update via a stateful controller and rollout buffer. Experiments using LLaMA-3.1-8B and Qwen-2.5-32B on diverse tasks, including logical puzzles, and math challenges like AIME 24, Math 500, and Minerval, show that SortedRL reduces RL training bubble ratios by over 50%, while attaining 3.9% to 18.4% superior performance over baseline given same amount of data.
ParisKV: Fast and Drift-Robust KV-Cache Retrieval for Long-Context LLMs
Feb 07, 2026KV-cache retrieval is essential for long-context LLM inference, yet existing methods struggle with distribution drift and high latency at scale. We introduce ParisKV, a drift-robust, GPU-native KV-cache retrieval framework based on collision-based candidate selection, followed by a quantized inner-product reranking estimator. For million-token contexts, ParisKV supports CPU-offloaded KV caches via Unified Virtual Addressing (UVA), enabling on-demand top-$k$ fetching with minimal overhead. ParisKV matches or outperforms full attention quality on long-input and long-generation benchmarks. It achieves state-of-the-art long-context decoding efficiency: it matches or exceeds full attention speed even at batch size 1 for long contexts, delivers up to 2.8$\times$ higher throughput within full attention's runnable range, and scales to million-token contexts where full attention runs out of memory. At million-token scale, ParisKV reduces decode latency by 17$\times$ and 44$\times$ compared to MagicPIG and PQCache, respectively, two state-of-the-art KV-cache Top-$k$ retrieval baselines.
MTraining: Distributed Dynamic Sparse Attention for Efficient Ultra-Long Context Training
Oct 21, 2025The adoption of long context windows has become a standard feature in Large Language Models (LLMs), as extended contexts significantly enhance their capacity for complex reasoning and broaden their applicability across diverse scenarios. Dynamic sparse attention is a promising approach for reducing the computational cost of long-context. However, efficiently training LLMs with dynamic sparse attention on ultra-long contexts-especially in distributed settings-remains a significant challenge, due in large part to worker- and step-level imbalance. This paper introduces MTraining, a novel distributed methodology leveraging dynamic sparse attention to enable efficient training for LLMs with ultra-long contexts. Specifically, MTraining integrates three key components: a dynamic sparse training pattern, balanced sparse ring attention, and hierarchical sparse ring attention. These components are designed to synergistically address the computational imbalance and communication overheads inherent in dynamic sparse attention mechanisms during the training of models with extensive context lengths. We demonstrate the efficacy of MTraining by training Qwen2.5-3B, successfully expanding its context window from 32K to 512K tokens on a cluster of 32 A100 GPUs. Our evaluations on a comprehensive suite of downstream tasks, including RULER, PG-19, InfiniteBench, and Needle In A Haystack, reveal that MTraining achieves up to a 6x higher training throughput while preserving model accuracy. Our code is available at https://github.com/microsoft/MInference/tree/main/MTraining.
SecurityLingua: Efficient Defense of LLM Jailbreak Attacks via Security-Aware Prompt Compression
Jun 15, 2025Large language models (LLMs) have achieved widespread adoption across numerous applications. However, many LLMs are vulnerable to malicious attacks even after safety alignment. These attacks typically bypass LLMs' safety guardrails by wrapping the original malicious instructions inside adversarial jailbreaks prompts. Previous research has proposed methods such as adversarial training and prompt rephrasing to mitigate these safety vulnerabilities, but these methods often reduce the utility of LLMs or lead to significant computational overhead and online latency. In this paper, we propose SecurityLingua, an effective and efficient approach to defend LLMs against jailbreak attacks via security-oriented prompt compression. Specifically, we train a prompt compressor designed to discern the "true intention" of the input prompt, with a particular focus on detecting the malicious intentions of adversarial prompts. Then, in addition to the original prompt, the intention is passed via the system prompt to the target LLM to help it identify the true intention of the request. SecurityLingua ensures a consistent user experience by leaving the original input prompt intact while revealing the user's potentially malicious intention and stimulating the built-in safety guardrails of the LLM. Moreover, thanks to prompt compression, SecurityLingua incurs only a negligible overhead and extra token cost compared to all existing defense methods, making it an especially practical solution for LLM defense. Experimental results demonstrate that SecurityLingua can effectively defend against malicious attacks and maintain utility of the LLM with negligible compute and latency overhead. Our code is available at https://aka.ms/SecurityLingua.
