 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEST-RQ: Next Token Prediction for Speech Self-Supervised Pre-Training
Sep 13, 2024



Speech self-supervised pre-training can effectively improve the performance of downstream tasks. However, previous self-supervised learning (SSL) methods for speech, such as HuBERT and BEST-RQ, focus on utilizing non-causal encoders with bidirectional context, and lack sufficient support for downstream streaming models. To address this issue, we introduce the next token prediction based speech pre-training method with random-projection quantizer (NEST-RQ). NEST-RQ employs causal encoders with only left context and uses next token prediction (NTP) as the training task. On the large-scale dataset, compared to BEST-RQ, the proposed NEST-RQ achieves comparable performance on non-streaming automatic speech recognition (ASR) and better performance on streaming ASR. We also conduct analytical experiments in terms of the future context size of streaming ASR, the codebook quality of SSL and the model size of the encoder. In summary, the paper demonstrates the feasibility of the NTP in speech SSL and provides empirical evidence and insights for speech SSL research.
Seed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition
Jul 05, 2024



Modern automatic speech recognition (ASR) model is required to accurately transcribe diverse speech signals (from different domains, languages, accents, etc) given the specific contextual information in various application scenarios. Classic end-to-end models fused with extra language models perform well, but mainly in data matching scenarios and are gradually approaching a bottleneck. In this work, we introduce Seed-ASR, a large language model (LLM) based speech recognition model. Seed-ASR is developed based on the framework of audio conditioned LLM (AcLLM), leveraging the capabilities of LLMs by inputting continuous speech representations together with contextual information into the LLM. Through stage-wise large-scale training and the elicitation of context-aware capabilities in LLM, Seed-ASR demonstrates significant improvement over end-to-end models on comprehensive evaluation sets, including multiple domains, accents/dialects and languages. Additionally, Seed-ASR can be further deployed to support specific needs in various scenarios without requiring extra language models. Compared to recently released large ASR models, Seed-ASR achieves 10%-40% reduction in word (or character, for Chinese) error rates on Chinese and English public test sets, further demonstrating its powerful performance.
SA-SOT: Speaker-Aware Serialized Output Training for Multi-Talker ASR
Mar 04, 2024
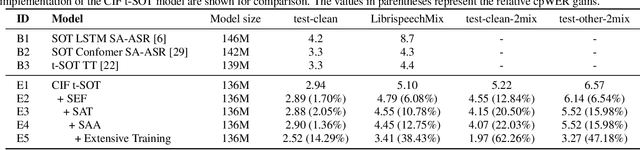
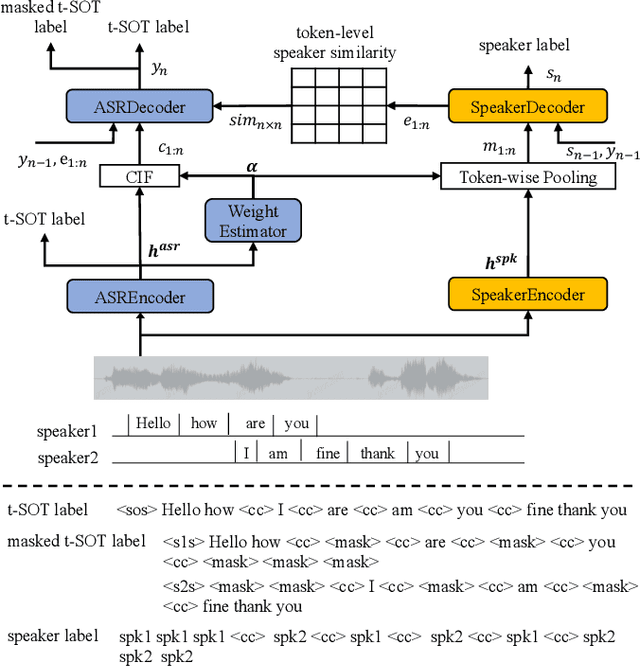
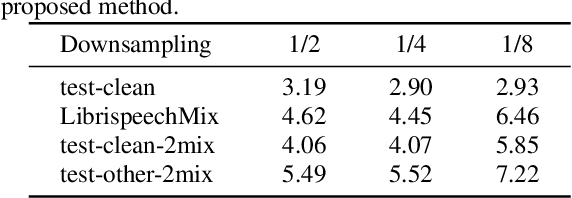
