 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEST-RQ: Next Token Prediction for Speech Self-Supervised Pre-Training
Sep 13, 2024



Speech self-supervised pre-training can effectively improve the performance of downstream tasks. However, previous self-supervised learning (SSL) methods for speech, such as HuBERT and BEST-RQ, focus on utilizing non-causal encoders with bidirectional context, and lack sufficient support for downstream streaming models. To address this issue, we introduce the next token prediction based speech pre-training method with random-projection quantizer (NEST-RQ). NEST-RQ employs causal encoders with only left context and uses next token prediction (NTP) as the training task. On the large-scale dataset, compared to BEST-RQ, the proposed NEST-RQ achieves comparable performance on non-streaming automatic speech recognition (ASR) and better performance on streaming ASR. We also conduct analytical experiments in terms of the future context size of streaming ASR, the codebook quality of SSL and the model size of the encoder. In summary, the paper demonstrates the feasibility of the NTP in speech SSL and provides empirical evidence and insights for speech SSL research.
Seed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition
Jul 05, 2024



Modern automatic speech recognition (ASR) model is required to accurately transcribe diverse speech signals (from different domains, languages, accents, etc) given the specific contextual information in various application scenarios. Classic end-to-end models fused with extra language models perform well, but mainly in data matching scenarios and are gradually approaching a bottleneck. In this work, we introduce Seed-ASR, a large language model (LLM) based speech recognition model. Seed-ASR is developed based on the framework of audio conditioned LLM (AcLLM), leveraging the capabilities of LLMs by inputting continuous speech representations together with contextual information into the LLM. Through stage-wise large-scale training and the elicitation of context-aware capabilities in LLM, Seed-ASR demonstrates significant improvement over end-to-end models on comprehensive evaluation sets, including multiple domains, accents/dialects and languages. Additionally, Seed-ASR can be further deployed to support specific needs in various scenarios without requiring extra language models. Compared to recently released large ASR models, Seed-ASR achieves 10%-40% reduction in word (or character, for Chinese) error rates on Chinese and English public test sets, further demonstrating its powerful performance.
Language Adaptive Cross-lingual Speech Representation Learning with Sparse Sharing Sub-networks
Mar 09, 2022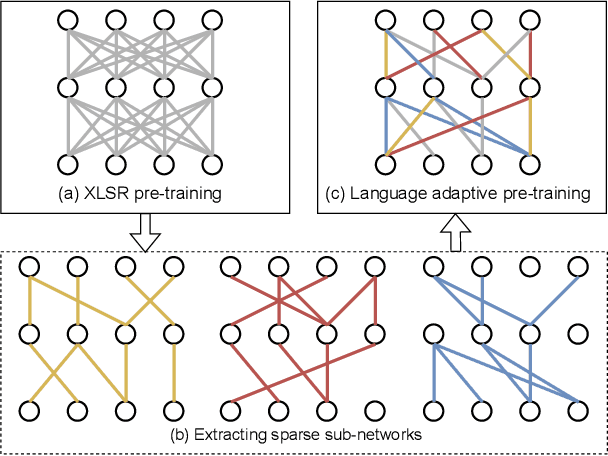
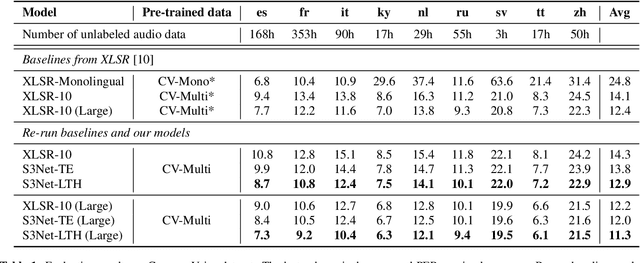
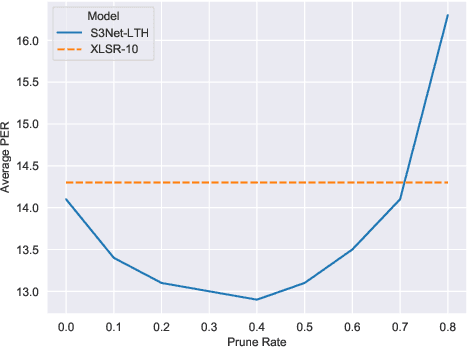
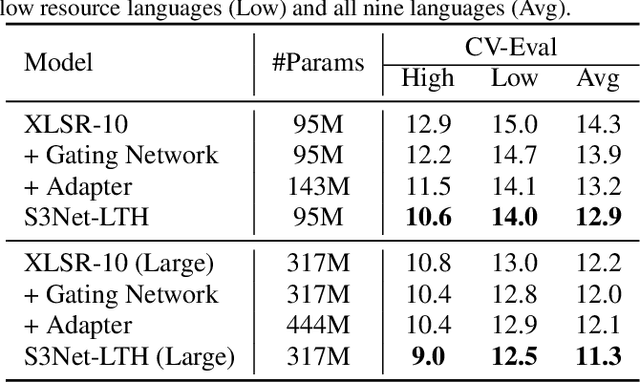
Unsupervised cross-lingual speech representation learning (XLSR) has recently shown promising results in speech recognition by leveraging vast amounts of unlabeled data across multiple languages. However, standard XLSR model suffers from language interference problem due to the lack of language specific modeling ability. In this work, we investigate language adaptive training on XLSR models. More importantly, we propose a novel language adaptive pre-training approach based on sparse sharing sub-networks. It makes room for language specific modeling by pruning out unimportant parameters for each language, without requiring any manually designed language specific component. After pruning, each language only maintains a sparse sub-network, while the sub-networks are partially shared with each other. Experimental results on a downstream multilingual speech recognition task show that our proposed method significantly outperforms baseline XLSR models on both high resource and low resource languages. Besides, our proposed method consistently outperforms other adaptation methods and requires fewer parameters.