 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Models for Policy Refinement in StarCraft II
Feb 16, 2026Large Language Models (LLMs) have recently shown strong reasoning and generalization capabilities, motivating their use as decision-making policies in complex environments. StarCraft II (SC2), with its massive state-action space and partial observability, is a challenging testbed. However, existing LLM-based SC2 agents primarily focus on improving the policy itself and overlook integrating a learnable, action-conditioned transition model into the decision loop. To bridge this gap, we propose StarWM, the first world model for SC2 that predicts future observations under partial observability. To facilitate learning SC2's hybrid dynamics, we introduce a structured textual representation that factorizes observations into five semantic modules, and construct SC2-Dynamics-50k, the first instruction-tuning dataset for SC2 dynamics prediction. We further develop a multi-dimensional offline evaluation framework for predicted structured observations. Offline results show StarWM's substantial gains over zero-shot baselines, including nearly 60% improvements in resource prediction accuracy and self-side macro-situation consistency. Finally, we propose StarWM-Agent, a world-model-augmented decision system that integrates StarWM into a Generate--Simulate--Refine decision loop for foresight-driven policy refinement. Online evaluation against SC2's built-in AI demonstrates consistent improvements, yielding win-rate gains of 30%, 15%, and 30% against Hard (LV5), Harder (LV6), and VeryHard (LV7), respectively, alongside improved macro-management stability and tactical risk assessment.
Speech-Aware Long Context Pruning and Integration for Contextualized Automatic Speech Recognition
Nov 14, 2025Automatic speech recognition (ASR) systems have achieved remarkable performance in common conditions but often struggle to leverage long-context information in contextualized scenarios that require domain-specific knowledge, such as conference presentations. This challenge arises primarily due to constrained model context windows and the sparsity of relevant information within extensive contextual noise. To solve this, we propose the SAP$^{2}$ method, a novel framework that dynamically prunes and integrates relevant contextual keywords in two stages. Specifically, each stage leverages our proposed Speech-Driven Attention-based Pooling mechanism, enabling efficient compression of context embeddings while preserving speech-salient information. Experimental results demonstrate state-of-the-art performance of SAP$^{2}$ on the SlideSpeech and LibriSpeech datasets, achieving word error rates (WER) of 7.71% and 1.12%, respectively. On SlideSpeech, our method notably reduces biased keyword error rates (B-WER) by 41.1% compared to non-contextual baselines. SAP$^{2}$ also exhibits robust scalability, consistently maintaining performance under extensive contextual input conditions on both datasets.
Token-level Speaker Change Detection Using Speaker Difference and Speech Content via Continuous Integrate-and-fire
Nov 17, 2022In multi-talker scenarios such as meetings and conversations, speech processing systems are usually required to segment the audio and then transcribe each segmentation. These two stages are addressed separately by speaker change detection (SCD) and automatic speech recognition (ASR). Most previous SCD systems rely solely on speaker information and ignore the importance of speech content. In this paper, we propose a novel SCD system that considers both cues of speaker difference and speech content. These two cues are converted into token-level representations by the continuous integrate-and-fire (CIF) mechanism and then combined for detecting speaker changes on the token acoustic boundaries. We evaluate the performance of our approach on a public real-recorded meeting dataset, AISHELL-4. The experiment results show that our method outperforms a competitive frame-level baseline system by 2.45% equal coverage-purity (ECP). In addition, we demonstrate the importance of speech content and speaker difference to the SCD task, and the advantages of conducting SCD on the token acoustic boundaries compared with conducting SCD frame by frame.
