 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Action Localization with Cross Layer Task Decoupling and Refinement
Dec 13, 2024



Temporal action localization (TAL) involves dual tasks to classify and localize actions within untrimmed videos. However, the two tasks often have conflicting requirements for features. Existing methods typically employ separate heads for classification and localization tasks but share the same input feature, leading to suboptimal performance. To address this issue, we propose a novel TAL method with Cross Layer Task Decoupling and Refinement (CLTDR). Based on the feature pyramid of video, CLTDR strategy integrates semantically strong features from higher pyramid layers and detailed boundary-aware boundary features from lower pyramid layers to effectively disentangle the action classification and localization tasks. Moreover, the multiple features from cross layers are also employed to refine and align the disentangled classification and regression results. At last, a lightweight Gated Multi-Granularity (GMG) module is proposed to comprehensively extract and aggregate video features at instant, local, and global temporal granularities. Benefiting from the CLTDR and GMG modules, our method achieves state-of-the-art performance on five challenging benchmarks: THUMOS14, MultiTHUMOS, EPIC-KITCHENS-100, ActivityNet-1.3, and HACS. Our code and pre-trained models are publicly available at: https://github.com/LiQiang0307/CLTDR-GMG.
Multi-scale frequency separation network for image deblurring
Jun 01, 2022

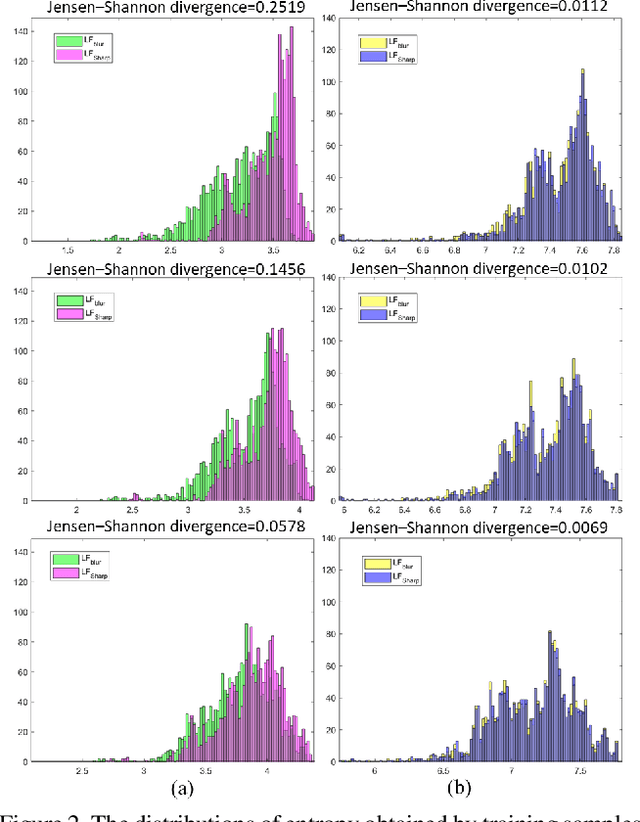
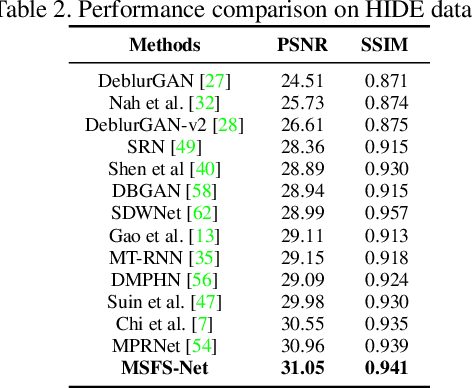
Image deblurring aims to restore the detailed texture information or structures from the blurry images, which has become an indispensable step in many computer-vision tasks. Although various methods have been proposed to deal with the image deblurring problem, most of them treated the blurry image as a whole and neglected the characteristics of different image frequencies. In this paper, we present a new method called multi-scale frequency separation network (MSFS-Net) for image deblurring. MSFS-Net introduces the frequency separation module (FSM) into an encoder-decoder network architecture to capture the low and high-frequency information of image at multiple scales. Then, a simple cycle-consistency strategy and a sophisticated contrastive learning module (CLM) are respectively designed to retain the low-frequency information and recover the high-frequency information during deblurring. At last, the features of different scales are fused by a cross-scale feature fusion module (CSFFM). Extensive experiments on benchmark datasets show that the proposed network achieves state-of-the-art performance.
