 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Running Speech Recognizer:An End-to-End Multi-Task Learning Framework for Online ASR and VAD
Paper and Code
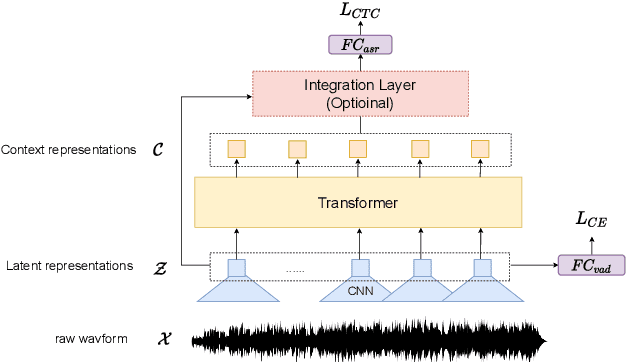
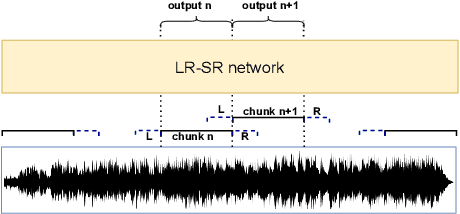

When we use End-to-end automatic speech recognition (E2E-ASR) system for real-world applications, a voice activity detection (VAD) system is usually needed to improve the performance and to reduce the computational cost by discarding non-speech parts in the audio. This paper presents a novel end-to-end (E2E), multi-task learning (MTL) framework that integrates ASR and VAD into one model. The proposed system, which we refer to as Long-Running Speech Recognizer (LR-SR), learns ASR and VAD jointly from two seperate task-specific datasets in the training stage. With the assistance of VAD, the ASR performance improves as its connectionist temporal classification (CTC) loss function can leverage the VAD alignment information. In the inference stage, the LR-SR system removes non-speech parts at low computational cost and recognizes speech parts with high robustness. Experimental results on segmented speech data show that the proposed MTL framework outperforms the baseline single-task learning (STL) framework in ASR task. On unsegmented speech data, we find that the LR-SR system outperforms the baseline ASR systems that build an extra GMM-based or DNN-based voice activity detector.