 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInside the Visual Mind: Neuroscience-Motivated Concept Circuits for Interpreting and Steering Vision Transformers
Jun 04, 2026Despite high accuracy, Vision Transformer (ViT) predictions can be driven by spurious cues, raising the need to understand their inner workings before safe deployment. Sparse autoencoders (SAEs) provide a promising lens for decomposing model representations into human-interpretable concepts, yet adapting SAE-based interpretation to ViTs remains challenging due to limited control over concept coverage and subjective, non-scalable feature interpretation. To fill the gaps, motivated by neuroscience-inspired principles, we propose ViSAE, a mechanistic interpretability toolbox for understanding ViT inner workings through concept circuits. ViSAE consists of three components: (1) A probing suite with 64K images and a 16K visually grounded concept vocabulary, improving concept coverage efficiency by 20x over ImageNet and interpretation accuracy by 28.7% over existing concept sets. (2) Top-down concept reading and Bottom-up circuit tracing algorithms that automatically recover ViT inner workings via concept circuits. (3) Applications for auditing and steering ViT behavior. Through concept editing, ViSAE improves the worst-group accuracy on WaterBirds by 48.2%, outperforming existing methods by 23.8%. Our data and code: https://github.com/deep-real/ViSAE.
Interpretable Failure Detection with Human-Level Concepts
Feb 07, 2025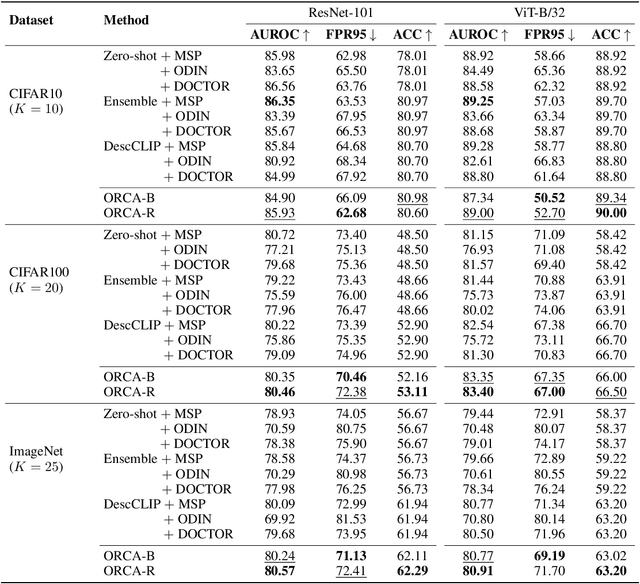
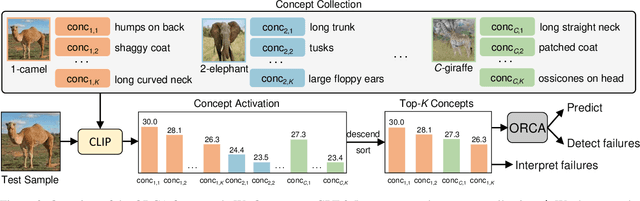
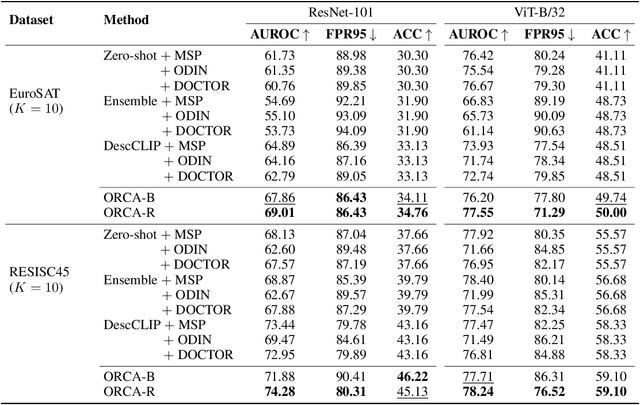
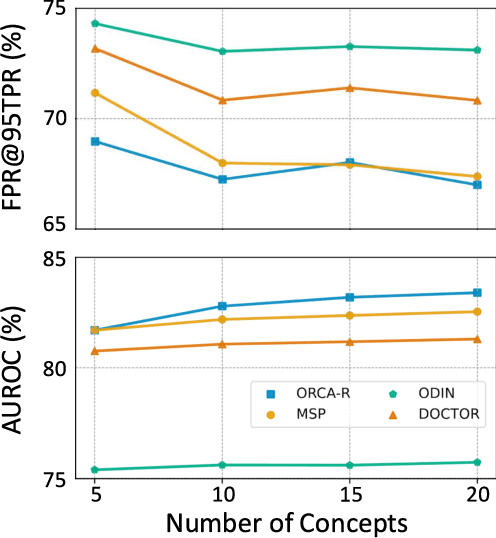