Multi-talker automatic speech recognition plays a crucial role in scenarios involving multi-party interactions, such as meetings and conversations. Due to its inherent complexity, this task has been receiving increasing attention. Notably, the serialized output training (SOT) stands out among various approaches because of its simplistic architecture and exceptional performance. However, the frequent speaker changes in token-level SOT (t-SOT) present challenges for the autoregressive decoder in effectively utilizing context to predict output sequences. To address this issue, we introduce a masked t-SOT label, which serves as the cornerstone of an auxiliary training loss. Additionally, we utilize a speaker similarity matrix to refine the self-attention mechanism of the decoder. This strategic adjustment enhances contextual relationships within the same speaker's tokens while minimizing interactions between different speakers' tokens. We denote our method as speaker-aware SOT (SA-SOT). Experiments on the Librispeech datasets demonstrate that our SA-SOT obtains a relative cpWER reduction ranging from 12.75% to 22.03% on the multi-talker test sets. Furthermore, with more extensive training, our method achieves an impressive cpWER of 3.41%, establishing a new state-of-the-art result on the LibrispeechMix dataset.
CIF-PT: Bridging Speech and Text Representations for Spoken Language Understanding via Continuous Integrate-and-Fire Pre-Training
May 27, 2023



Speech or text representation generated by pre-trained models contains modal-specific information that could be combined for benefiting spoken language understanding (SLU) tasks. In this work, we propose a novel pre-training paradigm termed Continuous Integrate-and-Fire Pre-Training (CIF-PT). It relies on a simple but effective frame-to-token alignment: continuous integrate-and-fire (CIF) to bridge the representations between speech and text. It jointly performs speech-to-text training and language model distillation through CIF as the pre-training (PT). Evaluated on SLU benchmark SLURP dataset, CIF-PT outperforms the state-of-the-art model by 1.94% of accuracy and 2.71% of SLU-F1 on the tasks of intent classification and slot filling, respectively. We also observe the cross-modal representation extracted by CIF-PT obtains better performance than other neural interfaces for the tasks of SLU, including the dominant speech representation learned from self-supervised pre-training.
Token-level Speaker Change Detection Using Speaker Difference and Speech Content via Continuous Integrate-and-fire
Nov 17, 2022In multi-talker scenarios such as meetings and conversations, speech processing systems are usually required to segment the audio and then transcribe each segmentation. These two stages are addressed separately by speaker change detection (SCD) and automatic speech recognition (ASR). Most previous SCD systems rely solely on speaker information and ignore the importance of speech content. In this paper, we propose a novel SCD system that considers both cues of speaker difference and speech content. These two cues are converted into token-level representations by the continuous integrate-and-fire (CIF) mechanism and then combined for detecting speaker changes on the token acoustic boundaries. We evaluate the performance of our approach on a public real-recorded meeting dataset, AISHELL-4. The experiment results show that our method outperforms a competitive frame-level baseline system by 2.45% equal coverage-purity (ECP). In addition, we demonstrate the importance of speech content and speaker difference to the SCD task, and the advantages of conducting SCD on the token acoustic boundaries compared with conducting SCD frame by frame.
