 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Sign Language Models: Toward 3D American Sign Language Translation
Nov 11, 2025We present Large Sign Language Models (LSLM), a novel framework for translating 3D American Sign Language (ASL) by leveraging Large Language Models (LLMs) as the backbone, which can benefit hearing-impaired individuals' virtual communication. Unlike existing sign language recognition methods that rely on 2D video, our approach directly utilizes 3D sign language data to capture rich spatial, gestural, and depth information in 3D scenes. This enables more accurate and resilient translation, enhancing digital communication accessibility for the hearing-impaired community. Beyond the task of ASL translation, our work explores the integration of complex, embodied multimodal languages into the processing capabilities of LLMs, moving beyond purely text-based inputs to broaden their understanding of human communication. We investigate both direct translation from 3D gesture features to text and an instruction-guided setting where translations can be modulated by external prompts, offering greater flexibility. This work provides a foundational step toward inclusive, multimodal intelligent systems capable of understanding diverse forms of language.
Compressing CNN models for resource-constrained systems by channel and layer pruning
Sep 10, 2025

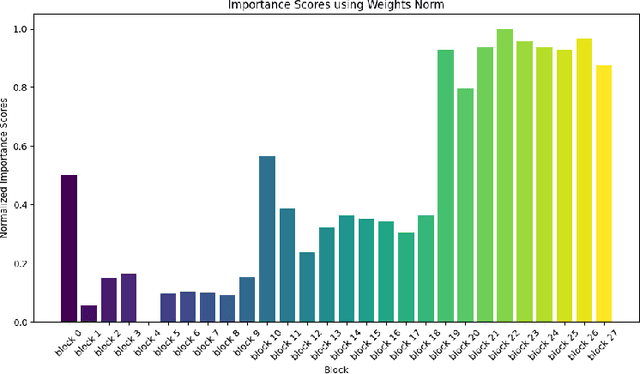

Convolutional Neural Networks (CNNs) have achieved significant breakthroughs in various fields. However, these advancements have led to a substantial increase in the complexity and size of these networks. This poses a challenge when deploying large and complex networks on edge devices. Consequently, model compression has emerged as a research field aimed at reducing the size and complexity of CNNs. One prominent technique in model compression is model pruning. This paper will present a new technique of pruning that combines both channel and layer pruning in what is called a "hybrid pruning framework". Inspired by EfficientNet, a renowned CNN architecture known for scaling up networks from both channel and layer perspectives, this hybrid approach applies the same principles but in reverse, where it scales down the network through pruning. Experiments on the hybrid approach demonstrated a notable decrease in the overall complexity of the model, with only a minimal reduction in accuracy compared to the baseline model. This complexity reduction translates into reduced latency when deploying the pruned models on an NVIDIA JETSON TX2 embedded AI device.
RetroInfer: A Vector-Storage Approach for Scalable Long-Context LLM Inference
May 05, 2025The growing context lengths of large language models (LLMs) pose significant challenges for efficient inference, primarily due to GPU memory and bandwidth constraints. We present RetroInfer, a novel system that reconceptualizes the key-value (KV) cache as a vector storage system which exploits the inherent attention sparsity to accelerate long-context LLM inference. At its core is the wave index, an Attention-aWare VEctor index that enables efficient and accurate retrieval of critical tokens through techniques such as tripartite attention approximation, accuracy-bounded attention estimation, and segmented clustering. Complementing this is the wave buffer, which coordinates KV cache placement and overlaps computation and data transfer across GPU and CPU to sustain high throughput. Unlike prior sparsity-based methods that struggle with token selection and hardware coordination, RetroInfer delivers robust performance without compromising model accuracy. Experiments on long-context benchmarks show up to 4.5X speedup over full attention within GPU memory limits and up to 10.5X over sparse attention baselines when KV cache is extended to CPU memory, all while preserving full-attention-level accuracy.
LODAP: On-Device Incremental Learning Via Lightweight Operations and Data Pruning
Apr 28, 2025