Reliable failure detection holds paramount importance in safety-critical applications. Yet, neural networks are known to produce overconfident predictions for misclassified samples. As a result, it remains a problematic matter as existing confidence score functions rely on category-level signals, the logits, to detect failures. This research introduces an innovative strategy, leveraging human-level concepts for a dual purpose: to reliably detect when a model fails and to transparently interpret why. By integrating a nuanced array of signals for each category, our method enables a finer-grained assessment of the model's confidence. We present a simple yet highly effective approach based on the ordinal ranking of concept activation to the input image. Without bells and whistles, our method significantly reduce the false positive rate across diverse real-world image classification benchmarks, specifically by 3.7% on ImageNet and 9% on EuroSAT.
Beyond Accuracy: On the Effects of Fine-tuning Towards Vision-Language Model's Prediction Rationality
Dec 17, 2024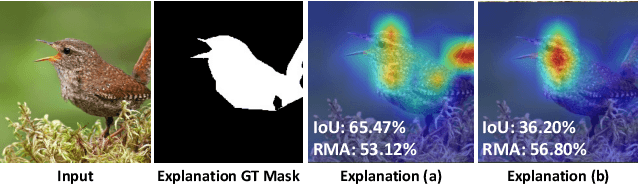
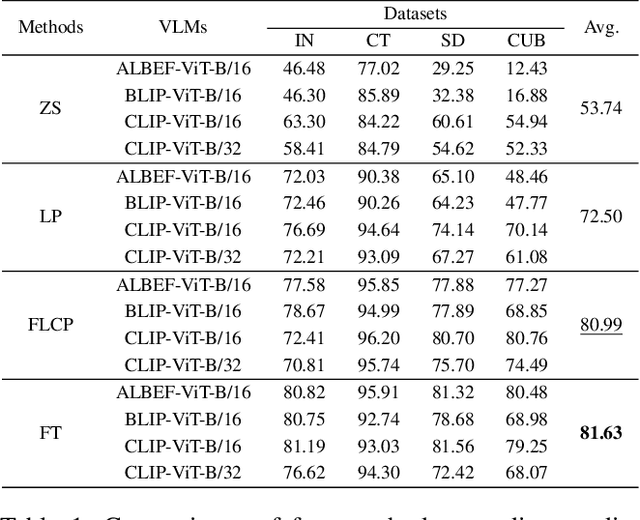

Vision-Language Models (VLMs), such as CLIP, have already seen widespread applications. Researchers actively engage in further fine-tuning VLMs in safety-critical domains. In these domains, prediction rationality is crucial: the prediction should be correct and based on valid evidence. Yet, for VLMs, the impact of fine-tuning on prediction rationality is seldomly investigated. To study this problem, we proposed two new metrics called Prediction Trustworthiness and Inference Reliability. We conducted extensive experiments on various settings and observed some interesting phenomena. On the one hand, we found that the well-adopted fine-tuning methods led to more correct predictions based on invalid evidence. This potentially undermines the trustworthiness of correct predictions from fine-tuned VLMs. On the other hand, having identified valid evidence of target objects, fine-tuned VLMs were more likely to make correct predictions. Moreover, the findings are also consistent under distributional shifts and across various experimental settings. We hope our research offer fresh insights to VLM fine-tuning.