Applying Wav2vec2.0 to Speech Recognition in Various Low-resource Languages
Jan 17, 2021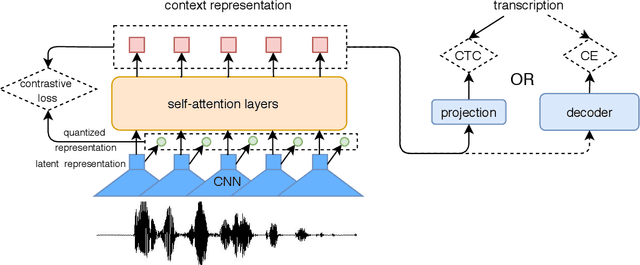
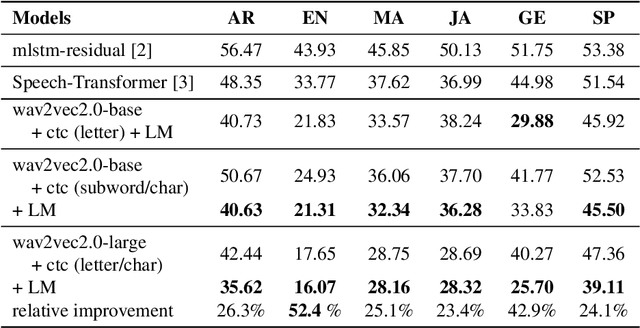
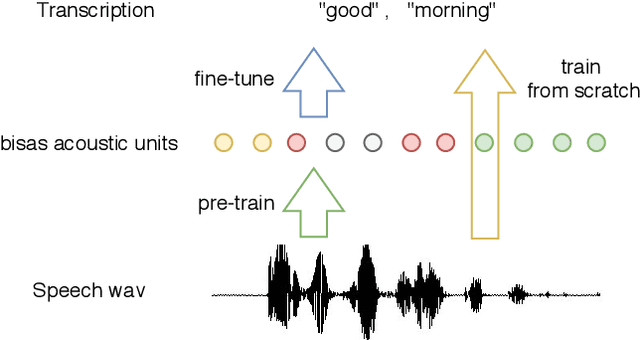
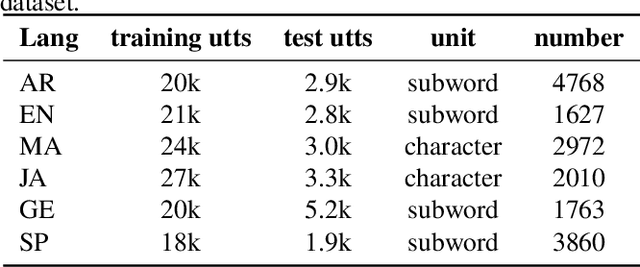
There are several domains that own corresponding widely used feature extractors, such as ResNet, BERT, and GPT-x. These models are usually pre-trained on large amounts of unlabeled data by self-supervision and can be effectively applied to downstream tasks. In the speech domain, wav2vec2.0 starts to show its powerful representation ability and feasibility of ultra-low resource speech recognition on the Librispeech corpus, which belongs to the audiobook domain. However, wav2vec2.0 has not been examined on real spoken scenarios and languages other than English. To verify its universality over languages, we apply pre-trained models to solve low-resource speech recognition tasks in various spoken languages. We achieve more than 20% relative improvements in six languages compared with previous work. Among these languages, English achieves a gain of 52.4%. Moreover, using coarse-grained modeling units, such as subword or character, achieves better results than fine-grained modeling units, such as phone or letter.