Chain-of-Model Learning for Language Model
May 17, 2025In this paper, we propose a novel learning paradigm, termed Chain-of-Model (CoM), which incorporates the causal relationship into the hidden states of each layer as a chain style, thereby introducing great scaling efficiency in model training and inference flexibility in deployment. We introduce the concept of Chain-of-Representation (CoR), which formulates the hidden states at each layer as a combination of multiple sub-representations (i.e., chains) at the hidden dimension level. In each layer, each chain from the output representations can only view all of its preceding chains in the input representations. Consequently, the model built upon CoM framework can progressively scale up the model size by increasing the chains based on the previous models (i.e., chains), and offer multiple sub-models at varying sizes for elastic inference by using different chain numbers. Based on this principle, we devise Chain-of-Language-Model (CoLM), which incorporates the idea of CoM into each layer of Transformer architecture. Based on CoLM, we further introduce CoLM-Air by introducing a KV sharing mechanism, that computes all keys and values within the first chain and then shares across all chains. This design demonstrates additional extensibility, such as enabling seamless LM switching, prefilling acceleration and so on. Experimental results demonstrate our CoLM family can achieve comparable performance to the standard Transformer, while simultaneously enabling greater flexiblity, such as progressive scaling to improve training efficiency and offer multiple varying model sizes for elastic inference, paving a a new way toward building language models. Our code will be released in the future at: https://github.com/microsoft/CoLM.
RetroInfer: A Vector-Storage Approach for Scalable Long-Context LLM Inference
May 05, 2025The growing context lengths of large language models (LLMs) pose significant challenges for efficient inference, primarily due to GPU memory and bandwidth constraints. We present RetroInfer, a novel system that reconceptualizes the key-value (KV) cache as a vector storage system which exploits the inherent attention sparsity to accelerate long-context LLM inference. At its core is the wave index, an Attention-aWare VEctor index that enables efficient and accurate retrieval of critical tokens through techniques such as tripartite attention approximation, accuracy-bounded attention estimation, and segmented clustering. Complementing this is the wave buffer, which coordinates KV cache placement and overlaps computation and data transfer across GPU and CPU to sustain high throughput. Unlike prior sparsity-based methods that struggle with token selection and hardware coordination, RetroInfer delivers robust performance without compromising model accuracy. Experiments on long-context benchmarks show up to 4.5X speedup over full attention within GPU memory limits and up to 10.5X over sparse attention baselines when KV cache is extended to CPU memory, all while preserving full-attention-level accuracy.
Zoomer: Adaptive Image Focus Optimization for Black-box MLLM
Apr 30, 2025



Recent advancements in multimodal large language models (MLLMs) have broadened the scope of vision-language tasks, excelling in applications like image captioning and interactive question-answering. However, these models struggle with accurately processing visual data, particularly in tasks requiring precise object recognition and fine visual details. Stringent token limits often result in the omission of critical information, hampering performance. To address these limitations, we introduce \SysName, a novel visual prompting mechanism designed to enhance MLLM performance while preserving essential visual details within token limits. \SysName features three key innovations: a prompt-aware strategy that dynamically highlights relevant image regions, a spatial-preserving orchestration schema that maintains object integrity, and a budget-aware prompting method that balances global context with crucial visual details. Comprehensive evaluations across multiple datasets demonstrate that \SysName consistently outperforms baseline methods, achieving up to a $26.9\%$ improvement in accuracy while significantly reducing token consumption.