Improving End-to-End Contextual Speech Recognition with Fine-grained Contextual Knowledge Selection
Jan 30, 2022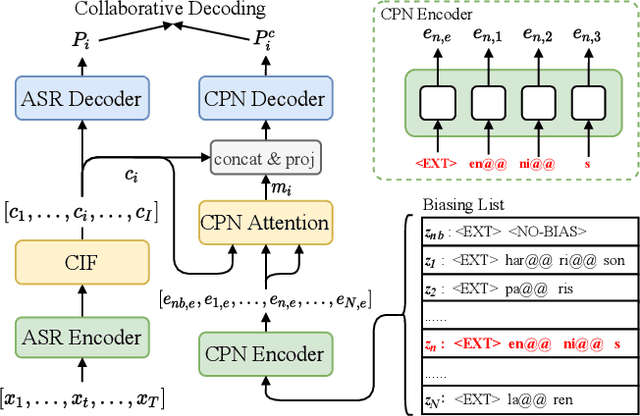
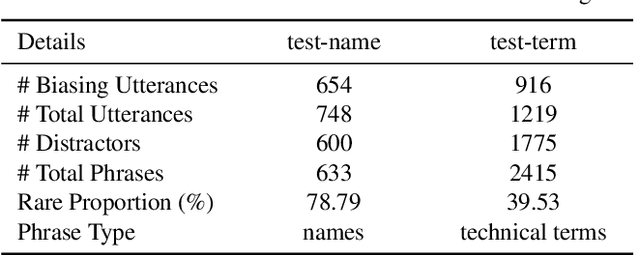
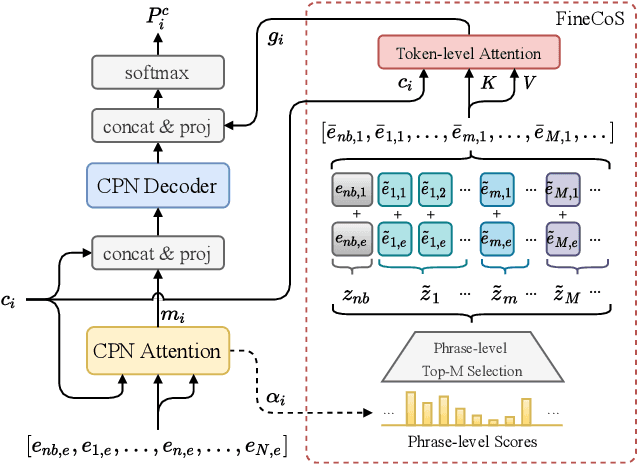
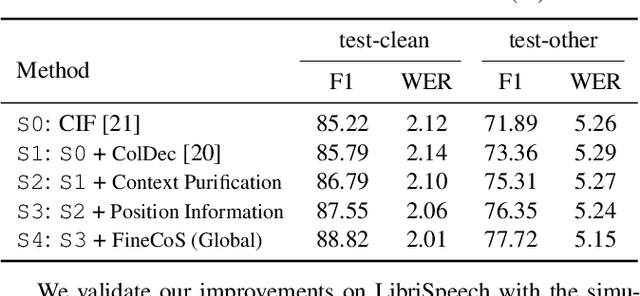
Nowadays, most methods in end-to-end contextual speech recognition bias the recognition process towards contextual knowledge. Since all-neural contextual biasing methods rely on phrase-level contextual modeling and attention-based relevance modeling, they may encounter confusion between similar context-specific phrases, which hurts predictions at the token level. In this work, we focus on mitigating confusion problems with fine-grained contextual knowledge selection (FineCoS). In FineCoS, we introduce fine-grained knowledge to reduce the uncertainty of token predictions. Specifically, we first apply phrase selection to narrow the range of phrase candidates, and then conduct token attention on the tokens in the selected phrase candidates. Moreover, we re-normalize the attention weights of most relevant phrases in inference to obtain more focused phrase-level contextual representations, and inject position information to better discriminate phrases or tokens. On LibriSpeech and an in-house 160,000-hour dataset, we explore the proposed methods based on a controllable all-neural biasing method, collaborative decoding (ColDec). The proposed methods provide at most 6.1% relative word error rate reduction on LibriSpeech and 16.4% relative character error rate reduction on the in-house dataset over ColDec.