Beyond Accuracy: Ensuring Correct Predictions With Correct Rationales
Oct 31, 2024



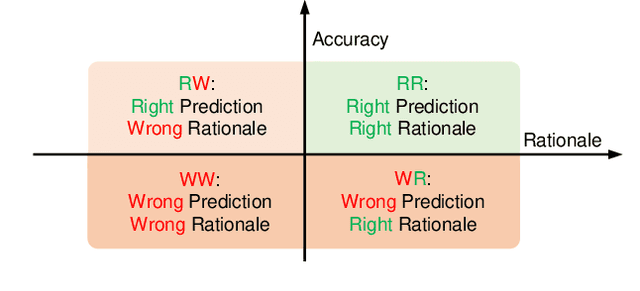
Large pretrained foundation models demonstrate exceptional performance and, in some high-stakes applications, even surpass human experts. However, most of these models are currently evaluated primarily on prediction accuracy, overlooking the validity of the rationales behind their accurate predictions. For the safe deployment of foundation models, there is a pressing need to ensure double-correct predictions, i.e., correct prediction backed by correct rationales. To achieve this, we propose a two-phase scheme: First, we curate a new dataset that offers structured rationales for visual recognition tasks. Second, we propose a rationale-informed optimization method to guide the model in disentangling and localizing visual evidence for each rationale, without requiring manual annotations. Extensive experiments and ablation studies demonstrate that our model outperforms state-of-the-art models by up to 10.1% in prediction accuracy across a wide range of tasks. Furthermore, our method significantly improves the model's rationale correctness, improving localization by 7.5% and disentanglement by 36.5%. Our dataset, source code, and pretrained weights: https://github.com/deep-real/DCP
DEAL: Disentangle and Localize Concept-level Explanations for VLMs
Jul 19, 2024



Large pre-trained Vision-Language Models (VLMs) have become ubiquitous foundational components of other models and downstream tasks. Although powerful, our empirical results reveal that such models might not be able to identify fine-grained concepts. Specifically, the explanations of VLMs with respect to fine-grained concepts are entangled and mislocalized. To address this issue, we propose to DisEntAngle and Localize (DEAL) the concept-level explanations for VLMs without human annotations. The key idea is encouraging the concept-level explanations to be distinct while maintaining consistency with category-level explanations. We conduct extensive experiments and ablation studies on a wide range of benchmark datasets and vision-language models. Our empirical results demonstrate that the proposed method significantly improves the concept-level explanations of the model in terms of disentanglability and localizability. Surprisingly, the improved explainability alleviates the model's reliance on spurious correlations, which further benefits the prediction accuracy.
Beyond the Federation: Topology-aware Federated Learning for Generalization to Unseen Clients
Jul 06, 2024Federated Learning is widely employed to tackle distributed sensitive data. Existing methods primarily focus on addressing in-federation data heterogeneity. However, we observed that they suffer from significant performance degradation when applied to unseen clients for out-of-federation (OOF) generalization. The recent attempts to address generalization to unseen clients generally struggle to scale up to large-scale distributed settings due to high communication or computation costs. Moreover, methods that scale well often demonstrate poor generalization capability. To achieve OOF-resiliency in a scalable manner, we propose Topology-aware Federated Learning (TFL) that leverages client topology - a graph representing client relationships - to effectively train robust models against OOF data. We formulate a novel optimization problem for TFL, consisting of two key modules: Client Topology Learning, which infers the client relationships in a privacy-preserving manner, and Learning on Client Topology, which leverages the learned topology to identify influential clients and harness this information into the FL optimization process to efficiently build robust models. Empirical evaluation on a variety of real-world datasets verifies TFL's superior OOF robustness and scalability.
