 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
Seed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition
Jul 05, 2024



Modern automatic speech recognition (ASR) model is required to accurately transcribe diverse speech signals (from different domains, languages, accents, etc) given the specific contextual information in various application scenarios. Classic end-to-end models fused with extra language models perform well, but mainly in data matching scenarios and are gradually approaching a bottleneck. In this work, we introduce Seed-ASR, a large language model (LLM) based speech recognition model. Seed-ASR is developed based on the framework of audio conditioned LLM (AcLLM), leveraging the capabilities of LLMs by inputting continuous speech representations together with contextual information into the LLM. Through stage-wise large-scale training and the elicitation of context-aware capabilities in LLM, Seed-ASR demonstrates significant improvement over end-to-end models on comprehensive evaluation sets, including multiple domains, accents/dialects and languages. Additionally, Seed-ASR can be further deployed to support specific needs in various scenarios without requiring extra language models. Compared to recently released large ASR models, Seed-ASR achieves 10%-40% reduction in word (or character, for Chinese) error rates on Chinese and English public test sets, further demonstrating its powerful performance.
Revisiting Interpolation Augmentation for Speech-to-Text Generation
Jun 22, 2024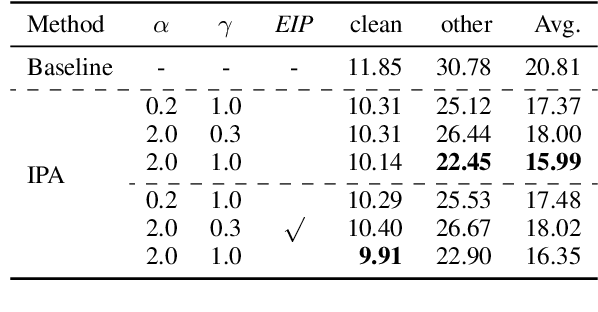


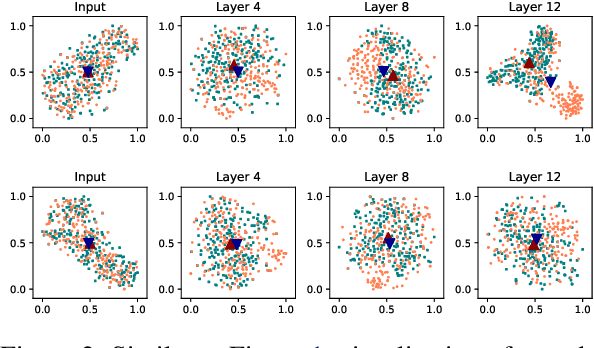
Speech-to-text (S2T) generation systems frequently face challenges in low-resource scenarios, primarily due to the lack of extensive labeled datasets. One emerging solution is constructing virtual training samples by interpolating inputs and labels, which has notably enhanced system generalization in other domains. Despite its potential, this technique's application in S2T tasks has remained under-explored. In this paper, we delve into the utility of interpolation augmentation, guided by several pivotal questions. Our findings reveal that employing an appropriate strategy in interpolation augmentation significantly enhances performance across diverse tasks, architectures, and data scales, offering a promising avenue for more robust S2T systems in resource-constrained settings.
Speech Translation with Large Language Models: An Industrial Practice
Dec 21, 2023



Given the great success of large language models (LLMs) across various tasks, in this paper, we introduce LLM-ST, a novel and effective speech translation model constructed upon a pre-trained LLM. By integrating the large language model (LLM) with a speech encoder and employing multi-task instruction tuning, LLM-ST can produce accurate timestamped transcriptions and translations, even from long audio inputs. Furthermore, our findings indicate that the implementation of Chain-of-Thought (CoT) prompting can yield advantages in the context of LLM-ST. Through rigorous experimentation on English and Chinese datasets, we showcase the exceptional performance of LLM-ST, establishing a new benchmark in the field of speech translation. Demo: https://speechtranslation.github.io/llm-st/.