OPT: Omni-Perception Pre-Trainer for Cross-Modal Understanding and Generation
Jul 06, 2021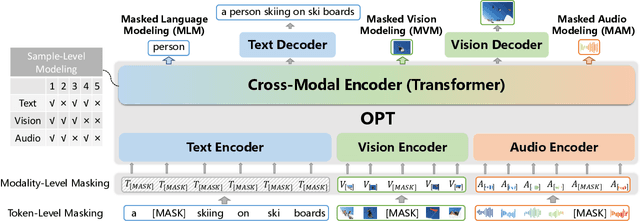
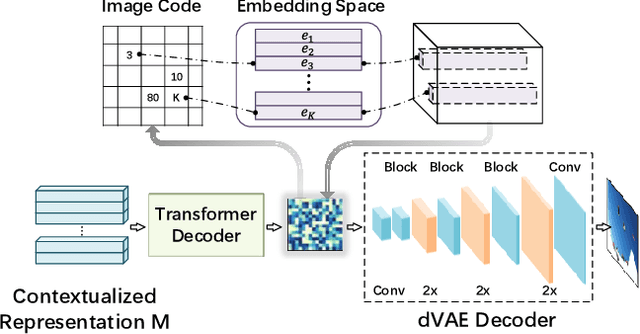

In this paper, we propose an Omni-perception Pre-Trainer (OPT) for cross-modal understanding and generation, by jointly modeling visual, text and audio resources. OPT is constructed in an encoder-decoder framework, including three single-modal encoders to generate token-based embeddings for each modality, a cross-modal encoder to encode the correlations among the three modalities, and two cross-modal decoders to generate text and image respectively. For the OPT's pre-training, we design a multi-task pretext learning scheme to model multi-modal resources from three different data granularities, \ie, token-, modality-, and sample-level modeling, through which OPT learns to align and translate among different modalities. The pre-training task is carried out on a large amount of image-text-audio triplets from Open Images. Experimental results show that OPT can learn strong image-text-audio multi-modal representations and achieve promising results on a variety of cross-modal understanding and generation tasks.
Long-Running Speech Recognizer:An End-to-End Multi-Task Learning Framework for Online ASR and VAD
Mar 02, 2021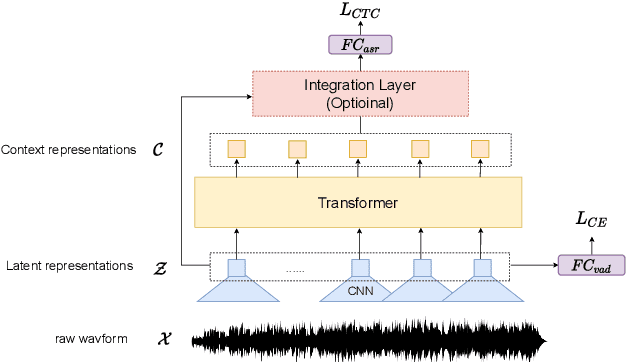
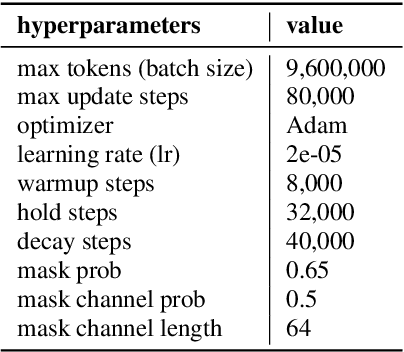
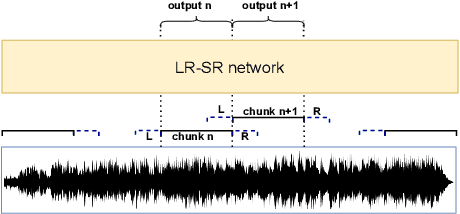

When we use End-to-end automatic speech recognition (E2E-ASR) system for real-world applications, a voice activity detection (VAD) system is usually needed to improve the performance and to reduce the computational cost by discarding non-speech parts in the audio. This paper presents a novel end-to-end (E2E), multi-task learning (MTL) framework that integrates ASR and VAD into one model. The proposed system, which we refer to as Long-Running Speech Recognizer (LR-SR), learns ASR and VAD jointly from two seperate task-specific datasets in the training stage. With the assistance of VAD, the ASR performance improves as its connectionist temporal classification (CTC) loss function can leverage the VAD alignment information. In the inference stage, the LR-SR system removes non-speech parts at low computational cost and recognizes speech parts with high robustness. Experimental results on segmented speech data show that the proposed MTL framework outperforms the baseline single-task learning (STL) framework in ASR task. On unsegmented speech data, we find that the LR-SR system outperforms the baseline ASR systems that build an extra GMM-based or DNN-based voice activity detector.