Towards Human-Like Machine Comprehension: Few-Shot Relational Learning in Visually-Rich Documents
Mar 23, 2024



Key-value relations are prevalent in Visually-Rich Documents (VRDs), often depicted in distinct spatial regions accompanied by specific color and font styles. These non-textual cues serve as important indicators that greatly enhance human comprehension and acquisition of such relation triplets. However, current document AI approaches often fail to consider this valuable prior information related to visual and spatial features, resulting in suboptimal performance, particularly when dealing with limited examples. To address this limitation, our research focuses on few-shot relational learning, specifically targeting the extraction of key-value relation triplets in VRDs. Given the absence of a suitable dataset for this task, we introduce two new few-shot benchmarks built upon existing supervised benchmark datasets. Furthermore, we propose a variational approach that incorporates relational 2D-spatial priors and prototypical rectification techniques. This approach aims to generate relation representations that are more aware of the spatial context and unseen relation in a manner similar to human perception. Experimental results demonstrate the effectiveness of our proposed method by showcasing its ability to outperform existing methods. This study also opens up new possibilities for practical applications.
PolyVoice: Language Models for Speech to Speech Translation
Jun 13, 2023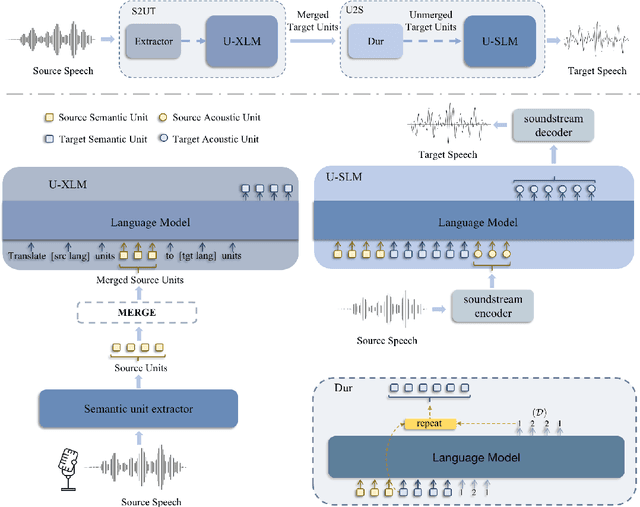

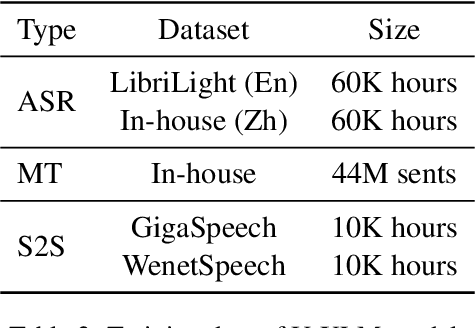
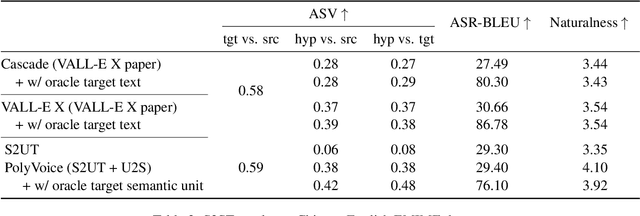
We propose PolyVoice, a language model-based framework for speech-to-speech translation (S2ST) system. Our framework consists of two language models: a translation language model and a speech synthesis language model. We use discretized speech units, which are generated in a fully unsupervised way, and thus our framework can be used for unwritten languages. For the speech synthesis part, we adopt the existing VALL-E X approach and build a unit-based audio language model. This grants our framework the ability to preserve the voice characteristics and the speaking style of the original speech. We examine our system on Chinese $\rightarrow$ English and English $\rightarrow$ Spanish pairs. Experimental results show that our system can generate speech with high translation quality and audio quality. Speech samples are available at https://speechtranslation.github.io/polyvoice.
