 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecif-based collaborative decoding for end-to-end contextual speech recognition
Paper and Code
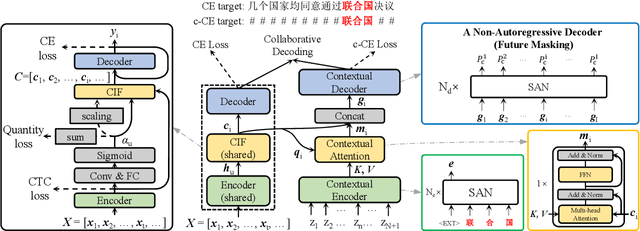
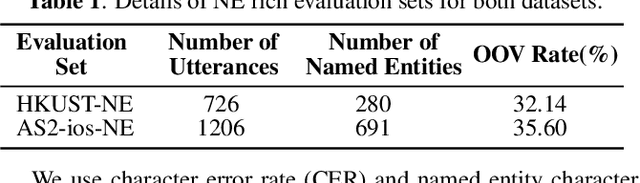
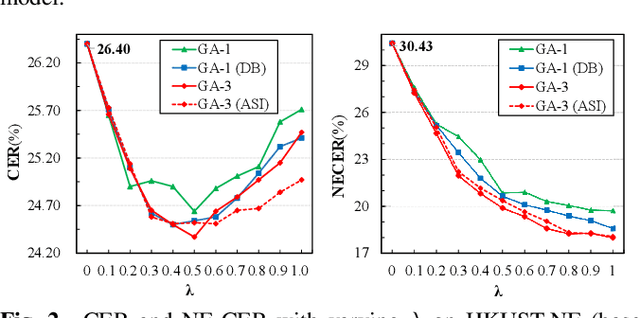
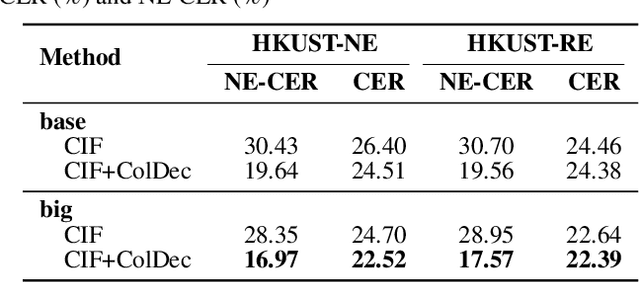
End-to-end (E2E) models have achieved promising results on multiple speech recognition benchmarks, and shown the potential to become the mainstream. However, the unified structure and the E2E training hamper injecting contextual information into them for contextual biasing. Though contextual LAS (CLAS) gives an excellent all-neural solution, the degree of biasing to given context information is not explicitly controllable. In this paper, we focus on incorporating context information into the continuous integrate-and-fire (CIF) based model that supports contextual biasing in a more controllable fashion. Specifically, an extra context processing network is introduced to extract contextual embeddings, integrate acoustically relevant context information and decode the contextual output distribution, thus forming a collaborative decoding with the decoder of the CIF-based model. Evaluated on the named entity rich evaluation sets of HKUST/AISHELL-2, our method brings relative character error rate (CER) reduction of 8.83%/21.13% and relative named entity character error rate (NE-CER) reduction of 40.14%/51.50% when compared with a strong baseline. Besides, it keeps the performance on original evaluation set without degradation.