Incremental learning that learns new classes over time after the model's deployment is becoming increasingly crucial, particularly for industrial edge systems, where it is difficult to communicate with a remote server to conduct computation-intensive learning. As more classes are expected to learn after their execution for edge devices. In this paper, we propose LODAP, a new on-device incremental learning framework for edge systems. The key part of LODAP is a new module, namely Efficient Incremental Module (EIM). EIM is composed of normal convolutions and lightweight operations. During incremental learning, EIM exploits some lightweight operations, called adapters, to effectively and efficiently learn features for new classes so that it can improve the accuracy of incremental learning while reducing model complexity as well as training overhead. The efficiency of LODAP is further enhanced by a data pruning strategy that significantly reduces the training data, thereby lowering the training overhead. We conducted extensive experiments on the CIFAR-100 and Tiny- ImageNet datasets. Experimental results show that LODAP improves the accuracy by up to 4.32\% over existing methods while reducing around 50\% of model complexity. In addition, evaluations on real edge systems demonstrate its applicability for on-device machine learning. The code is available at https://github.com/duanbiqing/LODAP.
Show and Segment: Universal Medical Image Segmentation via In-Context Learning
Mar 25, 2025Medical image segmentation remains challenging due to the vast diversity of anatomical structures, imaging modalities, and segmentation tasks. While deep learning has made significant advances, current approaches struggle to generalize as they require task-specific training or fine-tuning on unseen classes. We present Iris, a novel In-context Reference Image guided Segmentation framework that enables flexible adaptation to novel tasks through the use of reference examples without fine-tuning. At its core, Iris features a lightweight context task encoding module that distills task-specific information from reference context image-label pairs. This rich context embedding information is used to guide the segmentation of target objects. By decoupling task encoding from inference, Iris supports diverse strategies from one-shot inference and context example ensemble to object-level context example retrieval and in-context tuning. Through comprehensive evaluation across twelve datasets, we demonstrate that Iris performs strongly compared to task-specific models on in-distribution tasks. On seven held-out datasets, Iris shows superior generalization to out-of-distribution data and unseen classes. Further, Iris's task encoding module can automatically discover anatomical relationships across datasets and modalities, offering insights into medical objects without explicit anatomical supervision.
Snapmoji: Instant Generation of Animatable Dual-Stylized Avatars
Mar 15, 2025



The increasing popularity of personalized avatar systems, such as Snapchat Bitmojis and Apple Memojis, highlights the growing demand for digital self-representation. Despite their widespread use, existing avatar platforms face significant limitations, including restricted expressivity due to predefined assets, tedious customization processes, or inefficient rendering requirements. Addressing these shortcomings, we introduce Snapmoji, an avatar generation system that instantly creates animatable, dual-stylized avatars from a selfie. We propose Gaussian Domain Adaptation (GDA), which is pre-trained on large-scale Gaussian models using 3D data from sources such as Objaverse and fine-tuned with 2D style transfer tasks, endowing it with a rich 3D prior. This enables Snapmoji to transform a selfie into a primary stylized avatar, like the Bitmoji style, and apply a secondary style, such as Plastic Toy or Alien, all while preserving the user's identity and the primary style's integrity. Our system is capable of producing 3D Gaussian avatars that support dynamic animation, including accurate facial expression transfer. Designed for efficiency, Snapmoji achieves selfie-to-avatar conversion in just 0.9 seconds and supports real-time interactions on mobile devices at 30 to 40 frames per second. Extensive testing confirms that Snapmoji outperforms existing methods in versatility and speed, making it a convenient tool for automatic avatar creation in various styles.
LUCAS: Layered Universal Codec Avatars
Feb 27, 2025



Photorealistic 3D head avatar reconstruction faces critical challenges in modeling dynamic face-hair interactions and achieving cross-identity generalization, particularly during expressions and head movements. We present LUCAS, a novel Universal Prior Model (UPM) for codec avatar modeling that disentangles face and hair through a layered representation. Unlike previous UPMs that treat hair as an integral part of the head, our approach separates the modeling of the hairless head and hair into distinct branches. LUCAS is the first to introduce a mesh-based UPM, facilitating real-time rendering on devices. Our layered representation also improves the anchor geometry for precise and visually appealing Gaussian renderings. Experimental results indicate that LUCAS outperforms existing single-mesh and Gaussian-based avatar models in both quantitative and qualitative assessments, including evaluations on held-out subjects in zero-shot driving scenarios. LUCAS demonstrates superior dynamic performance in managing head pose changes, expression transfer, and hairstyle variations, thereby advancing the state-of-the-art in 3D head avatar reconstruction.
The Hidden Life of Tokens: Reducing Hallucination of Large Vision-Language Models via Visual Information Steering
Feb 05, 2025