Efficiently Fusing Pretrained Acoustic and Linguistic Encoders for Low-resource Speech Recognition
Jan 24, 2021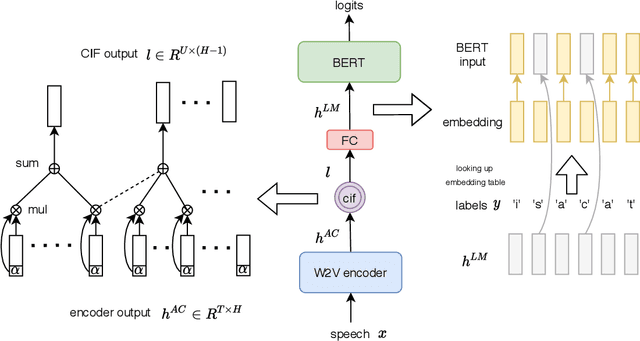
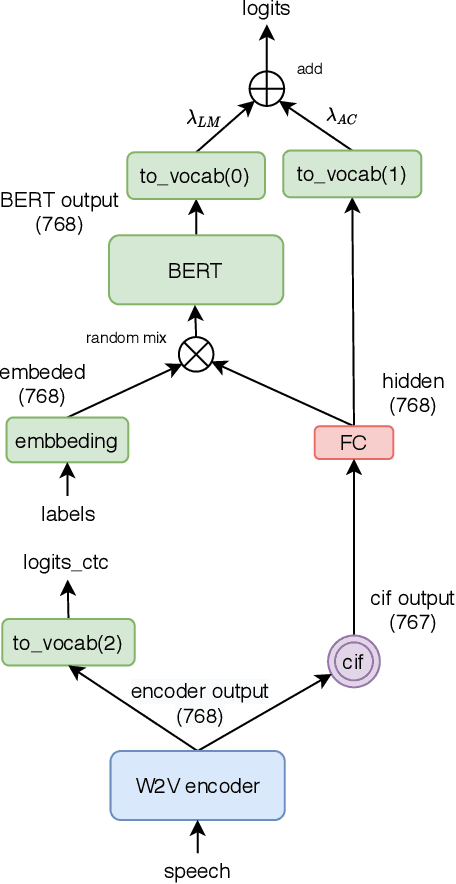
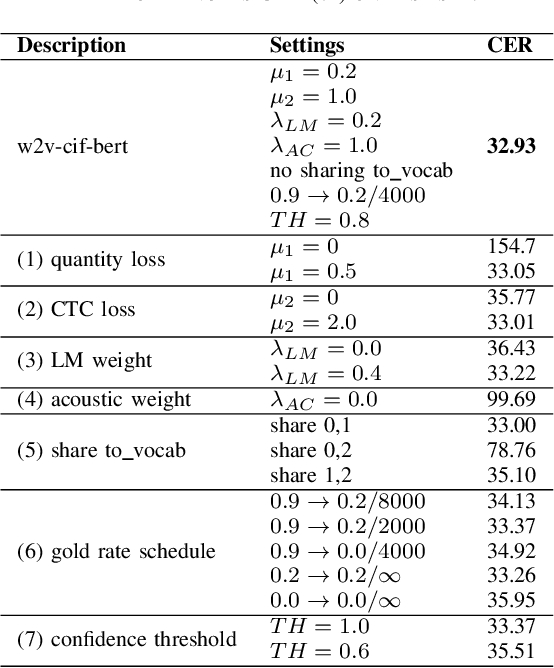
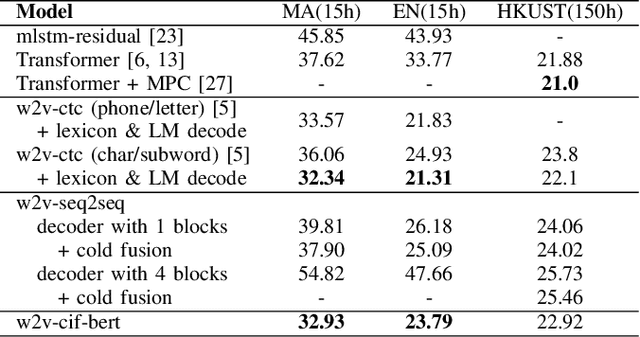
End-to-end models have achieved impressive results on the task of automatic speech recognition (ASR). For low-resource ASR tasks, however, labeled data can hardly satisfy the demand of end-to-end models. Self-supervised acoustic pre-training has already shown its amazing ASR performance, while the transcription is still inadequate for language modeling in end-to-end models. In this work, we fuse a pre-trained acoustic encoder (wav2vec2.0) and a pre-trained linguistic encoder (BERT) into an end-to-end ASR model. The fused model only needs to learn the transfer from speech to language during fine-tuning on limited labeled data. The length of the two modalities is matched by a monotonic attention mechanism without additional parameters. Besides, a fully connected layer is introduced for the hidden mapping between modalities. We further propose a scheduled fine-tuning strategy to preserve and utilize the text context modeling ability of the pre-trained linguistic encoder. Experiments show our effective utilizing of pre-trained modules. Our model achieves better recognition performance on CALLHOME corpus (15 hours) than other end-to-end models.