Efficient Neural Music Generation
May 25, 2023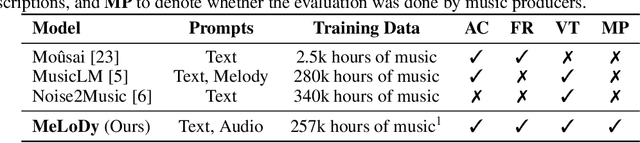
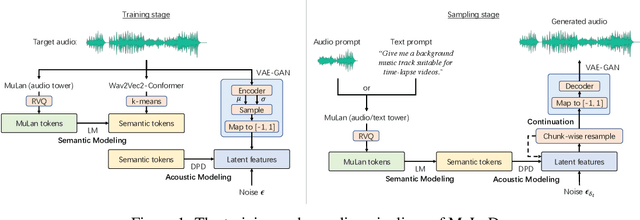
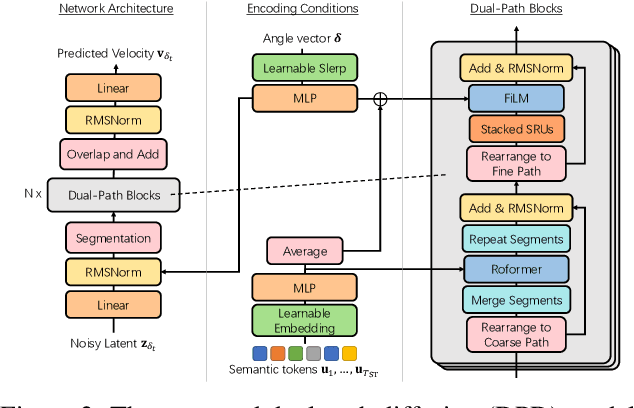

Recent progress in music generation has been remarkably advanced by the state-of-the-art MusicLM, which comprises a hierarchy of three LMs, respectively, for semantic, coarse acoustic, and fine acoustic modelings. Yet, sampling with the MusicLM requires processing through these LMs one by one to obtain the fine-grained acoustic tokens, making it computationally expensive and prohibitive for a real-time generation. Efficient music generation with a quality on par with MusicLM remains a significant challenge. In this paper, we present MeLoDy (M for music; L for LM; D for diffusion), an LM-guided diffusion model that generates music audios of state-of-the-art quality meanwhile reducing 95.7% or 99.6% forward passes in MusicLM, respectively, for sampling 10s or 30s music. MeLoDy inherits the highest-level LM from MusicLM for semantic modeling, and applies a novel dual-path diffusion (DPD) model and an audio VAE-GAN to efficiently decode the conditioning semantic tokens into waveform. DPD is proposed to simultaneously model the coarse and fine acoustics by incorporating the semantic information into segments of latents effectively via cross-attention at each denoising step. Our experimental results suggest the superiority of MeLoDy, not only in its practical advantages on sampling speed and infinitely continuable generation, but also in its state-of-the-art musicality, audio quality, and text correlation. Our samples are available at https://Efficient-MeLoDy.github.io/.
Are Data-driven Explanations Robust against Out-of-distribution Data?
Mar 29, 2023As black-box models increasingly power high-stakes applications, a variety of data-driven explanation methods have been introduced. Meanwhile, machine learning models are constantly challenged by distributional shifts. A question naturally arises: Are data-driven explanations robust against out-of-distribution data? Our empirical results show that even though predict correctly, the model might still yield unreliable explanations under distributional shifts. How to develop robust explanations against out-of-distribution data? To address this problem, we propose an end-to-end model-agnostic learning framework Distributionally Robust Explanations (DRE). The key idea is, inspired by self-supervised learning, to fully utilizes the inter-distribution information to provide supervisory signals for the learning of explanations without human annotation. Can robust explanations benefit the model's generalization capability? We conduct extensive experiments on a wide range of tasks and data types, including classification and regression on image and scientific tabular data. Our results demonstrate that the proposed method significantly improves the model's performance in terms of explanation and prediction robustness against distributional shifts.