Bridging the Gaps of Both Modality and Language: Synchronous Bilingual CTC for Speech Translation and Speech Recognition
Sep 21, 2023



In this study, we present synchronous bilingual Connectionist Temporal Classification (CTC), an innovative framework that leverages dual CTC to bridge the gaps of both modality and language in the speech translation (ST) task. Utilizing transcript and translation as concurrent objectives for CTC, our model bridges the gap between audio and text as well as between source and target languages. Building upon the recent advances in CTC application, we develop an enhanced variant, BiL-CTC+, that establishes new state-of-the-art performances on the MuST-C ST benchmarks under resource-constrained scenarios. Intriguingly, our method also yields significant improvements in speech recognition performance, revealing the effect of cross-lingual learning on transcription and demonstrating its broad applicability. The source code is available at https://github.com/xuchennlp/S2T.
Recent Advances in Direct Speech-to-text Translation
Jun 20, 2023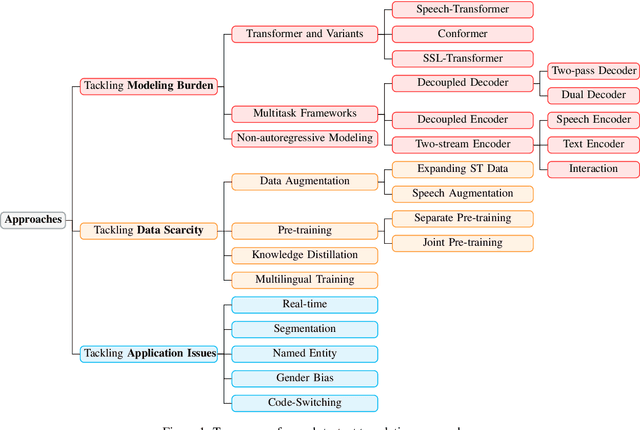
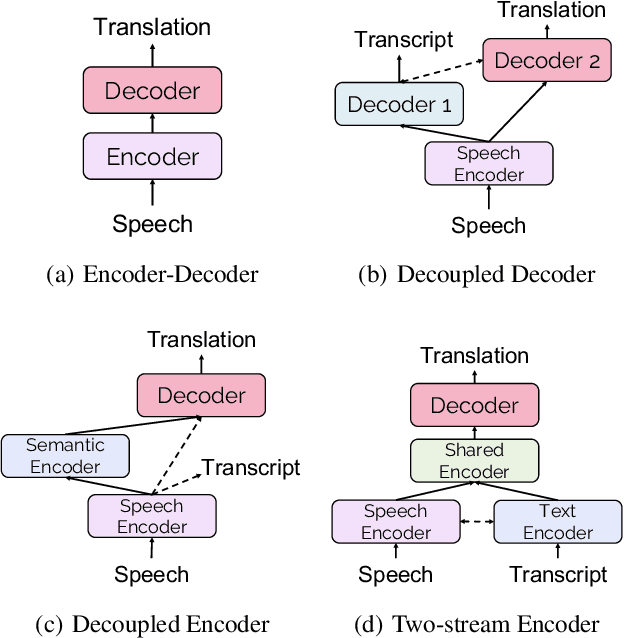
Recently, speech-to-text translation has attracted more and more attention and many studies have emerged rapidly. In this paper, we present a comprehensive survey on direct speech translation aiming to summarize the current state-of-the-art techniques. First, we categorize the existing research work into three directions based on the main challenges -- modeling burden, data scarcity, and application issues. To tackle the problem of modeling burden, two main structures have been proposed, encoder-decoder framework (Transformer and the variants) and multitask frameworks. For the challenge of data scarcity, recent work resorts to many sophisticated techniques, such as data augmentation, pre-training, knowledge distillation, and multilingual modeling. We analyze and summarize the application issues, which include real-time, segmentation, named entity, gender bias, and code-switching. Finally, we discuss some promising directions for future work.