Sequence-level Speaker Change Detection with Difference-based Continuous Integrate-and-fire
Jun 27, 2022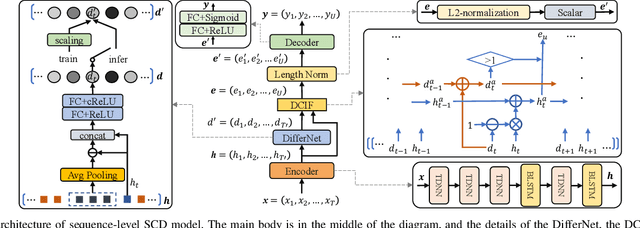
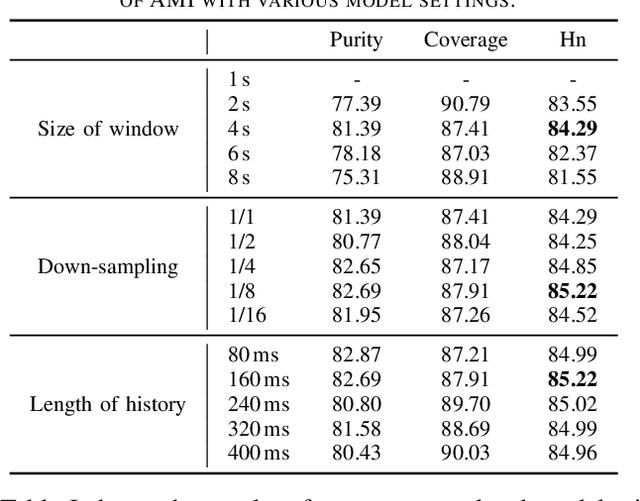
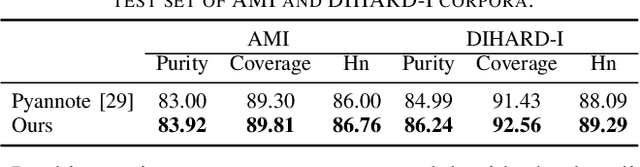
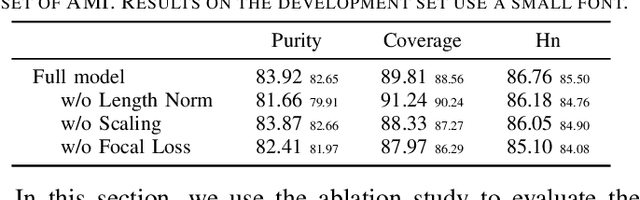
Speaker change detection is an important task in multi-party interactions such as meetings and conversations. In this paper, we address the speaker change detection task from the perspective of sequence transduction. Specifically, we propose a novel encoder-decoder framework that directly converts the input feature sequence to the speaker identity sequence. The difference-based continuous integrate-and-fire mechanism is designed to support this framework. It detects speaker changes by integrating the speaker difference between the encoder outputs frame-by-frame and transfers encoder outputs to segment-level speaker embeddings according to the detected speaker changes. The whole framework is supervised by the speaker identity sequence, a weaker label than the precise speaker change points. The experiments on the AMI and DIHARD-I corpora show that our sequence-level method consistently outperforms a strong frame-level baseline that uses the precise speaker change labels.
Improving End-to-End Contextual Speech Recognition with Fine-grained Contextual Knowledge Selection
Jan 30, 2022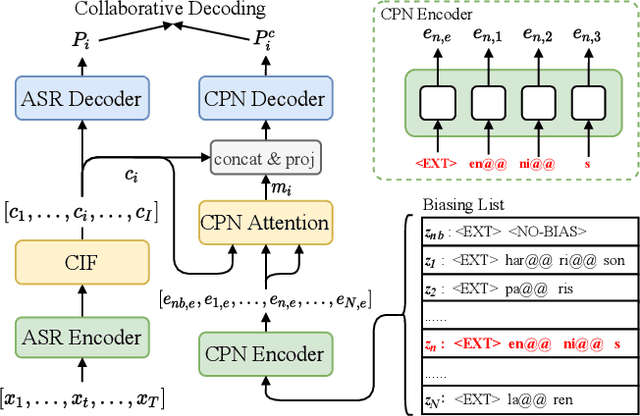