Image deblurring based on lightweight multi-information fusion network
Jan 14, 2021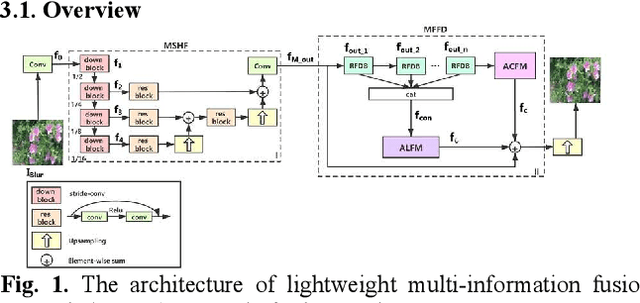
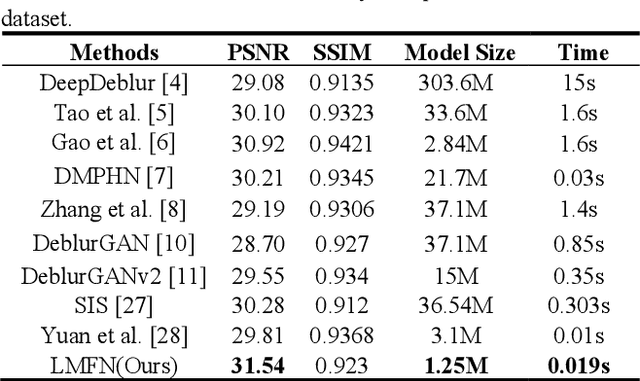
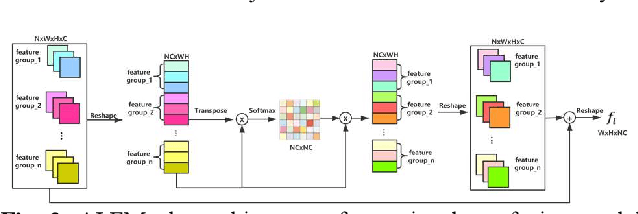

Recently, deep learning based image deblurring has been well developed. However, exploiting the detailed image features in a deep learning framework always requires a mass of parameters, which inevitably makes the network suffer from high computational burden. To solve this problem, we propose a lightweight multiinformation fusion network (LMFN) for image deblurring. The proposed LMFN is designed as an encoder-decoder architecture. In the encoding stage, the image feature is reduced to various smallscale spaces for multi-scale information extraction and fusion without a large amount of information loss. Then, a distillation network is used in the decoding stage, which allows the network benefit the most from residual learning while remaining sufficiently lightweight. Meanwhile, an information fusion strategy between distillation modules and feature channels is also carried out by attention mechanism. Through fusing different information in the proposed approach, our network can achieve state-of-the-art image deblurring result with smaller number of parameters and outperforms existing methods in model complexity.
Random VLAD based Deep Hashing for Efficient Image Retrieval
Feb 06, 2020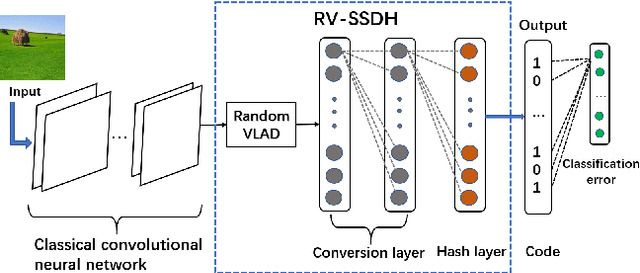
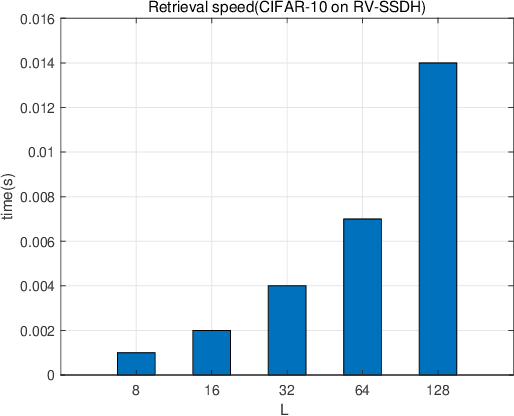
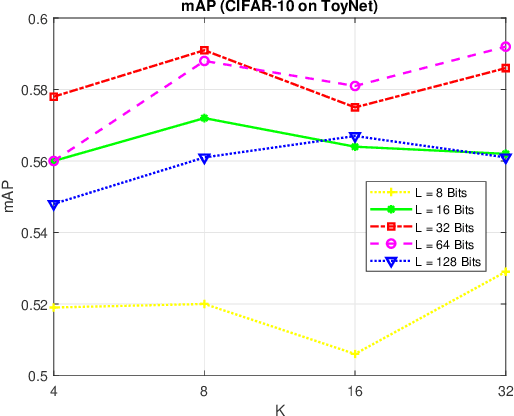
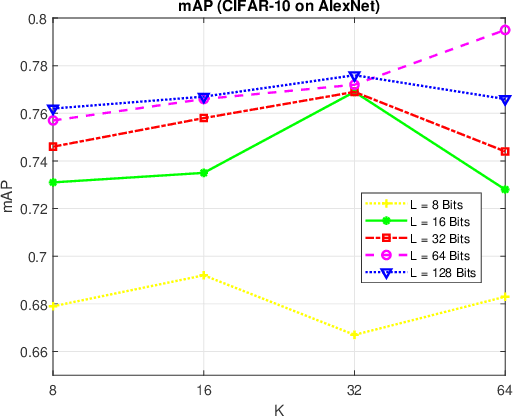
Image hash algorithms generate compact binary representations that can be quickly matched by Hamming distance, thus become an efficient solution for large-scale image retrieval. This paper proposes RV-SSDH, a deep image hash algorithm that incorporates the classical VLAD (vector of locally aggregated descriptors) architecture into neural networks. Specifically, a novel neural network component is formed by coupling a random VLAD layer with a latent hash layer through a transform layer. This component can be combined with convolutional