MOSPC: MOS Prediction Based on Pairwise Comparison
Jun 18, 2023



As a subjective metric to evaluate the quality of synthesized speech, Mean opinion score~(MOS) usually requires multiple annotators to score the same speech. Such an annotation approach requires a lot of manpower and is also time-consuming. MOS prediction model for automatic evaluation can significantly reduce labor cost. In previous works, it is difficult to accurately rank the quality of speech when the MOS scores are close. However, in practical applications, it is more important to correctly rank the quality of synthesis systems or sentences than simply predicting MOS scores. Meanwhile, as each annotator scores multiple audios during annotation, the score is probably a relative value based on the first or the first few speech scores given by the annotator. Motivated by the above two points, we propose a general framework for MOS prediction based on pair comparison (MOSPC), and we utilize C-Mixup algorithm to enhance the generalization performance of MOSPC. The experiments on BVCC and VCC2018 show that our framework outperforms the baselines on most of the correlation coefficient metrics, especially on the metric KTAU related to quality ranking. And our framework also surpasses the strong baseline in ranking accuracy on each fine-grained segment. These results indicate that our framework contributes to improving the ranking accuracy of speech quality.
PolyVoice: Language Models for Speech to Speech Translation
Jun 13, 2023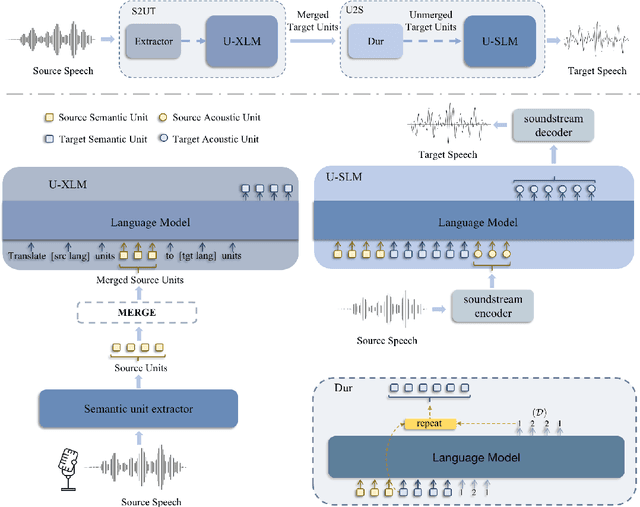

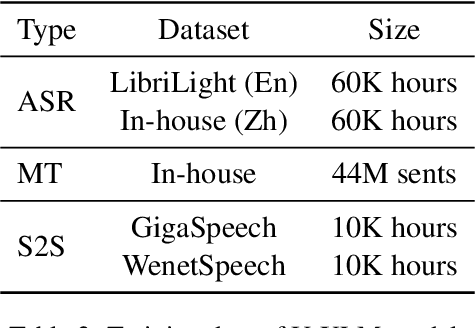
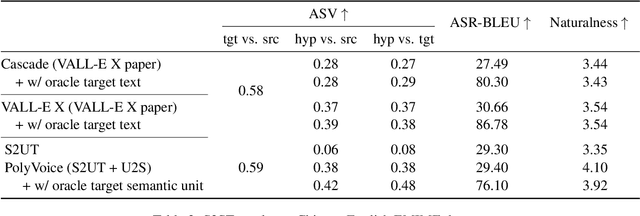
We propose PolyVoice, a language model-based framework for speech-to-speech translation (S2ST) system. Our framework consists of two language models: a translation language model and a speech synthesis language model. We use discretized speech units, which are generated in a fully unsupervised way, and thus our framework can be used for unwritten languages. For the speech synthesis part, we adopt the existing VALL-E X approach and build a unit-based audio language model. This grants our framework the ability to preserve the voice characteristics and the speaking style of the original speech. We examine our system on Chinese $\rightarrow$ English and English $\rightarrow$ Spanish pairs. Experimental results show that our system can generate speech with high translation quality and audio quality. Speech samples are available at https://speechtranslation.github.io/polyvoice.