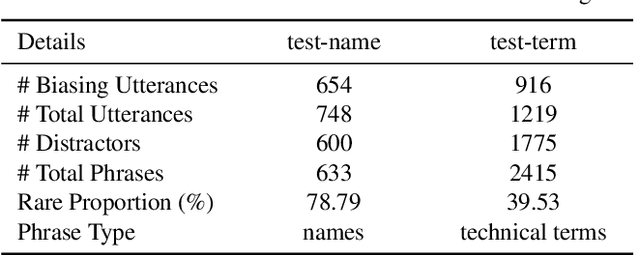
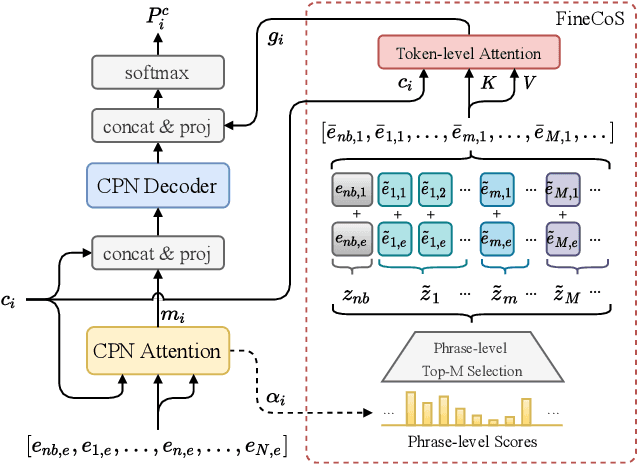
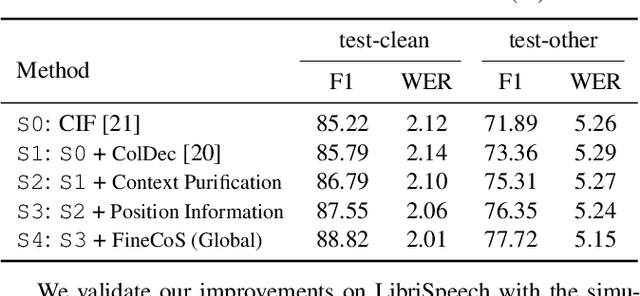
Nowadays, most methods in end-to-end contextual speech recognition bias the recognition process towards contextual knowledge. Since all-neural contextual biasing methods rely on phrase-level contextual modeling and attention-based relevance modeling, they may encounter confusion between similar context-specific phrases, which hurts predictions at the token level. In this work, we focus on mitigating confusion problems with fine-grained contextual knowledge selection (FineCoS). In FineCoS, we introduce fine-grained knowledge to reduce the uncertainty of token predictions. Specifically, we first apply phrase selection to narrow the range of phrase candidates, and then conduct token attention on the tokens in the selected phrase candidates. Moreover, we re-normalize the attention weights of most relevant phrases in inference to obtain more focused phrase-level contextual representations, and inject position information to better discriminate phrases or tokens. On LibriSpeech and an in-house 160,000-hour dataset, we explore the proposed methods based on a controllable all-neural biasing method, collaborative decoding (ColDec). The proposed methods provide at most 6.1% relative word error rate reduction on LibriSpeech and 16.4% relative character error rate reduction on the in-house dataset over ColDec.