MMInference: Accelerating Pre-filling for Long-Context VLMs via Modality-Aware Permutation Sparse Attention
Apr 22, 2025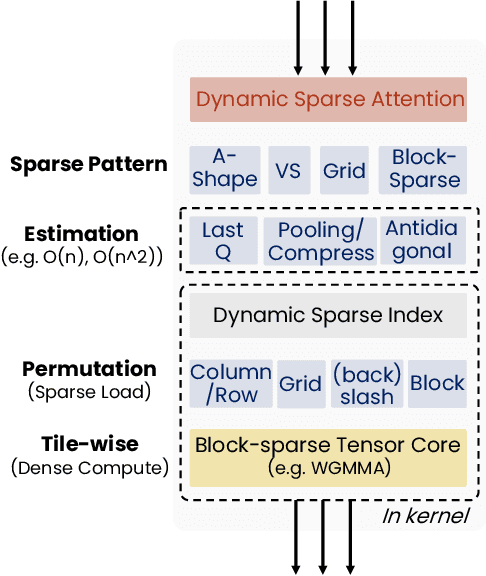
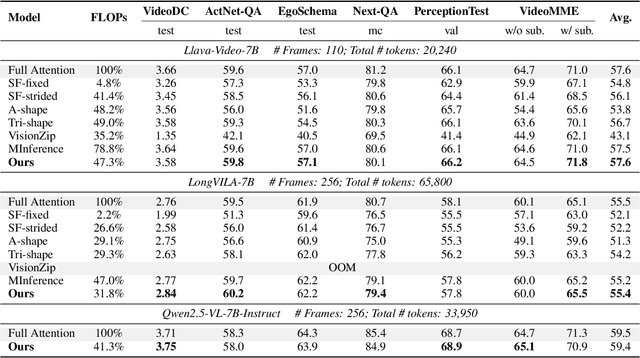
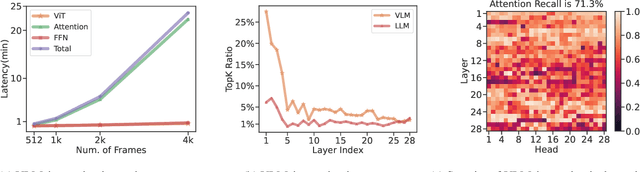

The integration of long-context capabilities with visual understanding unlocks unprecedented potential for Vision Language Models (VLMs). However, the quadratic attention complexity during the pre-filling phase remains a significant obstacle to real-world deployment. To overcome this limitation, we introduce MMInference (Multimodality Million tokens Inference), a dynamic sparse attention method that accelerates the prefilling stage for long-context multi-modal inputs. First, our analysis reveals that the temporal and spatial locality of video input leads to a unique sparse pattern, the Grid pattern. Simultaneously, VLMs exhibit markedly different sparse distributions across different modalities. We introduce a permutation-based method to leverage the unique Grid pattern and handle modality boundary issues. By offline search the optimal sparse patterns for each head, MMInference constructs the sparse distribution dynamically based on the input. We also provide optimized GPU kernels for efficient sparse computations. Notably, MMInference integrates seamlessly into existing VLM pipelines without any model modifications or fine-tuning. Experiments on multi-modal benchmarks-including Video QA, Captioning, VisionNIAH, and Mixed-Modality NIAH-with state-of-the-art long-context VLMs (LongVila, LlavaVideo, VideoChat-Flash, Qwen2.5-VL) show that MMInference accelerates the pre-filling stage by up to 8.3x at 1M tokens while maintaining accuracy. Our code is available at https://aka.ms/MMInference.
Scaling Up On-Device LLMs via Active-Weight Swapping Between DRAM and Flash
Apr 11, 2025Large language models (LLMs) are increasingly being deployed on mobile devices, but the limited DRAM capacity constrains the deployable model size. This paper introduces ActiveFlow, the first LLM inference framework that can achieve adaptive DRAM usage for modern LLMs (not ReLU-based), enabling the scaling up of deployable model sizes. The framework is based on the novel concept of active weight DRAM-flash swapping and incorporates three novel techniques: (1) Cross-layer active weights preloading. It uses the activations from the current layer to predict the active weights of several subsequent layers, enabling computation and data loading to overlap, as well as facilitating large I/O transfers. (2) Sparsity-aware self-distillation. It adjusts the active weights to align with the dense-model output distribution, compensating for approximations introduced by contextual sparsity. (3) Active weight DRAM-flash swapping pipeline. It orchestrates the DRAM space allocation among the hot weight cache, preloaded active weights, and computation-involved weights based on available memory. Results show ActiveFlow achieves the performance-cost Pareto frontier compared to existing efficiency optimization methods.