CTC-based Non-autoregressive Speech Translation
May 27, 2023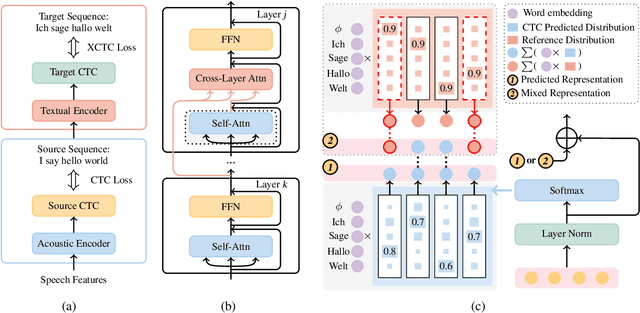
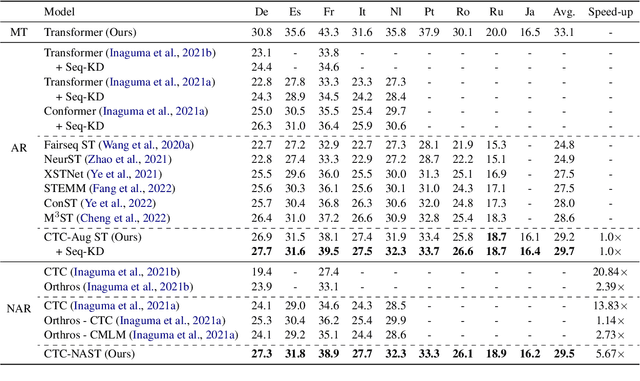
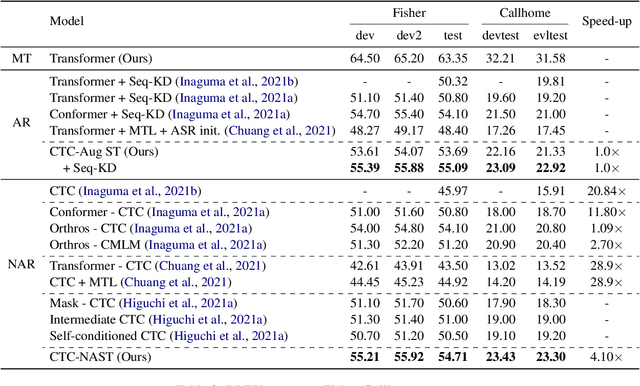
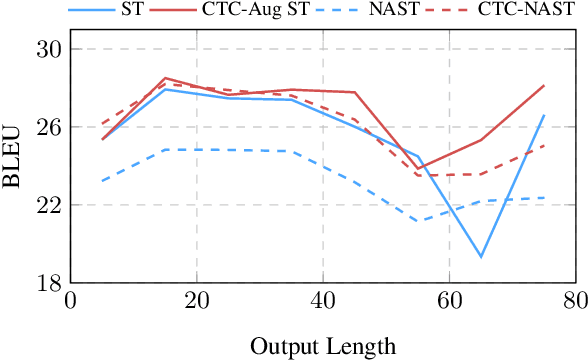
Combining end-to-end speech translation (ST) and non-autoregressive (NAR) generation is promising in language and speech processing for their advantages of less error propagation and low latency. In this paper, we investigate the potential of connectionist temporal classification (CTC) for non-autoregressive speech translation (NAST). In particular, we develop a model consisting of two encoders that are guided by CTC to predict the source and target texts, respectively. Introducing CTC into NAST on both language sides has obvious challenges: 1) the conditional independent generation somewhat breaks the interdependency among tokens, and 2) the monotonic alignment assumption in standard CTC does not hold in translation tasks. In response, we develop a prediction-aware encoding approach and a cross-layer attention approach to address these issues. We also use curriculum learning to improve convergence of training. Experiments on the MuST-C ST benchmarks show that our NAST model achieves an average BLEU score of 29.5 with a speed-up of 5.67$\times$, which is comparable to the autoregressive counterpart and even outperforms the previous best result of 0.9 BLEU points.
M3ST: Mix at Three Levels for Speech Translation
Dec 07, 2022How to solve the data scarcity problem for end-to-end speech-to-text translation (ST)? It's well known that data augmentation is an efficient method to improve performance for many tasks by enlarging the dataset. In this paper, we propose Mix at three levels for Speech Translation (M^3ST) method to increase the diversity of the augmented training corpus. Specifically, we conduct two phases of fine-tuning based on a pre-trained model using external machine translation (MT) data. In the first stage of fine-tuning, we mix the training corpus at three levels, including word level, sentence level and frame level, and fine-tune the entire model with mixed data. At the second stage of fine-tuning, we take both original speech sequences and original text sequences in parallel into the model to fine-tune the network, and use Jensen-Shannon divergence to regularize their outputs. Experiments on MuST-C speech translation benchmark and analysis show that M^3ST outperforms current strong baselines and achieves state-of-the-art results on eight directions with an average BLEU of 29.9.