cif-based collaborative decoding for end-to-end contextual speech recognition
Dec 17, 2020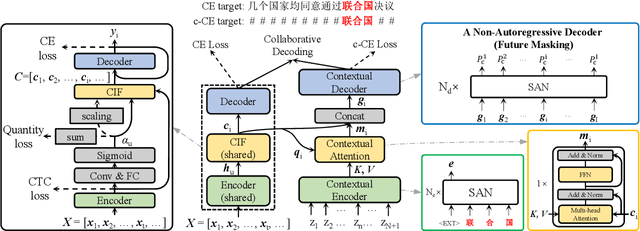
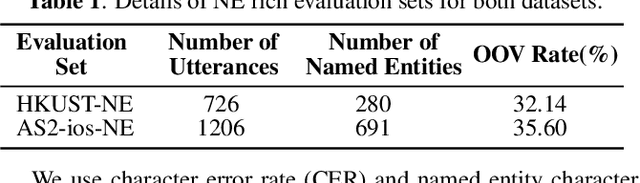
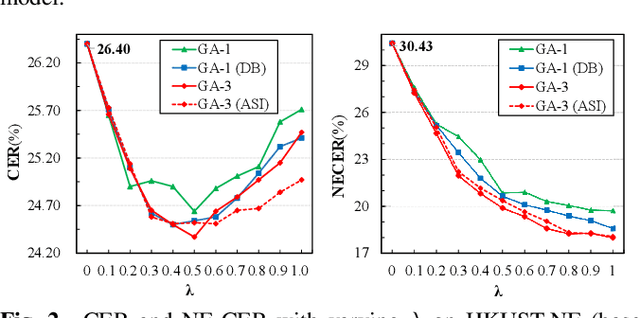
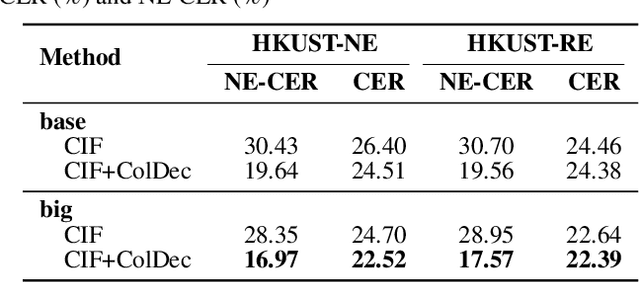
End-to-end (E2E) models have achieved promising results on multiple speech recognition benchmarks, and shown the potential to become the mainstream. However, the unified structure and the E2E training hamper injecting contextual information into them for contextual biasing. Though contextual LAS (CLAS) gives an excellent all-neural solution, the degree of biasing to given context information is not explicitly controllable. In this paper, we focus on incorporating context information into the continuous integrate-and-fire (CIF) based model that supports contextual biasing in a more controllable fashion. Specifically, an extra context processing network is introduced to extract contextual embeddings, integrate acoustically relevant context information and decode the contextual output distribution, thus forming a collaborative decoding with the decoder of the CIF-based model. Evaluated on the named entity rich evaluation sets of HKUST/AISHELL-2, our method brings relative character error rate (CER) reduction of 8.83%/21.13% and relative named entity character error rate (NE-CER) reduction of 40.14%/51.50% when compared with a strong baseline. Besides, it keeps the performance on original evaluation set without degradation.
A Comparison of Label-Synchronous and Frame-Synchronous End-to-End Models for Speech Recognition
May 25, 2020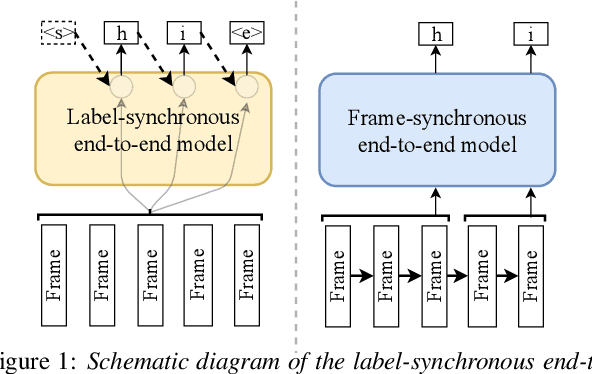

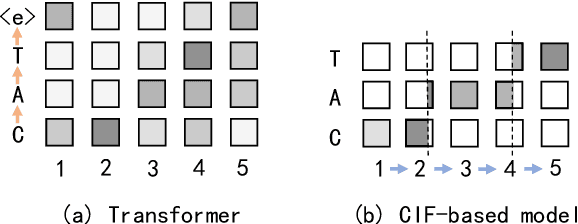
End-to-end models are gaining wider attention in the field of automatic speech recognition (ASR). One of their advantages is the simplicity of building that directly recognizes the speech frame sequence into the text label sequence by neural networks. According to the driving end in the recognition process, end-to-end ASR models could be categorized into two types: label-synchronous and frame-synchronous, each of which has unique model behaviour and characteristic. In this work, we make a detailed comparison on a representative label-synchronous model (transformer) and a soft frame-synchronous model (continuous integrate-and-fire (CIF) based model). The results on three public dataset and a large-scale dataset with 12000 hours of training data show that the two types of models have respective advantages that are consistent with their synchronous mode.