Large Vision-Language Models (LVLMs) can reason effectively over both textual and visual inputs, but they tend to hallucinate syntactically coherent yet visually ungrounded contents. In this paper, we investigate the internal dynamics of hallucination by examining the tokens logits rankings throughout the generation process, revealing three key patterns in how LVLMs process information: (1) gradual visual information loss -- visually grounded tokens gradually become less favored throughout generation, and (2) early excitation -- semantically meaningful tokens achieve peak activation in the layers earlier than the final layer. (3) hidden genuine information -- visually grounded tokens though not being eventually decided still retain relatively high rankings at inference. Based on these insights, we propose VISTA (Visual Information Steering with Token-logit Augmentation), a training-free inference-time intervention framework that reduces hallucination while promoting genuine information. VISTA works by combining two complementary approaches: reinforcing visual information in activation space and leveraging early layer activations to promote semantically meaningful decoding. Compared to existing methods, VISTA requires no external supervision and is applicable to various decoding strategies. Extensive experiments show that VISTA on average reduces hallucination by abount 40% on evaluated open-ended generation task, and it consistently outperforms existing methods on four benchmarks across four architectures under three decoding strategies.
Improved Training Technique for Latent Consistency Models
Feb 03, 2025



Consistency models are a new family of generative models capable of producing high-quality samples in either a single step or multiple steps. Recently, consistency models have demonstrated impressive performance, achieving results on par with diffusion models in the pixel space. However, the success of scaling consistency training to large-scale datasets, particularly for text-to-image and video generation tasks, is determined by performance in the latent space. In this work, we analyze the statistical differences between pixel and latent spaces, discovering that latent data often contains highly impulsive outliers, which significantly degrade the performance of iCT in the latent space. To address this, we replace Pseudo-Huber losses with Cauchy losses, effectively mitigating the impact of outliers. Additionally, we introduce a diffusion loss at early timesteps and employ optimal transport (OT) coupling to further enhance performance. Lastly, we introduce the adaptive scaling-$c$ scheduler to manage the robust training process and adopt Non-scaling LayerNorm in the architecture to better capture the statistics of the features and reduce outlier impact. With these strategies, we successfully train latent consistency models capable of high-quality sampling with one or two steps, significantly narrowing the performance gap between latent consistency and diffusion models. The implementation is released here: https://github.com/quandao10/sLCT/
Temporal Action Localization with Cross Layer Task Decoupling and Refinement
Dec 13, 2024Temporal action localization (TAL) involves dual tasks to classify and localize actions within untrimmed videos. However, the two tasks often have conflicting requirements for features. Existing methods typically employ separate heads for classification and localization tasks but share the same input feature, leading to suboptimal performance. To address this issue, we propose a novel TAL method with Cross Layer Task Decoupling and Refinement (CLTDR). Based on the feature pyramid of video, CLTDR strategy integrates semantically strong features from higher pyramid layers and detailed boundary-aware boundary features from lower pyramid layers to effectively disentangle the action classification and localization tasks. Moreover, the multiple features from cross layers are also employed to refine and align the disentangled classification and regression results. At last, a lightweight Gated Multi-Granularity (GMG) module is proposed to comprehensively extract and aggregate video features at instant, local, and global temporal granularities. Benefiting from the CLTDR and GMG modules, our method achieves state-of-the-art performance on five challenging benchmarks: THUMOS14, MultiTHUMOS, EPIC-KITCHENS-100, ActivityNet-1.3, and HACS. Our code and pre-trained models are publicly available at: https://github.com/LiQiang0307/CLTDR-GMG.