Applying Wav2vec2.0 to Speech Recognition in Various Low-resource Languages
Jan 17, 2021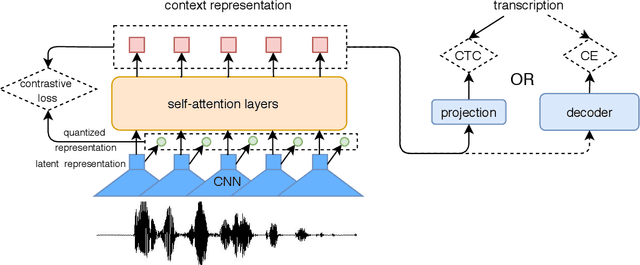
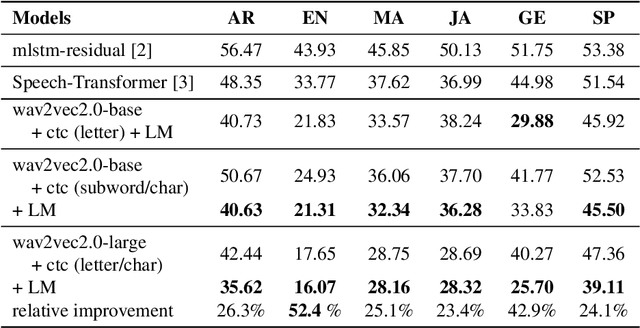
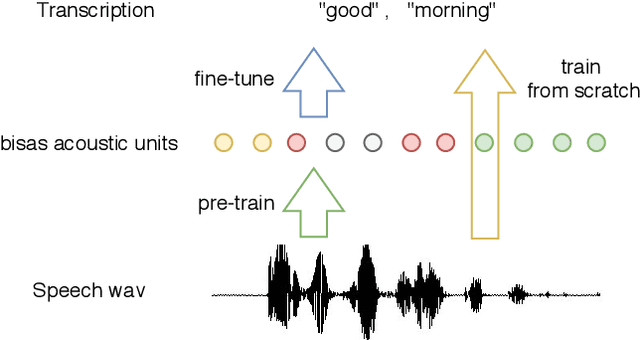
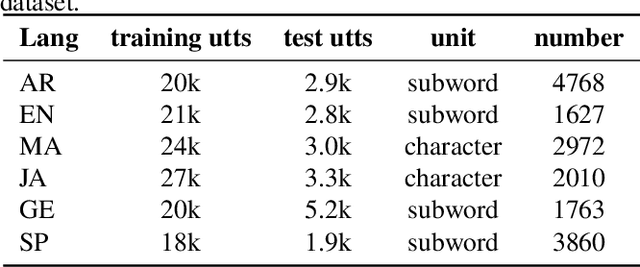
There are several domains that own corresponding widely used feature extractors, such as ResNet, BERT, and GPT-x. These models are usually pre-trained on large amounts of unlabeled data by self-supervision and can be effectively applied to downstream tasks. In the speech domain, wav2vec2.0 starts to show its powerful representation ability and feasibility of ultra-low resource speech recognition on the Librispeech corpus, which belongs to the audiobook domain. However, wav2vec2.0 has not been examined on real spoken scenarios and languages other than English. To verify its universality over languages, we apply pre-trained models to solve low-resource speech recognition tasks in various spoken languages. We achieve more than 20% relative improvements in six languages compared with previous work. Among these languages, English achieves a gain of 52.4%. Moreover, using coarse-grained modeling units, such as subword or character, achieves better results than fine-grained modeling units, such as phone or letter.