CIF: Continuous Integrate-and-Fire for End-to-End Speech Recognition
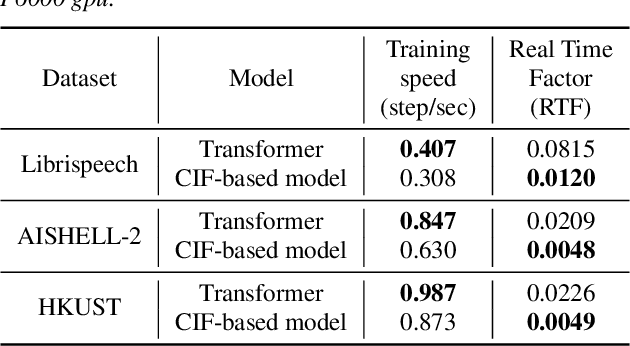
May 27, 2019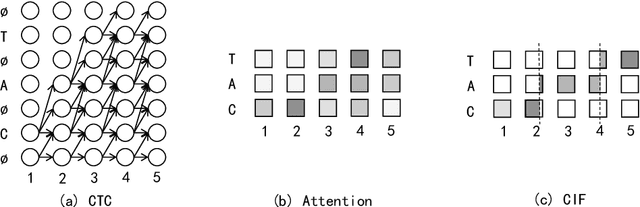

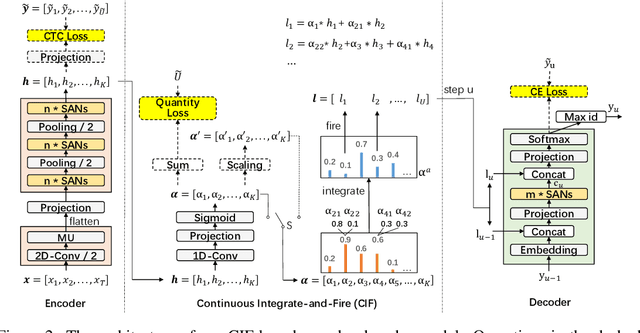
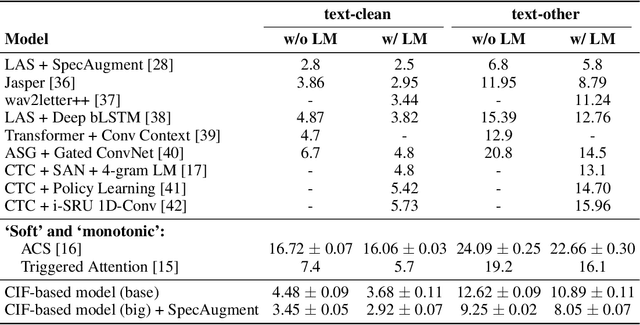
Automatic speech recognition (ASR) system is undergoing an exciting pathway to be more simplified and practical with the spring up of various end-to-end models. However, the mainstream of them neglects the positioning of token boundaries from continuous speech, which is considered crucial in human language learning and instant speech recognition. In this work, we propose Continuous Integrate-and-Fire (CIF), a 'soft' and 'monotonic' acoustic-to-linguistic alignment mechanism that addresses the boundary positioning by simulating the integrate-and-fire neuron model using continuous functions under the encoder-decoder framework. As the connection between the encoder and decoder, the CIF forwardly integrates the information in the encoded acoustic representations to determine a boundary and instantly fires the integrated information to the decoder once a boundary is located. Multiple effective strategies are introduced to the CIF-based model to alleviate the problems brought by the inaccurate positioning. Besides, multi-task learning is performed during training and an external language model is incorporated during inference to further boost the model performance. Evaluated on multiple ASR datasets that cover different languages and speech types, the CIF-based model shows stable convergence and competitive performance. Especially, it achieves a word error rate (WER) of 3.70% on the test-clean of Librispeech.