layers to realize a hash algorithm. We implement RV-SSDH as a point-wise algorithm that can be efficiently trained by minimizing classification error and quantization loss. Comprehensive experiments show this new architecture significantly outperforms baselines such as NetVLAD and SSDH, and offers a cost-effective trade-off in the state-of-the-art. In addition, the proposed random VLAD layer leads to satisfactory accuracy with low complexity, thus shows promising potentials as an alternative to NetVLAD.
Mathematical Analysis on Out-of-Sample Extensions
Apr 19, 2018Let $X=\mathbf{X}\cup\mathbf{Z}$ be a data set in $\mathbb{R}^D$, where $\mathbf{X}$ is the training set and $\mathbf{Z}$ is the test one. Many unsupervised learning algorithms based on kernel methods have been developed to provide dimensionality reduction (DR) embedding for a given training set $\Phi: \mathbf{X} \to \mathbb{R}^d$ ( $d\ll D$) that maps the high-dimensional data $\mathbf{X}$ to its low-dimensional feature representation $\mathbf{Y}=\Phi(\mathbf{X})$. However, these algorithms do not straightforwardly produce DR of the test set $\mathbf{Z}$. An out-of-sample extension method provides DR of $\mathbf{Z}$ using an extension of the existent embedding $\Phi$, instead of re-computing the DR embedding for the whole set $X$. Among various out-of-sample DR extension methods, those based on Nystr\"{o}m approximation are very attractive. Many papers have developed such out-of-extension algorithms and shown their validity by numerical experiments. However, the mathematical theory for the DR extension still need further consideration. Utilizing the reproducing kernel Hilbert space (RKHS) theory, this paper develops a preliminary mathematical analysis on the out-of-sample DR extension operators. It treats an out-of-sample DR extension operator as an extension of the identity on the RKHS defined on $\mathbf{X}$. Then the Nystr\"{o}m-type DR extension turns out to be an orthogonal projection. In the paper, we also present the conditions for the exact DR extension and give the estimate for the error of the extension.