Exploring wav2vec 2.0 on speaker verification and language identification
Jan 14, 2021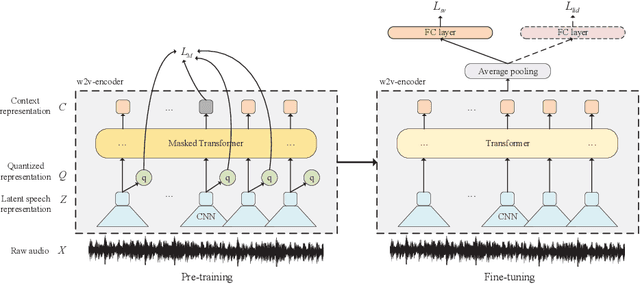



Wav2vec 2.0 is a recently proposed self-supervised framework for speech representation learning. It follows a two-stage training process of pre-training and fine-tuning, and performs well in speech recognition tasks especially ultra-low resource cases. In this work, we attempt to extend self-supervised framework to speaker verification and language identification. First, we use some preliminary experiments to indicate that wav2vec 2.0 can capture the information about the speaker and language. Then we demonstrate the effectiveness of wav2vec 2.0 on the two tasks respectively. For speaker verification, we obtain a new state-of-the-art result, Equal Error Rate (EER) of 3.61% on the VoxCeleb1 dataset. For language identification, we obtain an EER of 12.02% on 1 second condition and an EER of 3.47% on full-length condition of the AP17-OLR dataset. Finally, we utilize one model to achieve the unified modeling by the multi-task learning for the two tasks.
cif-based collaborative decoding for end-to-end contextual speech recognition
Dec 17, 2020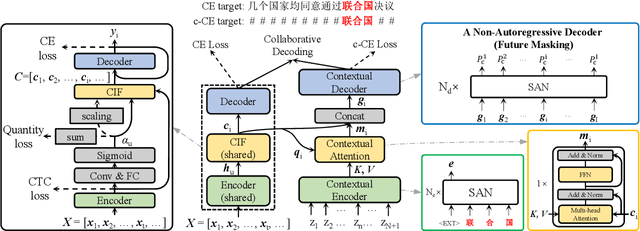
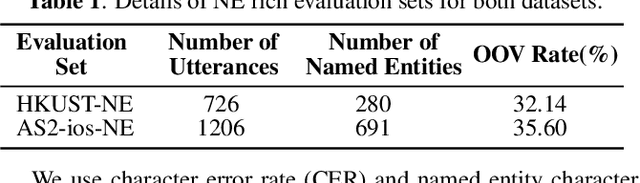
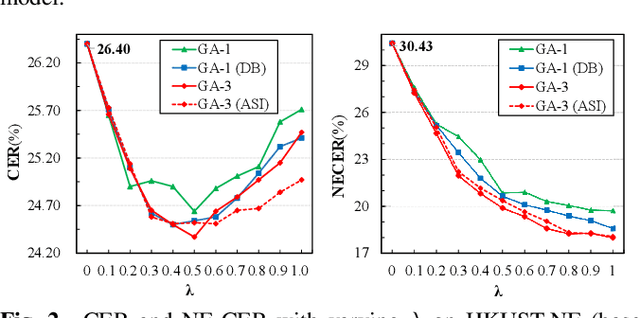
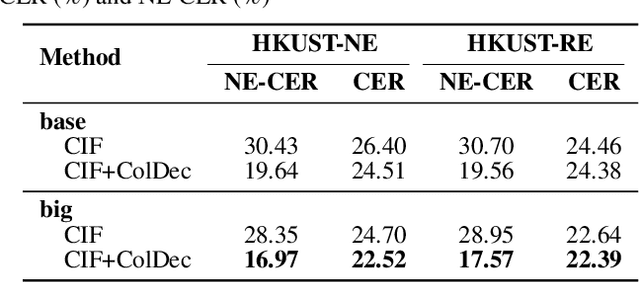
End-to-end (E2E) models have achieved promising results on multiple speech recognition benchmarks, and shown the potential to become the mainstream. However, the unified structure and the E2E training hamper injecting contextual information into them for contextual biasing. Though contextual LAS (CLAS) gives an excellent all-neural solution, the degree of biasing to given context information is not explicitly controllable. In this paper, we focus on incorporating context information into the continuous integrate-and-fire (CIF) based model that supports contextual biasing in a more controllable fashion. Specifically, an extra context processing network is introduced to extract contextual embeddings, integrate acoustically relevant context information and decode the contextual output distribution, thus forming a collaborative decoding with the decoder of the CIF-based model. Evaluated on the named entity rich evaluation sets of HKUST/AISHELL-2, our method brings relative character error rate (CER) reduction of 8.83%/21.13% and relative named entity character error rate (NE-CER) reduction of 40.14%/51.50% when compared with a strong baseline. Besides, it keeps the performance on original evaluation set without degradation.